
Scraping dinámico de páginas web con Python: guía práctica
Publicado: 2024-06-08El web scraping dinámico implica recuperar datos de sitios web que generan contenido en tiempo real a través de JavaScript o Python. A diferencia de las páginas web estáticas, el contenido dinámico se carga de forma asincrónica, lo que hace que las técnicas tradicionales de scraping sean ineficientes.
Usos del web scraping dinámico:
- Sitios web basados en AJAX
- Aplicaciones de una sola página (SPA)
- Sitios con elementos de carga retrasados
Herramientas y tecnologías clave:
- Selenium : automatiza las interacciones del navegador.
- BeautifulSoup : analiza el contenido HTML.
- Solicitudes : recupera el contenido de la página web.
- lxml : analiza XML y HTML.
Python de web scraping dinámico requiere una comprensión más profunda de las tecnologías web para recopilar datos en tiempo real de manera efectiva.
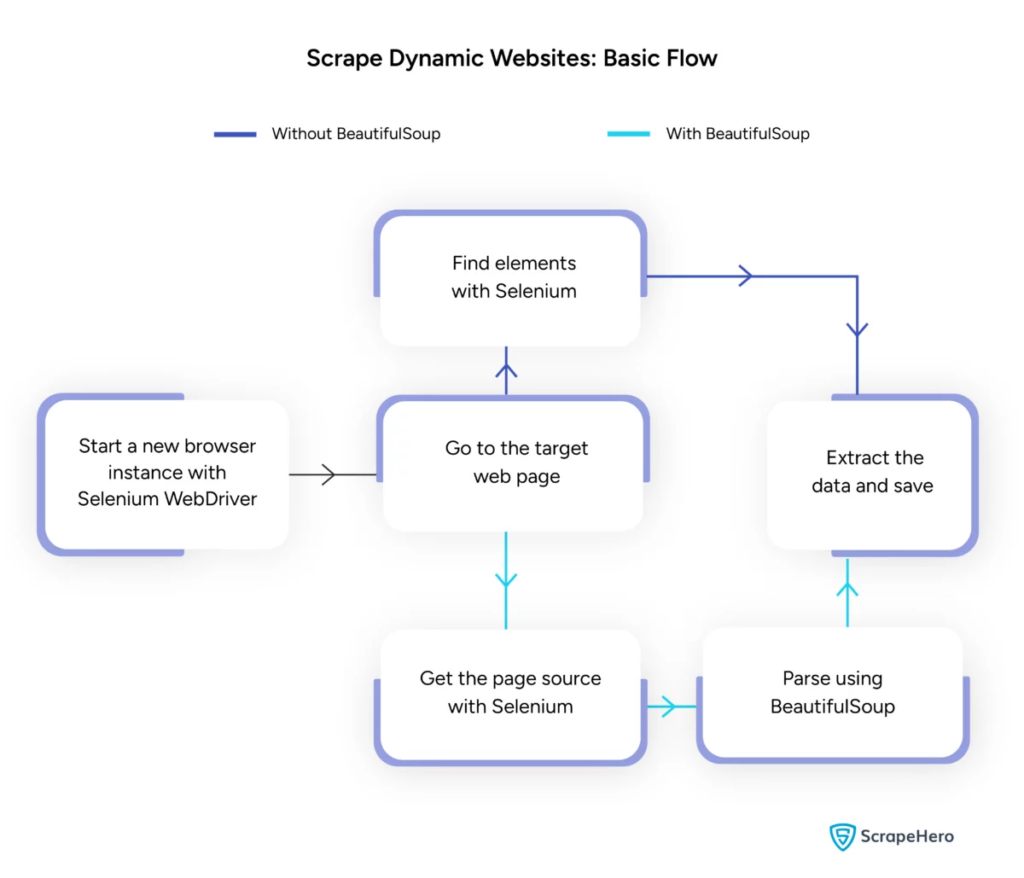
Fuente de la imagen: https://www.scrapehero.com/scrape-a-dynamic-website/
Configurando el entorno Python
Para comenzar a realizar web scraping dinámico en Python, es esencial configurar el entorno correctamente. Sigue estos pasos:
- Instalar Python : asegúrese de que Python esté instalado en la máquina. La última versión se puede descargar desde el sitio web oficial de Python.
- Crear un entorno virtual :

Activar el entorno virtual:

- Instalar bibliotecas requeridas :

- Configure un editor de código : utilice un IDE como PyCharm, VSCode o Jupyter Notebook para escribir y ejecutar scripts.
- Familiarícese con HTML/CSS : comprender la estructura de la página web ayuda a navegar y extraer datos de manera efectiva.
Estos pasos establecen una base sólida para proyectos dinámicos de web scraping en Python.
Comprender los conceptos básicos de las solicitudes HTTP
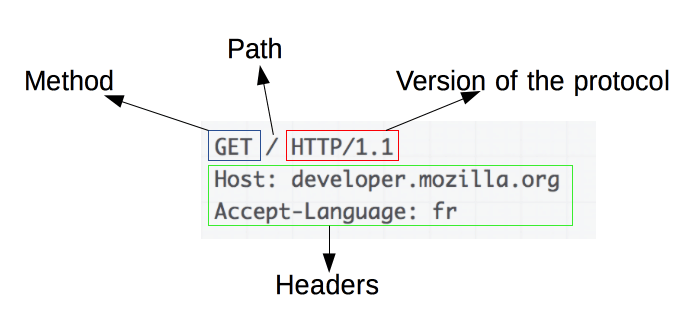
Fuente de la imagen: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
Las solicitudes HTTP son la base del web scraping. Cuando un cliente, como un navegador web o un raspador web, quiere recuperar información de un servidor, envía una solicitud HTTP. Estas solicitudes siguen una estructura específica:
- Método : la acción a realizar, como GET o POST.
- URL : la dirección del recurso en el servidor.
- Encabezados : metadatos sobre la solicitud, como tipo de contenido y agente de usuario.
- Cuerpo : datos opcionales enviados con la solicitud, normalmente utilizados con POST.
Comprender cómo interpretar y construir estos componentes es esencial para un web scraping eficaz. Las bibliotecas de Python, como las solicitudes, simplifican este proceso y permiten un control preciso sobre las solicitudes.
Instalación de bibliotecas Python
Fuente de la imagen: https://ajaytech.co/what-are-python-libraries/
Para el raspado web dinámico con Python, asegúrese de que Python esté instalado. Abra la terminal o el símbolo del sistema e instale las bibliotecas necesarias usando pip:
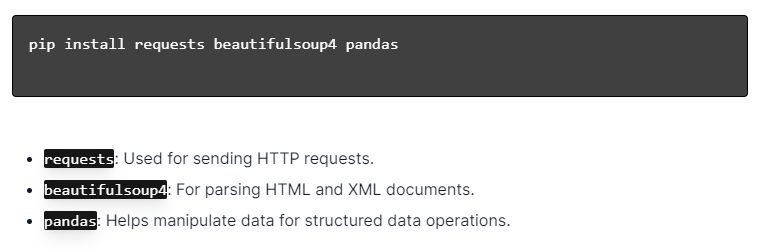
A continuación, importe estas bibliotecas a su script:

Al hacerlo, cada biblioteca estará disponible para tareas de raspado web, como enviar solicitudes, analizar HTML y administrar datos de manera eficiente.
Creación de un script de raspado web sencillo
Para crear un script de web scraping dinámico básico en Python, primero se deben instalar las bibliotecas necesarias. La biblioteca "solicitudes" maneja solicitudes HTTP, mientras que "BeautifulSoup" analiza el contenido HTML.
Pasos a seguir:
- Instalar dependencias:

- Importar bibliotecas:

- Obtener contenido HTML:
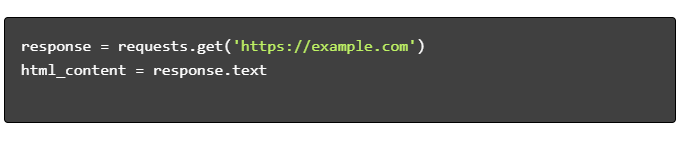
- Analizar HTML:

- Extraer datos:

Manejo del web scraping dinámico con Python
Los sitios web dinámicos generan contenido sobre la marcha, lo que a menudo requiere técnicas más sofisticadas.

Considere los siguientes pasos:
- Identificar elementos de destino : inspeccionar la página web para localizar contenido dinámico.
- Elija un marco Python : utilice bibliotecas como Selenium o Playwright.
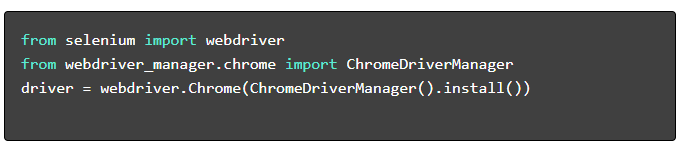
- Instalar los paquetes necesarios :
- Configurar el controlador web :

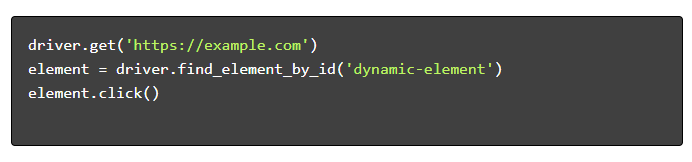
- Navegar e interactuar :
Mejores prácticas de raspado web
Se recomienda seguir las mejores prácticas de web scraping para garantizar la eficiencia y la legalidad. A continuación se presentan pautas clave y estrategias de manejo de errores:
- Respete Robots.txt : compruebe siempre el archivo robots.txt del sitio de destino.
- Limitación : implementar retrasos para evitar la sobrecarga del servidor.
- Agente de usuario : utilice una cadena de Agente de usuario personalizada para evitar posibles bloqueos.
- Lógica de reintento : use bloques try-except y configure la lógica de reintento para manejar los tiempos de espera del servidor.
- Registro : mantenga registros completos para la depuración.
- Manejo de excepciones : detecta específicamente errores de red, errores HTTP y errores de análisis.
- Detección de Captcha : Incorporar estrategias para detectar y resolver o eludir CAPTCHA.
Desafíos comunes del raspado web dinámico
captchas
Muchos sitios web utilizan CAPTCHA para evitar bots automatizados. Para evitar esto:
- Utilice servicios de resolución de CAPTCHA como 2Captcha.
- Implementar intervención humana para la resolución de CAPTCHA.
- Utilice proxies para limitar las tasas de solicitudes.
Bloqueo de IP
Los sitios pueden bloquear las IP que realizan demasiadas solicitudes. Contrarresta esto mediante:
- Utilizar proxies rotativos.
- Implementación de limitación de solicitudes.
- Emplear estrategias de rotación usuario-agente.
Representación de JavaScript
Algunos sitios cargan contenido a través de JavaScript. Aborde este desafío:
- Usando Selenium o Puppeteer para la automatización del navegador.
- Emplear Scrapy-splash para renderizar contenido dinámico.
- Explorando navegadores sin cabeza para interactuar con JavaScript.
Asuntos legales
El web scraping a veces puede violar los términos de servicio. Garantizar el cumplimiento mediante:
- Consultoría de asesoramiento jurídico.
- Eliminación de datos de acceso público.
- Respetar las directivas de robots.txt.
Análisis de datos
Manejar estructuras de datos inconsistentes puede ser un desafío. Las soluciones incluyen:
- Usar bibliotecas como BeautifulSoup para el análisis de HTML.
- Emplear expresiones regulares para la extracción de texto.
- Utilizar analizadores JSON y XML para datos estructurados.
Almacenamiento y análisis de datos extraídos
El almacenamiento y el análisis de datos extraídos son pasos cruciales en el web scraping. Decidir dónde almacenar los datos depende del volumen y el formato. Las opciones de almacenamiento comunes incluyen:
- Archivos CSV : fáciles para conjuntos de datos pequeños y análisis simples.
- Bases de datos : bases de datos SQL para datos estructurados; NoSQL para no estructurado.
Una vez almacenados, el análisis de los datos se puede realizar utilizando las bibliotecas de Python:
- Pandas : Ideal para manipulación y limpieza de datos.
- NumPy : Eficiente para operaciones numéricas.
- Matplotlib y Seaborn : Adecuado para visualización de datos.
- Scikit-learn : proporciona herramientas para el aprendizaje automático.
El almacenamiento y análisis de datos adecuados mejoran la accesibilidad y la información sobre los datos.
Conclusión y próximos pasos
Después de haber recorrido un Python de web scraping dinámico, es imperativo perfeccionar la comprensión de las herramientas y bibliotecas destacadas.
- Revise el código : consulte el script final y modularícelo cuando sea posible para mejorar la reutilización.
- Bibliotecas adicionales : explore bibliotecas avanzadas como Scrapy o Splash para necesidades más complejas.
- Almacenamiento de datos : considere opciones de almacenamiento sólidas: bases de datos SQL o almacenamiento en la nube para administrar grandes conjuntos de datos.
- Consideraciones legales y éticas : manténgase actualizado sobre las pautas legales sobre web scraping para evitar posibles infracciones.
- Próximos proyectos : abordar nuevos proyectos de web scraping con diferentes complejidades consolidará aún más estas habilidades.
¿Quiere integrar el web scraping dinámico profesional con Python en su proyecto? Para aquellos equipos que requieren extracción de datos a gran escala sin la complejidad de manejarlos internamente, PromptCloud ofrece soluciones personalizadas. Explore los servicios de PromptCloud para obtener una solución sólida y confiable. ¡Póngase en contacto con nosotros hoy!