
Técnicas avanzadas para mejorar el rendimiento de LLM
Publicado: 2024-04-02En el vertiginoso mundo de la tecnología, los modelos de lenguaje grande (LLM) se han convertido en actores clave en la forma en que interactuamos con la información digital. Estas poderosas herramientas pueden escribir artículos, responder preguntas e incluso mantener conversaciones, pero no están exentas de desafíos. A medida que exigimos más a estos modelos, nos topamos con obstáculos, especialmente cuando se trata de hacerlos funcionar más rápido y más eficientemente. Este blog trata sobre cómo afrontar esos obstáculos de frente.
Nos sumergimos en algunas estrategias inteligentes diseñadas para aumentar la velocidad a la que operan estos modelos, sin perder la calidad de su producción. Imagínese tratar de mejorar la velocidad de un auto de carreras y al mismo tiempo garantizar que pueda recorrer curvas cerradas sin problemas; eso es lo que buscamos con los modelos de lenguaje grandes. Analizaremos métodos como el procesamiento por lotes continuo, que ayuda a procesar la información de manera más fluida, y enfoques innovadores como Paged y Flash Attention, que hacen que los LLM sean más atentos y más rápidos en su razonamiento digital.
Entonces, si tienes curiosidad por superar los límites de lo que estos gigantes de la IA pueden hacer, estás en el lugar correcto. Exploremos juntos cómo estas técnicas avanzadas están dando forma al futuro de los LLM, haciéndolos más rápidos y mejores que nunca.
Desafíos para lograr un mayor rendimiento para los LLM
Lograr un mayor rendimiento en modelos de lenguajes grandes (LLM) enfrenta varios desafíos importantes, cada uno de los cuales actúa como un obstáculo para la velocidad y eficiencia con la que estos modelos pueden operar. Un obstáculo principal es el simple requisito de memoria necesario para procesar y almacenar las grandes cantidades de datos con las que trabajan estos modelos. A medida que los LLM crecen en complejidad y tamaño, la demanda de recursos computacionales se intensifica, lo que dificulta mantener, y mucho menos mejorar, las velocidades de procesamiento.
Otro desafío importante es la naturaleza autorregresiva de los LLM, especialmente en los modelos utilizados para generar texto. Esto significa que el resultado de cada paso depende de los anteriores, lo que crea un requisito de procesamiento secuencial que inherentemente limita la rapidez con la que se pueden ejecutar las tareas. Esta dependencia secuencial a menudo resulta en un cuello de botella, ya que cada paso debe esperar a que se complete su predecesor antes de poder continuar, lo que obstaculiza los esfuerzos por lograr un mayor rendimiento.
Además, el equilibrio entre precisión y velocidad es delicado. Mejorar el rendimiento sin comprometer la calidad del resultado es un camino sobre la cuerda floja que requiere soluciones innovadoras que puedan navegar por el complejo panorama de la eficiencia computacional y la efectividad del modelo.
Estos desafíos forman el telón de fondo en el que se realizan avances en la optimización de LLM, ampliando los límites de lo que es posible en el ámbito del procesamiento del lenguaje natural y más allá.
Requisito de memoria
La fase de decodificación genera un único token en cada paso de tiempo, pero cada token depende de los tensores de clave y valor de todos los tokens anteriores (incluidos los tensores KV de los tokens de entrada calculados en el prellenado y cualquier tensor KV nuevo calculado hasta el paso de tiempo actual). .
Por lo tanto, para minimizar los cálculos redundantes cada vez y evitar volver a calcular todos estos tensores para todos los tokens en cada paso de tiempo, es posible almacenarlos en caché en la memoria de la GPU. En cada iteración, cuando se calculan nuevos elementos, simplemente se agregan al caché en ejecución para usarse en la siguiente iteración. Esto se conoce esencialmente como caché KV.
Esto reduce en gran medida el cálculo necesario, pero introduce un requisito de memoria junto con requisitos de memoria ya mayores para modelos de lenguajes grandes, lo que dificulta la ejecución en GPU básicas. Con el aumento del tamaño de los parámetros del modelo (7B a 33B) y la mayor precisión (fp16 a fp32), los requisitos de memoria también aumentan. Veamos un ejemplo de la capacidad de memoria requerida,
Como sabemos, los dos principales ocupantes de la memoria son
- Pesos propios del modelo en memoria, este viene con no. de parámetros como 7B y tipo de datos de cada parámetro, por ejemplo, 7B en fp16 (2 bytes) ~= 14 GB en memoria
- Caché KV: el caché utilizado para el valor clave de la etapa de autoatención para evitar cálculos redundantes.
Tamaño de la caché KV por token en bytes = 2 * (num_layers) * (hidden_size) * precision_in_bytes
El primer factor 2 representa las matrices K y V. Estos Hidden_size y dim_head se pueden obtener de la tarjeta del modelo o del archivo de configuración.
La fórmula anterior es por token, por lo que para una secuencia de entrada, será seq_len * size_of_kv_per_token. Entonces la fórmula anterior se transformará en,
Tamaño total de la caché KV en bytes = (longitud_secuencia) * 2 * (núm_capas) * (tamaño_oculto) * precisión_en_bytes
Por ejemplo, con LLAMA 2 en fp16, el tamaño será (4096) * 2 * (32) * (4096) * 2, que es ~2 GB.
Lo anterior es para una sola entrada, con múltiples entradas esto crece rápidamente, esta asignación y administración de memoria en vuelo se convierte en un paso crucial para lograr un rendimiento óptimo, si no resulta en problemas de falta de memoria y fragmentación.
A veces, el requisito de memoria es mayor que la capacidad de nuestra GPU; en esos casos, debemos analizar el paralelismo del modelo, el paralelismo tensorial que no se trata aquí pero que se puede explorar en esa dirección.
Operación autorregresiva y ligada a la memoria
Como podemos ver, la parte de generación de resultados de los modelos de lenguaje grandes es de naturaleza autorregresiva. Indica que para que se genere cualquier token nuevo, depende de todos los tokens anteriores y sus estados intermedios. Dado que en la etapa de salida no todos los tokens están disponibles para realizar cálculos adicionales, y solo tiene un vector (para el siguiente token) y el bloque de la etapa anterior, esto se convierte en una operación de matriz-vector que infrautiliza la capacidad de cálculo de la GPU cuando en comparación con la fase de precarga. La velocidad a la que los datos (pesos, claves, valores, activaciones) se transfieren a la GPU desde la memoria domina la latencia, no la rapidez con la que realmente se realizan los cálculos. En otras palabras, se trata de una operación vinculada a la memoria .
Soluciones innovadoras para superar los desafíos de rendimiento
Dosificación continua
El paso muy simple para reducir la naturaleza ligada a la memoria de la etapa de decodificación es agrupar la entrada y realizar cálculos para múltiples entradas a la vez. Pero un simple procesamiento por lotes constante ha dado como resultado un rendimiento deficiente debido a la naturaleza de las diferentes longitudes de secuencia que se generan y aquí la latencia de un lote depende de la secuencia más larga que se genera en un lote y también con un requisito de memoria creciente ya que se necesitan múltiples entradas. ahora procesado de una vez.
Por lo tanto, el procesamiento por lotes estático simple es ineficaz y surge el procesamiento por lotes continuo. Su esencia radica en agregar dinámicamente lotes de solicitudes entrantes, adaptarse a tasas de llegada fluctuantes y explotar oportunidades de procesamiento paralelo siempre que sea posible. Esto también optimiza la utilización de la memoria al agrupar secuencias de longitudes similares en cada lote, lo que minimiza la cantidad de relleno necesario para secuencias más cortas y evita el desperdicio de recursos computacionales en un relleno excesivo.

Ajusta de forma adaptativa el tamaño del lote en función de factores como la capacidad de memoria actual, los recursos computacionales y la longitud de la secuencia de entrada. Esto garantiza que el modelo funcione de manera óptima en condiciones variables sin exceder las limitaciones de memoria. Esto, como ayuda con la atención paginada (que se explica a continuación), ayuda a reducir la latencia y aumentar el rendimiento.
Lea más: Cómo el procesamiento por lotes continuo permite un rendimiento 23 veces mayor en la inferencia LLM y al mismo tiempo reduce la latencia p50
Atención paginada
A medida que realizamos procesamiento por lotes para mejorar el rendimiento, esto también tiene el costo de un mayor requisito de memoria caché KV, ya que ahora estamos procesando múltiples entradas a la vez. Estas secuencias pueden exceder la capacidad de memoria de los recursos computacionales disponibles, lo que hace poco práctico procesarlas en su totalidad.
También se observa que la asignación ingenua de memoria de la caché KV da como resultado una gran fragmentación de la memoria, tal como observamos en los sistemas informáticos debido a la asignación desigual de la memoria. vLLM presentó Paged Attention, que es una técnica de administración de memoria inspirada en los conceptos de paginación y memoria virtual del sistema operativo para manejar de manera eficiente el creciente requisito de caché KV.
La atención paginada aborda las limitaciones de memoria dividiendo el mecanismo de atención en páginas o segmentos más pequeños, cada uno de los cuales cubre un subconjunto de la secuencia de entrada. En lugar de calcular puntuaciones de atención para toda la secuencia de entrada a la vez, el modelo se centra en una página a la vez y la procesa secuencialmente.
Durante la inferencia o el entrenamiento, el modelo recorre cada página de la secuencia de entrada, calcula las puntuaciones de atención y genera resultados en consecuencia. Una vez que se procesa una página, sus resultados se almacenan y el modelo pasa a la página siguiente.
Al dividir el mecanismo de atención en páginas, Paged Attention permite que el modelo de lenguaje grande maneje secuencias de entrada de longitud arbitraria sin exceder las limitaciones de memoria. Reduce eficazmente la huella de memoria necesaria para procesar secuencias largas, lo que hace posible trabajar con documentos y lotes grandes.
Lectura adicional: Servicio rápido de LLM con vLLM y PagedAttention
Atención flash
Como el mecanismo de atención es crucial para los modelos transformadores en los que se basan los modelos de lenguaje grande, ayuda al modelo a centrarse en partes relevantes del texto de entrada al hacer predicciones. Sin embargo, a medida que los modelos basados en transformadores se vuelven más grandes y complejos, el mecanismo de autoatención se vuelve cada vez más lento y consume mucha memoria, lo que genera un problema de cuello de botella en la memoria, como se mencionó anteriormente. Flash Attention es otra técnica de optimización que tiene como objetivo mitigar este problema optimizando las operaciones de atención, lo que permite un entrenamiento e inferencia más rápidos.
Características clave de Flash Atención:
Kernel Fusion: es importante no solo maximizar el uso de cómputo de la GPU, sino también lograr que las operaciones sean lo más eficientes posibles. Flash Attention combina múltiples pasos de cálculo en una sola operación, lo que reduce la necesidad de transferencias de datos repetitivas. Este enfoque simplificado simplifica el proceso de implementación y mejora la eficiencia computacional.
Mosaico: Flash Attention divide los datos cargados en bloques más pequeños, lo que ayuda al procesamiento paralelo. Esta estrategia optimiza el uso de la memoria, lo que permite soluciones escalables para modelos con tamaños de entrada más grandes.
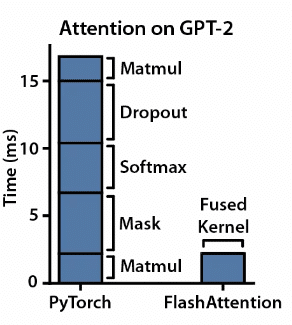
(Núcleo CUDA fusionado que muestra cómo el mosaico y la fusión reducen el tiempo necesario para el cálculo. Fuente de la imagen: FlashAttention: atención exacta rápida y eficiente en memoria con IO-Awareness)
Optimización de la memoria: Flash Attention carga parámetros solo para los últimos tokens, reutilizando activaciones de tokens calculados recientemente. Este enfoque de ventana deslizante reduce la cantidad de solicitudes de E/S para cargar pesos y maximiza el rendimiento de la memoria flash.
Transferencias de datos reducidas: Flash Attention minimiza las transferencias de datos de ida y vuelta entre tipos de memoria, como la memoria de alto ancho de banda (HBM) y SRAM (memoria estática de acceso aleatorio). Al cargar todos los datos (consultas, claves y valores) solo una vez, se reduce la sobrecarga de las transferencias de datos repetitivas.
Estudio de caso: optimización de la inferencia con decodificación especulativa
Otro método empleado para acelerar la generación de texto en un modelo de lenguaje autorregresivo es la decodificación especulativa. El principal objetivo de la decodificación especulativa es acelerar la generación de texto preservando al mismo tiempo la calidad del texto generado a un nivel comparable al de la distribución de destino.
La decodificación especulativa introduce un modelo pequeño/borrador que predice los tokens posteriores en la secuencia, que luego son aceptados/rechazados por el modelo principal según criterios predefinidos. La integración de un modelo borrador más pequeño con el modelo de destino mejora significativamente la velocidad de generación de texto, esto se debe a la naturaleza del requisito de memoria. Dado que el borrador del modelo es pequeño, no requiere menos. de pesos de neuronas que se cargarán y el no. La capacidad de cálculo también es menor ahora en comparación con el modelo principal, lo que reduce la latencia y acelera el proceso de generación de resultados. Luego, el modelo principal evalúa los resultados que se generan y garantiza que se ajusten a la distribución objetivo del siguiente token probable.
En esencia, la decodificación especulativa agiliza el proceso de generación de texto al aprovechar un modelo borrador más pequeño y más rápido para predecir los tokens posteriores, acelerando así la velocidad general de generación de texto y manteniendo la calidad del contenido generado cerca de la distribución objetivo.
Es muy importante que los tokens generados por modelos más pequeños no siempre sean rechazados constantemente, este caso conduce a una disminución del rendimiento en lugar de una mejora. A través de experimentos y la naturaleza de los casos de uso, podemos seleccionar un modelo más pequeño/introducir decodificación especulativa en el proceso de inferencia.
Conclusión
El viaje a través de las técnicas avanzadas para mejorar el rendimiento del modelo de lenguaje grande (LLM) ilumina un camino a seguir en el ámbito del procesamiento del lenguaje natural, mostrando no solo los desafíos sino también las soluciones innovadoras que pueden enfrentarlos de frente. Estas técnicas, desde el procesamiento por lotes continuo hasta la atención paginada y flash, y el intrigante enfoque de la decodificación especulativa, son más que simples mejoras incrementales. Representan avances significativos en nuestra capacidad para hacer que los modelos de lenguaje grandes sean más rápidos, más eficientes y, en última instancia, más accesibles para una amplia gama de aplicaciones.
No se puede subestimar la importancia de estos avances. Al optimizar el rendimiento de LLM y mejorar el rendimiento, no solo estamos ajustando los motores de estos potentes modelos; Estamos redefiniendo lo que es posible en términos de velocidad y eficiencia de procesamiento. Esto, a su vez, abre nuevos horizontes para la aplicación de grandes modelos lingüísticos, desde servicios de traducción de idiomas en tiempo real que pueden funcionar a la velocidad de una conversación, hasta herramientas analíticas avanzadas capaces de procesar grandes conjuntos de datos a una velocidad sin precedentes.
Además, estas técnicas subrayan la importancia de un enfoque equilibrado para la optimización de modelos de lenguaje grandes, uno que considere cuidadosamente la interacción entre velocidad, precisión y recursos computacionales. A medida que ampliamos los límites de las capacidades de LLM, mantener este equilibrio será crucial para garantizar que estos modelos puedan seguir sirviendo como herramientas versátiles y confiables en una gran variedad de industrias.
Las técnicas avanzadas para mejorar el rendimiento de los modelos de lenguaje grandes son más que simples logros técnicos; son hitos en la evolución continua de la inteligencia artificial. Prometen hacer que los LLM sean más adaptables, más eficientes y más poderosos, allanando el camino para futuras innovaciones que continuarán transformando nuestro panorama digital.
Lea más sobre la arquitectura GPU para la optimización de inferencia de modelos de lenguaje grandes en nuestra reciente publicación de blog