
Extracción de datos de sitios web dinámicos: desafíos y soluciones
Publicado: 2023-11-23Internet alberga una reserva de datos extensa y en constante expansión, que ofrece un valor tremendo a empresas, investigadores e individuos que buscan conocimientos, toma de decisiones informadas o soluciones innovadoras. Sin embargo, una parte sustancial de esta valiosa información reside en sitios web dinámicos.
A diferencia de los sitios web estáticos convencionales, los sitios web dinámicos generan contenido dinámicamente en respuesta a interacciones del usuario o eventos externos. Estos sitios aprovechan tecnologías como JavaScript para manipular el contenido de las páginas web, lo que plantea un desafío formidable para las técnicas tradicionales de web scraping para extraer datos de manera efectiva.
En este artículo, profundizaremos en el ámbito del scraping dinámico de páginas web. Examinaremos los desafíos típicos vinculados a este proceso y presentaremos estrategias efectivas y mejores prácticas para superar estos obstáculos.
Comprender los sitios web dinámicos
Antes de profundizar en las complejidades del scraping de páginas web dinámicas, es esencial establecer una comprensión clara de lo que caracteriza a un sitio web dinámico. A diferencia de sus homólogos estáticos que proporcionan contenido uniforme universalmente, los sitios web dinámicos generan contenido dinámicamente en función de diversos parámetros, como las preferencias del usuario, las consultas de búsqueda o los datos en tiempo real.
Los sitios web dinámicos a menudo aprovechan sofisticados marcos de JavaScript para modificar y actualizar dinámicamente el contenido de la página web en el lado del cliente. Si bien este enfoque mejora significativamente la interactividad del usuario, presenta desafíos al intentar extraer datos mediante programación.
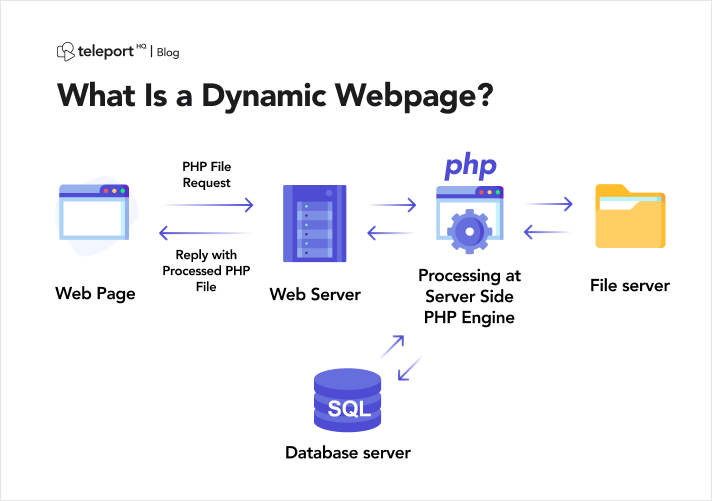
Fuente de la imagen: https://teleporthq.io/
Desafíos comunes en el scraping dinámico de páginas web
El scraping dinámico de páginas web plantea varios desafíos debido a la naturaleza dinámica del contenido. Algunos de los desafíos más comunes incluyen:
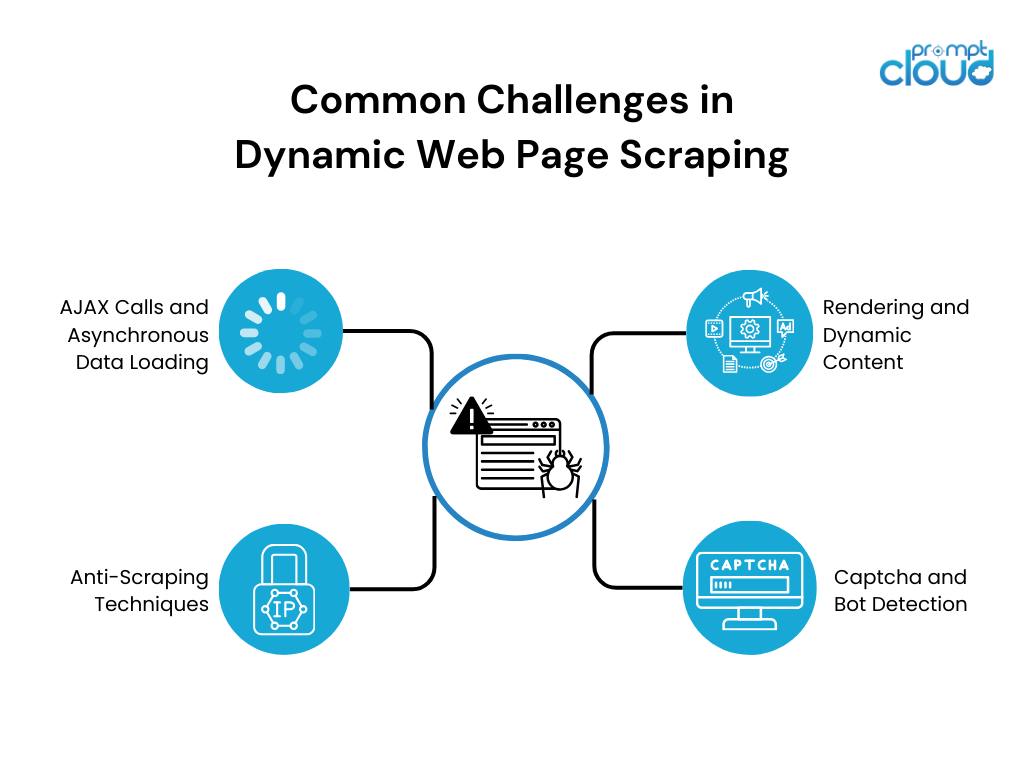
- Representación y contenido dinámico: los sitios web dinámicos dependen en gran medida de JavaScript para representar el contenido de forma dinámica. Las herramientas tradicionales de web scraping tienen dificultades para interactuar con contenido basado en JavaScript, lo que da como resultado una extracción de datos incompleta o incorrecta.
- Llamadas AJAX y carga de datos asincrónica: muchos sitios web dinámicos utilizan llamadas asincrónicas de JavaScript y XML (AJAX) para recuperar datos de los servidores web sin recargar toda la página. Esta carga de datos asincrónica puede dificultar la extracción del conjunto de datos completo, ya que puede cargarse progresivamente o activarse mediante interacciones del usuario.
- Captcha y detección de bots: para evitar la extracción y protección de datos, los sitios web emplean varias contramedidas, como captchas y mecanismos de detección de bots. Estas medidas de seguridad obstaculizan los esfuerzos de raspado y requieren estrategias adicionales para superarlas.
- Técnicas anti-scraping: los sitios web emplean varias técnicas anti-scraping, como bloqueo de IP, limitación de velocidad o estructuras HTML ofuscadas para disuadir a los scrapers. Estas técnicas requieren estrategias de raspado adaptativas para evadir la detección y raspar los datos deseados con éxito.
Estrategias para el scraping de páginas web dinámicas con éxito
A pesar de los desafíos, existen varias estrategias y técnicas que se pueden emplear para superar los obstáculos que se enfrentan al eliminar páginas web dinámicas. Estas estrategias incluyen:

- Uso de navegadores sin cabeza: Los navegadores sin cabeza como Puppeteer o Selenium permiten la ejecución de JavaScript y la representación de contenido dinámico, lo que permite la extracción precisa de datos de sitios web dinámicos.
- Inspección del tráfico de la red: el análisis del tráfico de la red puede proporcionar información sobre el flujo de datos dentro de un sitio web dinámico. Este conocimiento se puede utilizar para identificar llamadas AJAX, interceptar respuestas y extraer los datos necesarios.
- Análisis de contenido dinámico: analizar el DOM HTML después de que JavaScript haya representado el contenido dinámico puede ayudar a extraer los datos deseados. Se pueden utilizar herramientas como Beautiful Soup o Cheerio para analizar y extraer datos del DOM actualizado.
- Rotación de IP y proxies: rotar direcciones IP y utilizar proxies puede ayudar a superar los desafíos de limitación de velocidad y bloqueo de IP. Permite el scraping distribuido y evita que los sitios web identifiquen el scraper como una única fuente.
- Manejo de Captchas y técnicas anti-scraping: cuando se enfrenta a Captchas, emplear servicios de resolución de captcha o implementar una emulación humana puede ayudar a evitar estas medidas. Además, las estructuras HTML ofuscadas se pueden aplicar ingeniería inversa utilizando técnicas como el recorrido DOM o el reconocimiento de patrones.
Mejores prácticas para el web scraping dinámico
Al realizar el scraping de páginas web dinámicas, es importante seguir ciertas mejores prácticas para garantizar un proceso de scraping ético y exitoso. Algunas mejores prácticas incluyen:
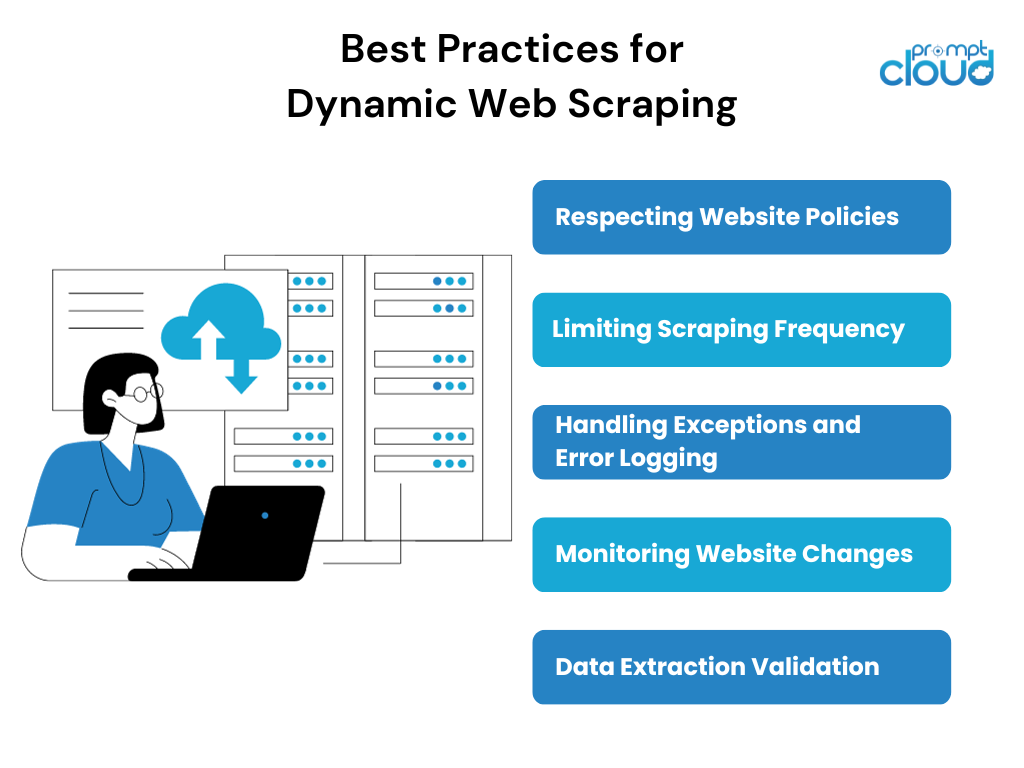
- Respetar las políticas del sitio web: antes de eliminar cualquier sitio web, es esencial revisar y respetar los términos de servicio del sitio web, el archivo robots.txt y cualquier directriz de eliminación específica mencionada.
- Limitar la frecuencia del scraping: el scraping excesivo puede ejercer presión tanto sobre los recursos del scraper como sobre el sitio web que se está raspando. Implementar límites de frecuencia de scraping razonables y respetar los límites de velocidad establecidos por el sitio web puede ayudar a mantener un proceso de scraping armonioso.
- Manejo de excepciones y registro de errores: el web scraping dinámico implica lidiar con escenarios impredecibles, como errores de red, solicitudes de captcha o cambios en la estructura del sitio web. La implementación de mecanismos adecuados de manejo de excepciones y registro de errores ayudará a identificar y abordar estos problemas.
- Monitoreo de cambios en el sitio web: los sitios web dinámicos se someten con frecuencia a actualizaciones o rediseños, lo que puede romper los scripts de scraping existentes. El monitoreo regular del sitio web de destino para detectar cualquier cambio y el ajuste rápido de la estrategia de raspado pueden garantizar una extracción de datos ininterrumpida.
- Validación de extracción de datos: validar y comparar los datos extraídos con la interfaz de usuario del sitio web puede ayudar a garantizar la precisión e integridad de la información extraída. Este paso de validación es especialmente crucial cuando se seleccionan páginas web dinámicas con contenido en evolución.
Conclusión
El poder del scraping dinámico de páginas web abre un mundo de oportunidades para acceder a datos valiosos ocultos en sitios web dinámicos. Superar los desafíos asociados con el scraping de sitios web dinámicos requiere una combinación de experiencia técnica y cumplimiento de prácticas éticas de scraping.
Al comprender las complejidades del scraping dinámico de páginas web e implementar las estrategias y mejores prácticas descritas en este artículo, las empresas y los individuos pueden desbloquear todo el potencial de los datos web y obtener una ventaja competitiva en diversos dominios.
Otro desafío que se encuentra en el scraping dinámico de páginas web es el volumen de datos que se deben extraer. Las páginas web dinámicas suelen contener una gran cantidad de información, lo que dificulta la recopilación y extracción de datos relevantes de manera eficiente.
Para superar este obstáculo, las empresas pueden aprovechar la experiencia de los proveedores de servicios de web scraping. La poderosa infraestructura de scraping de PromptCloud y las técnicas avanzadas de extracción de datos permiten a las empresas manejar proyectos de scraping a gran escala con facilidad.
Con la ayuda de PromptCloud, las organizaciones pueden extraer información valiosa de páginas web dinámicas y transformarlas en inteligencia procesable. Experimente el poder del scraping dinámico de páginas web asociándose con PromptCloud hoy. Contáctenos en sales@promptcloud.com.