
9 de cada 10 pymes ahora subcontratan servicios de web scraping a gran escala
Publicado: 2022-12-13La mejor manera para que las empresas aumenten sus ingresos es traer nuevas iteraciones de sus productos o servicios. Sin embargo, las masas o la base de usuarios deben ser conscientes de ello, que es donde el marketing y los anuncios son útiles. Sin embargo, tanto el desarrollo o la mejora del producto como el proceso de que su palabra llegue a las masas dependen de una cosa hoy en día: los datos. La mayoría de estos datos se obtienen mediante servicios de web scraping. Estos datos se utilizan para:
Agregar o mejorar el producto o servicio
Ya sea que venda un producto u ofrezca un servicio, debe seguir mejorándolo con el tiempo. Esto puede implicar corregir fallas anteriores, incorporar cambios recomendados por los usuarios o agregar nuevas funciones. Por ejemplo, la mayoría de los fabricantes de automóviles lanzan nuevas versiones de sus autos más vendidos cada año.
También puede desarrollar productos o herramientas adicionales que funcionen bien junto con los productos o servicios existentes. Esto lo hacen a menudo las empresas en función de las demandas y los patrones de compra observados entre los clientes. Por ejemplo, una empresa de calzado 1475 puede comenzar a vender calcetines o una empresa de atención médica puede comenzar a ofrecer paquetes de chequeos médicos anuales.
Ambas decisiones comerciales mencionadas anteriormente requieren esfuerzo en términos de tiempo y dinero. Es por esto que estudiar los datos de antemano es vital.
Mejorar el alcance de los productos.
Puede tener un gran producto o un servicio realmente útil, pero a menos que el público objetivo lo sepa, sus ingresos no crecerán. Sin datos, incluso una tonelada de gastos de marketing puede no marcar la diferencia. Los datos lo ayudarán a reconocer el conjunto de audiencia correcto: encontrar el grupo de edad objetivo, el género, la región, la ocupación y más. ¡El uso de datos para sus campañas de marketing y publicidad dará como resultado mayores conversiones a menores costos!
Las dificultades del web scraping a gran escala
El raspado de datos a gran escala tiene múltiples obstáculos. Se enfrentará a estos si intenta crear soluciones de bricolaje utilizando bibliotecas gratuitas en lenguajes como Python o herramientas basadas en la interfaz de usuario de uso gratuito. Si bien hay decenas de problemas que puede enfrentar un servicio de web scraping a gran escala en tiempo real, los más comunes son:
La velocidad de raspado puede resultar ser un factor limitante
Muchas PYMES requieren datos de una gran cantidad de fuentes, que también deben actualizarse con frecuencia. En este caso, el tiempo puede resultar vital, ya sea al extraer precios de los sitios web de la competencia o al obtener contenido de las páginas de noticias más recientes. Acelerar las cosas puede requerir que usted:
- Configure la infraestructura en la nube de la manera más eficiente.
- Escriba código de subprocesos múltiples que pueda escalar y recopilar datos de varias páginas cuando sea necesario.
Cuando extrae datos de decenas de sitios web y miles o millones de páginas web, es posible que sus trabajos de extracción se ralenticen o que los costos de la nube aumenten muy rápidamente (debido al uso ineficiente de los recursos).
Configurar la infraestructura de la nube de manera correcta y eficiente requeriría un gran porcentaje de sus esfuerzos de extracción
El web scraping a gran escala no puede ocurrir en una computadora portátil, y está obligado a usar máquinas virtuales en plataformas en la nube como Azure, GCP o AWS. Configurarlos puede ser fácil una vez que haya seguido algunos de los tutoriales. El desafío radica en:
- Mantenimiento de Infraestructura Cloud.
Mantener los costos de infraestructura en la nube bajo control. - Actualizar/cambiar la estrategia de infraestructura a medida que aumentan sus requisitos de web scraping.
- Agregar nueva infraestructura en la nube, como canalizaciones de datos, para encargarse de operaciones como limpieza de datos, almacenamiento, disputas y más a medida que crece su negocio.
Se deben tener en cuenta las implicaciones legales del web scraping
Antes de rastrear un sitio web, es importante

- Compruebe su archivo robot.txt.
- Verifique que cumple con las leyes de datos y seguridad del país del sitio web, el país donde se originan los datos del sitio web y el país donde podría estar utilizando los datos con fines comerciales.
Con las crecientes regulaciones sobre datos y privacidad y leyes como el RGPD en Europa o la CCPA en California, adherirse al punto b mencionado anteriormente puede ser muy complicado cuando se trata de datos extraídos de múltiples fuentes. Al crear soluciones de bricolaje, es posible que no sea posible cumplir al 100 % con todas las leyes. Aunque el raspado a pequeña escala con fines de investigación puede no causar ningún daño, el raspado web a gran escala sin cumplir con las leyes de datos puede causar muchos problemas. Las empresas han sido demandadas por millones de dólares por no cumplir con las leyes correctas de extracción, uso o almacenamiento de datos en el pasado.
Los sitios web tienen muchos trucos bajo la manga para mantener alejados a los raspadores
Realizan un seguimiento del tráfico y, a menos que utilice la rotación de proxy, los sitios web podrían bloquearlo fácilmente. Otra amenaza que plantean los sitios web son los cambios frecuentes en la interfaz de usuario que pueden hacer que su código existente sea inútil. Esto requeriría volver a estudiar su formato de página HTML y volver a escribir el código para obtener todos los puntos de datos. Del mismo modo, agregar nuevos sitios web también puede resultar una tarea hercúlea incluso si está raspando los mismos puntos de datos. La dificultad dependerá de la complejidad del sitio web y de si utiliza la última tecnología. Este factor desconocido siempre permanecería al agregar nuevos sitios web a las soluciones de raspado de bricolaje.
Los beneficios de usar un proveedor de DaaS como PromptCloud
Solo hemos discutido las herramientas y soluciones gratuitas y los problemas que pueden plantear cuando se usan en web scraping a gran escala. Las herramientas y soluciones pagas pueden resolver muchos o la mayoría de estos problemas, pero no todos. La razón detrás de esto es simple: ninguna talla puede servir para todos. Aquí es donde los proveedores de servicios de web scraping entran en escena. PromptCloud es un proveedor líder de DaaS que resuelve todos los problemas mencionados anteriormente. También ofrecemos más funciones y personalizaciones que hacen que el web scraping sea muy sencillo.
El principal beneficio que ofrece PromptCloud es la personalización infinita
Extraiga 1000 páginas de 10 sitios web, guarde los datos en AWS S3 o hágalos accesibles a través de API, actualice los datos todos los días o extraiga un millón de páginas cada hora y obtenga los datos en su Dropbox: PromptCloud ofrece una solución diferente altamente personalizada para cada PYME que se acerca a nosotros para que pueda olvidarse de las dificultades del web scraping y centrarse en su core business.
Uno de los aspectos principales del web scraping es el costo involucrado
Como un verdadero servicio basado en la nube, cobramos solo por lo que usa. Entonces, si raspa menos páginas este mes que el mes pasado, o actualiza sus datos con menos frecuencia, sus costos disminuirán.
Ofrecemos un servicio basado en la nube completamente administrado con latencia mínima junto con SLA sólidos y soporte a pedido
Esto garantiza que no tenga que preocuparse por los esfuerzos de raspado web y puede comenzar con la integración de los puntos de datos raspados en su flujo de trabajo (ofrecemos múltiples opciones de integración basadas en la nube). En caso de que las cosas salgan mal, como si un sitio web cambia su interfaz de usuario o se detiene el scraping para un sitio web en particular, nuestras herramientas de seguimiento y monitoreo se activan de inmediato para localizar el problema específico del que luego se encargan nuestros equipos internos. Los SLA y el soporte a pedido también brindan un respiro adicional a los clientes, ya que entendemos cuán vitales pueden ser los datos para las PYME.
Raspado de datos simplificado
Una de las principales razones por las que PromptCloud es un proveedor líder de servicios de web scraping es que hemos abstraído todo el acto de web scraping y lo hemos reducido a unas pocas etapas simples, como se muestra en el siguiente diagrama de flujo.
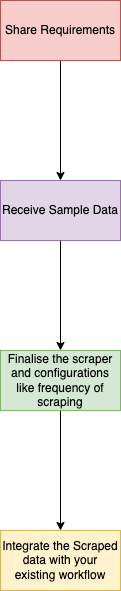
Fig: Raspado de datos usando PromptCloud
Este proceso de 4 pasos puede implicar varias iteraciones del paso 2 o el paso 3, y solo finalizaríamos el raspador una vez que nuestro cliente esté completamente satisfecho con el aspecto de los datos raspados y haya validado los datos de muestra.
Hemos recopilado datos para sectores como–
- comercio electrónico y venta al por menor
- viajes y hoteles
- Empleos y Reclutamiento
- Investigar
- Bienes raíces
- Automóvil
- Finanzas
Esta variada experiencia y años de investigación en diferentes tipos de sitios web nos ayudan a realizar trabajos de scraping para cualquier sitio web, tanto simple como complejo.
Los servicios de raspado web y los proveedores de servicios están hoy en Internet y muchos de ellos hablan de automatización y raspado web automatizado. Sin embargo, la verdad es que el web scraping significa sumergirse en los datos y ensuciarse las manos. La automatización funciona, pero solo hasta cierto punto. Debe manejar cambios en el sitio web, bloqueos, problemas legales, nuevas incorporaciones, nuevas pilas de tecnología y más, todo lo cual debe ser manejado por un equipo experimentado.
Esta es la razón por la que nuestros socios, desde nuevas empresas hasta compañías Fortune 500, confían en nosotros y en nuestras técnicas de extracción de datos. Nuestro equipo brinda soluciones personalizadas para cada empresa que necesita aprovechar los datos para crecer y mantenerse por delante de la competencia. En el mundo actual, donde los datos que quedan sobre la mesa eventualmente serán recogidos por otros en la carrera, debe asegurarse de que su juego de datos esté configurado, para lo cual puede confiar en PromptCloud.