
Mejores prácticas y casos de uso para extraer datos del sitio web
Publicado: 2023-12-28Al extraer datos de un sitio web, es esencial respetar las regulaciones y el marco del sitio de destino. Adherirse a las mejores prácticas no es sólo una cuestión de ética, sino que también sirve para evitar complicaciones legales y garantizar la confiabilidad de la extracción de datos. Aquí hay consideraciones clave:
- Adhiérase a robots.txt : compruebe siempre este archivo primero para comprender qué es lo que el propietario del sitio ha establecido como prohibido para el scraping.
- Utilice API : si está disponible, utilice la API oficial del sitio, que es un método más estable y aprobado para acceder a los datos.
- Tenga en cuenta las tasas de solicitudes : la extracción excesiva de datos puede sobrecargar los servidores del sitio web, así que controle sus solicitudes de manera considerada.
- Identifíquese : a través de su cadena de agente de usuario, sea transparente sobre su identidad y propósito al realizar el scraping.
- Maneje los datos de manera responsable : almacene y use los datos recopilados de acuerdo con las leyes de privacidad y las regulaciones de protección de datos.
Seguir estas prácticas garantiza el scraping ético, manteniendo la integridad y disponibilidad del contenido en línea.
Comprender el marco legal
Al extraer datos de un sitio web, es fundamental navegar por las restricciones legales entrelazadas. Los textos legislativos clave incluyen:
- La Ley de Abuso y Fraude Informático (CFAA): Legislación en los Estados Unidos hace que sea ilegal acceder a una computadora sin la autorización adecuada.
- Reglamento general de protección de datos de la Unión Europea (GDPR) : exige el consentimiento para el uso de datos personales y otorga a las personas control sobre sus datos.
- La Ley de Derechos de Autor del Milenio Digital (DMCA) : protege contra la distribución de contenido protegido por derechos de autor sin permiso.
Los scrapers también deben respetar los acuerdos de "condiciones de uso" de los sitios web, que a menudo limitan la extracción de datos. Garantizar el cumplimiento de estas leyes y políticas es esencial para eliminar de forma ética y legal los datos de los sitios web.
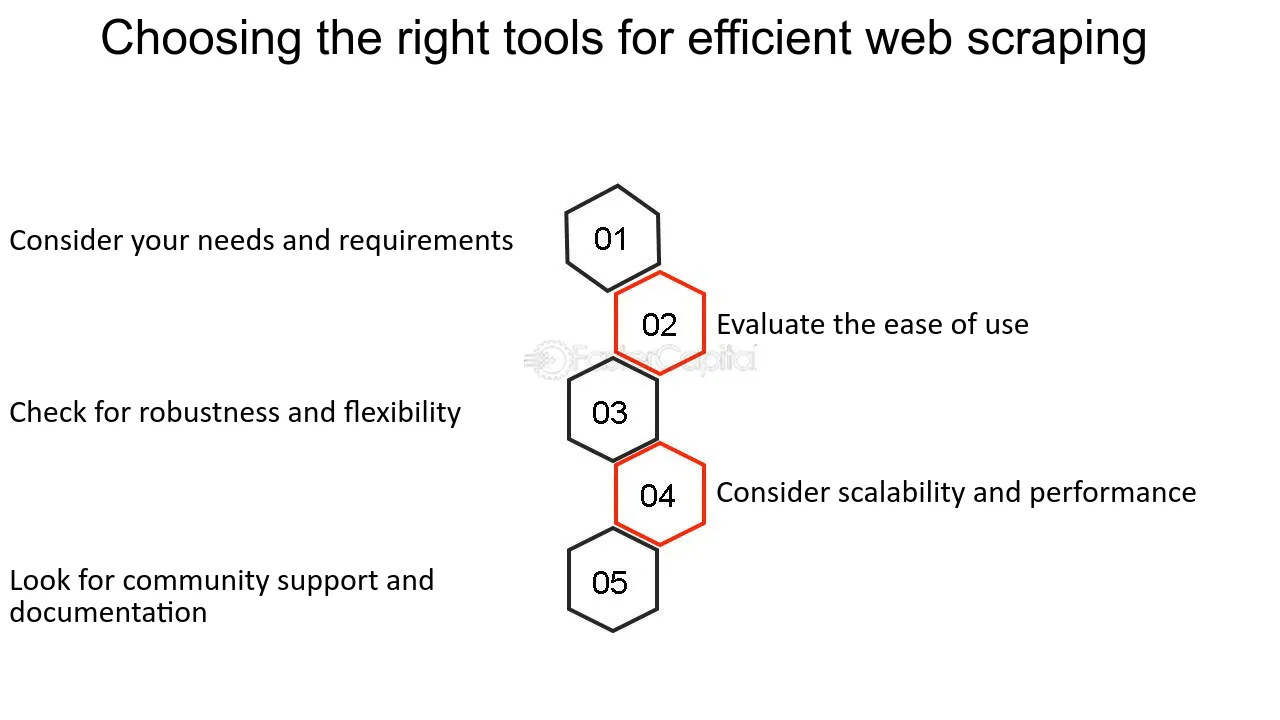
Seleccionar las herramientas adecuadas para raspar
Elegir las herramientas correctas es crucial al iniciar un proyecto de web scraping. Los factores a considerar incluyen:
- Complejidad del sitio web : los sitios dinámicos pueden requerir herramientas como Selenium que puedan interactuar con JavaScript.
- Cantidad de datos : para el scraping a gran escala, se recomiendan herramientas con capacidades de scraping distribuido como Scrapy.
- Legalidad y ética : seleccione herramientas con funciones para respetar robots.txt y establecer cadenas de agentes de usuario.
- Facilidad de uso : los principiantes pueden preferir las interfaces fáciles de usar que se encuentran en software como Octoparse.
- Conocimientos de programación : los no programadores pueden inclinarse por el software con una GUI, mientras que los programadores pueden optar por bibliotecas como BeautifulSoup.
Fuente de la imagen: https://fastercapital.com/
Mejores prácticas para extraer datos de un sitio web de forma eficaz
Para extraer datos del sitio web de manera eficiente y responsable, siga estas pautas:
- Respete los archivos robots.txt y los términos del sitio web para evitar problemas legales.
- Utilice encabezados y rote los agentes de usuario para imitar el comportamiento humano.
- Implemente un retraso entre solicitudes para reducir la carga del servidor.
- Utilice proxies para evitar prohibiciones de propiedad intelectual.
- Raspe durante las horas de menor actividad para minimizar la interrupción del sitio web.
- Almacene siempre los datos de manera eficiente, evitando entradas duplicadas.
- Garantice la precisión de los datos extraídos con comprobaciones periódicas.
- Tenga en cuenta las leyes de privacidad de datos al almacenar y utilizar datos.
- Mantenga sus herramientas de scraping actualizadas para manejar los cambios del sitio web.
- Esté siempre preparado para adaptar las estrategias de scraping si los sitios web actualizan su estructura.
Casos de uso de extracción de datos en todas las industrias
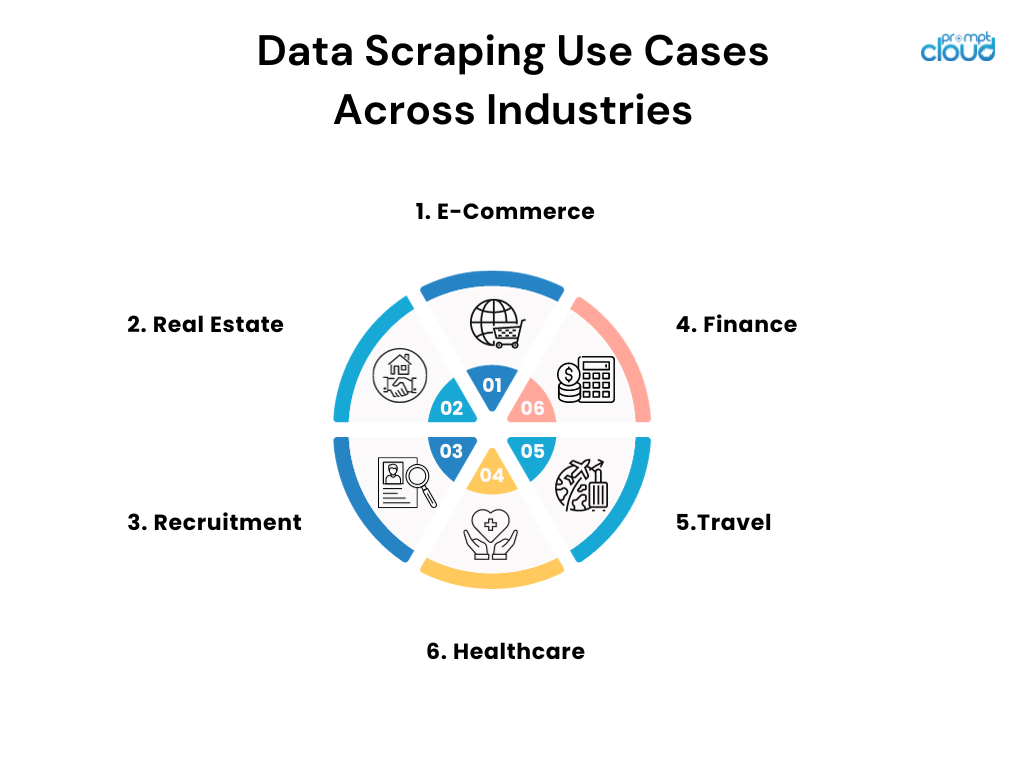
- Comercio electrónico: los minoristas en línea implementan el scraping para monitorear los precios de la competencia y ajustar sus estrategias de precios en consecuencia.
- Bienes raíces: agentes y empresas recopilan listados para agregar información sobre propiedades, tendencias y datos de precios de diversas fuentes.
- Reclutamiento: las empresas buscan en bolsas de trabajo y redes sociales para encontrar candidatos potenciales y analizar las tendencias del mercado laboral.
- Finanzas: los analistas recopilan registros públicos y documentos financieros para informar estrategias de inversión y rastrear los sentimientos del mercado.
- Viajes: las agencias reducen los precios de las aerolíneas y los hoteles para ofrecer a los clientes las mejores ofertas y paquetes posibles.
- Atención médica: los investigadores consultan bases de datos y revistas médicas para mantenerse actualizados sobre los últimos hallazgos y ensayos clínicos.
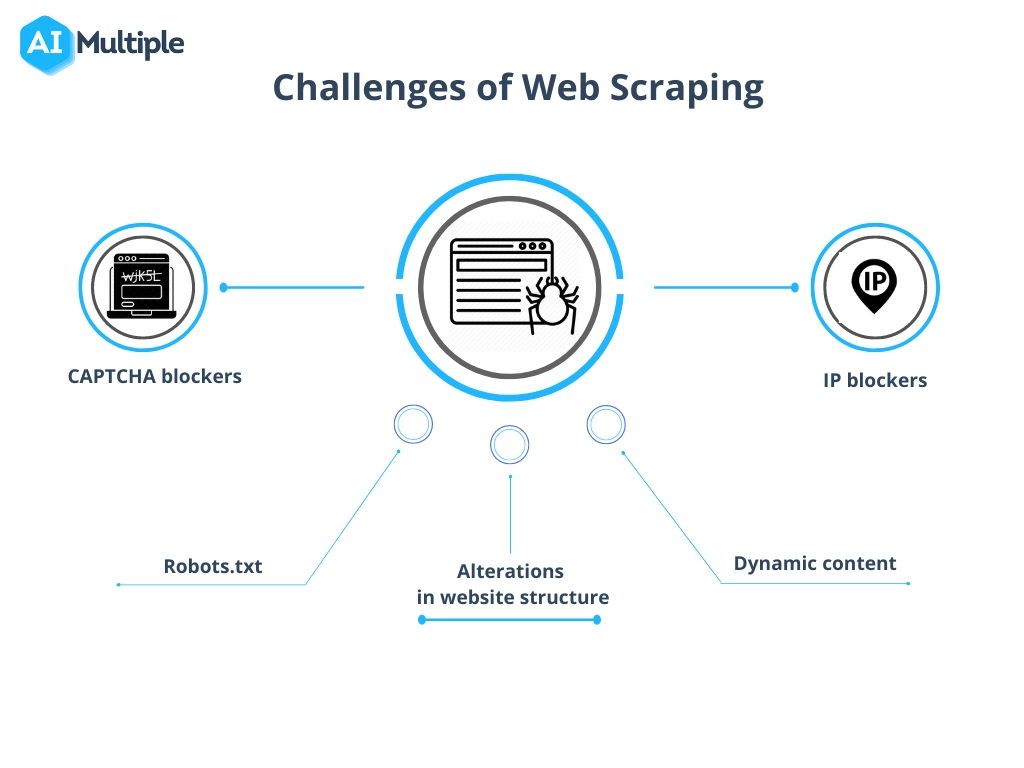
Abordar los desafíos comunes en el raspado de datos
El proceso de extracción de datos de un sitio web, aunque es inmensamente valioso, con frecuencia implica superar obstáculos como alteraciones en la estructura del sitio web, medidas anti-scraping y preocupaciones con respecto a la calidad de los datos.

Fuente de la imagen: https://research.aimultiple.com/
Para navegar por estos de manera efectiva:
- Manténgase adaptable : actualice periódicamente los scripts de scraping para que coincidan con las actualizaciones del sitio web. El uso del aprendizaje automático puede ayudar a adaptarse dinámicamente a los cambios estructurales.
- Respete los límites legales : comprenda y cumpla con las legalidades del scraping para evitar litigios. Asegúrese de revisar el archivo robots.txt y los términos de servicio de un sitio web.
- Parte superior de la forma
- Imitar la interacción humana : los sitios web pueden bloquear los raspadores que envían solicitudes demasiado rápido. Implemente retrasos e intervalos aleatorios entre solicitudes para que parezcan menos robóticos.
- Manejar CAPTCHA : Hay herramientas y servicios disponibles que pueden resolver o eludir CAPTCHA, aunque su uso debe considerarse en contra de las implicaciones éticas y legales.
- Mantenga la integridad de los datos : garantice la precisión de los datos extraídos. Valide los datos periódicamente y límpielos para mantener la calidad y la utilidad.
Estas estrategias ayudan a superar los obstáculos comunes del scraping y facilitan la extracción de datos valiosos.
Conclusión
La extracción eficiente de datos de sitios web es un método valioso con diversas aplicaciones, que van desde la investigación de mercado hasta el análisis competitivo. Es esencial cumplir con las mejores prácticas, garantizar la legalidad, respetar las pautas de robots.txt y controlar cuidadosamente la frecuencia del scraping para evitar la sobrecarga del servidor.
La aplicación responsable de estos métodos abre la puerta a ricas fuentes de datos que pueden proporcionar información útil e impulsar la toma de decisiones informadas tanto para empresas como para individuos. Una implementación adecuada, junto con consideraciones éticas, garantiza que la extracción de datos siga siendo una herramienta poderosa dentro del panorama digital.
¿Listo para potenciar sus conocimientos extrayendo datos del sitio web? ¡No busque más! PromptCloud ofrece servicios de web scraping éticos y confiables adaptados a sus necesidades. Conéctese con nosotros en sales@promptcloud.com para transformar datos sin procesar en inteligencia procesable. ¡Mejoremos juntos su toma de decisiones!
Preguntas frecuentes
¿Es aceptable extraer datos de sitios web?
Por supuesto, la extracción de datos está bien, pero hay que seguir las reglas. Antes de sumergirse en cualquier aventura de scraping, eche un vistazo a los términos de servicio y al archivo robots.txt del sitio web en cuestión. Mostrar cierto respeto por el diseño del sitio web, ceñirse a los límites de frecuencia y mantener las cosas éticas son claves para realizar prácticas responsables de extracción de datos.
¿Cómo puedo extraer datos de usuario de un sitio web mediante scraping?
La extracción de datos de usuario mediante scraping requiere un enfoque meticuloso alineado con las normas legales y éticas. Siempre que sea posible, se recomienda aprovechar las API disponibles públicamente proporcionadas por el sitio web para la recuperación de datos. En ausencia de una API, es imperativo garantizar que los métodos de raspado empleados cumplan con las leyes de privacidad, los términos de uso y las políticas establecidas por el sitio web para mitigar posibles ramificaciones legales.
¿Se considera ilegal extraer datos de sitios web?
La legalidad del web scraping depende de varios factores, incluido el propósito, la metodología y el cumplimiento de las leyes pertinentes. Si bien el web scraping en sí no es inherentemente ilegal, el acceso no autorizado, la violación de los términos de servicio de un sitio web o el incumplimiento de las leyes de privacidad pueden tener consecuencias legales. La conducta responsable y ética en las actividades de web scraping es primordial, lo que implica una gran conciencia de los límites legales y las consideraciones éticas.
¿Pueden los sitios web detectar casos de web scraping?
Los sitios web han implementado mecanismos para detectar y prevenir actividades de web scraping, monitoreando elementos como cadenas de agente de usuario, direcciones IP y patrones de solicitud. Para mitigar la detección, las mejores prácticas incluyen el empleo de técnicas como la rotación de agentes de usuario, el uso de servidores proxy y la implementación de retrasos aleatorios entre solicitudes. Sin embargo, es fundamental tener en cuenta que los intentos de eludir las medidas de detección pueden violar los términos de servicio de un sitio web y potencialmente tener consecuencias legales. Las prácticas de web scraping responsables y éticas priorizan la transparencia y el cumplimiento de estándares legales y éticos.