
Técnicas efectivas de rastreo web para aplicaciones de Big Data
Publicado: 2024-06-06En la era del big data, el rastreo de sitios web se ha convertido en un proceso indispensable para las empresas que buscan aprovechar la enorme riqueza de información disponible en línea. Al recopilar, procesar y analizar datos web a escala de manera eficiente, las empresas pueden desbloquear información valiosa y obtener una ventaja competitiva en diversas industrias.
Los datos web tienen un inmenso potencial y ofrecen conocimientos profundos sobre las tendencias del mercado, el comportamiento del consumidor y los panoramas competitivos. La capacidad de recopilar y analizar estos datos de manera eficiente puede transformar la información sin procesar en inteligencia procesable, impulsando la toma de decisiones estratégicas y el crecimiento empresarial.
Fuente: scrapehero
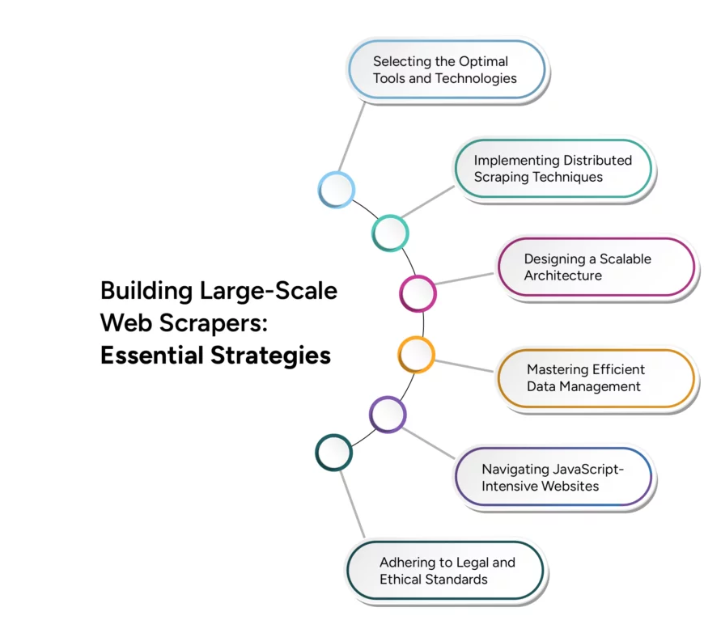
Sin embargo, la transición del web scraping a pequeña escala al rastreo web a gran escala presenta importantes desafíos técnicos. El escalamiento efectivo requiere una consideración cuidadosa de varios factores, incluida la infraestructura, la gestión de datos y la eficiencia del procesamiento. Este artículo profundiza en las técnicas y estrategias avanzadas necesarias para superar estos desafíos, garantizando que sus operaciones de rastreo web puedan crecer para satisfacer las demandas de las aplicaciones de big data.
Desafíos del rastreo de sitios web para aplicaciones de Big Data
El rastreo de sitios web para aplicaciones de big data presenta varios desafíos importantes que las empresas deben abordar para aprovechar de manera efectiva el poder de la vasta información en línea. Comprender y superar estos desafíos es crucial para construir una infraestructura de rastreo web sólida y escalable.
Uno de los principales desafíos es el gran volumen y variedad de datos en la web, que continúa creciendo exponencialmente. Además, la diversidad de tipos de datos, desde texto e imágenes hasta vídeos y contenido dinámico, añade complejidad al proceso de rastreo de sitios web. Los sitios web modernos suelen utilizar contenido dinámico generado por JavaScript y AJAX, lo que dificulta
rastreadores tradicionales para capturar toda la información relevante. Además, los sitios web pueden imponer límites de velocidad o bloquear direcciones IP para evitar un rastreo excesivo, que puede interrumpir los esfuerzos de recopilación de datos.
Garantizar la precisión y la coherencia de los datos recopilados de diversas fuentes puede resultar difícil, especialmente cuando se trata de grandes conjuntos de datos. Escalar las operaciones de rastreo web para manejar cargas de datos cada vez mayores sin comprometer el rendimiento es un desafío técnico importante. Además, cumplir con las pautas legales y éticas para rastrear sitios web es crucial para evitar posibles problemas legales y mantener una buena reputación. También es fundamental gestionar eficientemente los recursos informáticos para equilibrar la velocidad de rastreo y la rentabilidad.
Técnicas para la extracción eficiente de datos
La implementación de técnicas avanzadas de extracción de datos garantiza que los datos recopilados sean relevantes, precisos y estén listos para el análisis. A continuación se presentan algunas técnicas clave para mejorar la eficiencia de la extracción de datos:
- Procesamiento paralelo : utilice el procesamiento paralelo para distribuir las tareas de extracción de datos entre múltiples subprocesos o máquinas, aumentando la velocidad de extracción de datos al manejar múltiples solicitudes simultáneamente y reduciendo el tiempo total requerido para recopilar datos.
- Rastreo incremental : implemente el rastreo incremental para actualizar solo las partes del conjunto de datos que han cambiado desde el último rastreo, lo que reduce la cantidad de datos procesados y la carga en los servidores web, lo que hace que el proceso de rastreo sea más eficiente y consuma menos recursos.
- Navegadores sin cabeza : utilice navegadores sin cabeza como Puppeteer o Selenium para representar e interactuar con contenido web dinámico, lo que permite una extracción precisa de datos de sitios web que dependen en gran medida de JavaScript y AJAX, lo que garantiza una recopilación de datos completa.
- Priorización de contenido : priorice el contenido según su relevancia e importancia, centrándose primero en los datos de alto valor, garantizando que los datos más críticos se recopilen rápidamente y optimizando la utilización de recursos y la relevancia de los datos.
- Políticas de cortesía y programación de URL : implemente políticas de cortesía y programación de URL inteligentes para administrar la frecuencia de las solicitudes a un solo servidor, evitando la sobrecarga de los servidores web y reduciendo el riesgo de bloqueo de IP, garantizando un acceso sostenido a las fuentes de datos.
- Deduplicación de datos : emplee técnicas de deduplicación de datos para eliminar entradas duplicadas durante el proceso de extracción, mejorando la calidad de los datos y reduciendo los requisitos de almacenamiento al garantizar que solo se almacenen y procesen datos únicos.
Soluciones de rastreo web en tiempo real
Fuente: Medio

En el acelerado panorama digital actual, la capacidad de extraer y procesar datos en tiempo real es
crucial para las empresas que buscan mantener una ventaja competitiva. Las soluciones de rastreo web en tiempo real permiten la recopilación de datos continua e instantánea, lo que permite un análisis y una acción inmediatos. La implementación de una arquitectura basada en eventos puede mejorar significativamente las capacidades en tiempo real, donde los rastreadores se activan según eventos o cambios específicos en la web, lo que garantiza que los datos se recopilen tan pronto como estén disponibles.
Escalabilidad en el rastreo web en varios idiomas
La naturaleza global de Internet requiere la capacidad de rastrear y procesar datos en múltiples idiomas, lo que presenta desafíos únicos que requieren soluciones especializadas. Las operaciones de rastreo de sitios web para manejar contenido multilingüe implican implementar algoritmos de detección de idioma para identificar automáticamente el idioma de las páginas web y garantizar que se apliquen las técnicas de procesamiento específicas del idioma adecuadas. El uso de bibliotecas y marcos de análisis que admiten múltiples idiomas, como BeautifulSoup, proporciona herramientas sólidas para extraer contenido de diversas páginas web. La integración de servicios de traducción escalables como Google Cloud Translation en el proceso de procesamiento de datos permite la traducción de contenido en tiempo real, lo que permite un análisis fluido en diferentes idiomas.
Conclusión
Fuente: grupobwt
A medida que nos adentramos en la era digital, la importancia de rastrear sitios web para aplicaciones de big data sigue creciendo. El futuro del rastreo web reside en su capacidad de escalar de manera eficiente, adaptarse a entornos web dinámicos y proporcionar información en tiempo real. Los avances en inteligencia artificial y aprendizaje automático desempeñarán un papel fundamental a la hora de mejorar las capacidades de los rastreadores web, haciéndolos más inteligentes y eficientes en el procesamiento de grandes cantidades de datos.
La integración de sistemas distribuidos e infraestructuras basadas en la nube mejorará aún más la escalabilidad, permitiendo a las empresas manejar conjuntos de datos cada vez más grandes con facilidad. A medida que las tecnologías de rastreo web sigan evolucionando, no solo mejorarán los procesos de recopilación de datos, sino que también garantizarán que las empresas puedan mantener una ventaja competitiva en un panorama digital en constante cambio.
Adoptar estos avances no es solo una opción sino una necesidad para las organizaciones que buscan aprovechar los big data de manera efectiva. El futuro del rastreo web promete ser una fuerza transformadora, que impulse la innovación y proporcione las herramientas necesarias para desbloquear todo el potencial del vasto ecosistema de datos web.
Lleve sus aplicaciones de big data al siguiente nivel con los servicios de web scraping personalizables de PromptCloud con perfecta integración y escalabilidad. Contáctenos hoy para aprovechar el poder del rastreo web avanzado para su negocio.