
Análisis factorial exploratorio en R
Publicado: 2017-02-16¿Qué es el análisis factorial exploratorio en R?
El análisis factorial exploratorio (AFE) o más o menos conocido como análisis factorial en R es una técnica estadística que se utiliza para identificar la estructura relacional latente entre un conjunto de variables y reducirla a un número menor de variables. Básicamente, esto significa que la varianza de un gran número de variables puede describirse mediante unas pocas variables de resumen, es decir, factores. Aquí hay una descripción general del análisis factorial exploratorio en R.
Como sugiere el nombre, EFA es de naturaleza exploratoria: no conocemos realmente las variables latentes, y los pasos se repiten hasta que llegamos a un número menor de factores. En este tutorial, veremos EFA usando R. Ahora, primero tengamos la idea básica del conjunto de datos.
1. Los datos
Este conjunto de datos contiene 90 respuestas para 14 variables diferentes que los clientes consideran al comprar un automóvil. Las preguntas de la encuesta se enmarcaron utilizando una escala Likert de 5 puntos, siendo 1 muy bajo y 5 muy alto. Las variables fueron las siguientes:
- Precio
- La seguridad
- apariencia exterior
- Espacio y comodidad
- Tecnología
- Servicio postventa
- Valor de reventa
- Tipo de combustible
- Eficiencia de combustible
- Color
- Mantenimiento
- Prueba de conducción
- Reseñas de productos
- Testimonios
Haga clic aquí para descargar el conjunto de datos codificados.
2. Importación de datos web
Ahora leeremos el conjunto de datos presente en formato CSV en R y lo almacenaremos como una variable.
[code language=”r”] datos <- read.csv(file.choose( ), encabezado = VERDADERO) [/ código]
Se abrirá una ventana para elegir el archivo CSV y la opción `header` se asegurará de que la primera fila del archivo se considere como el encabezado. Ingrese lo siguiente para ver las primeras filas del marco de datos y confirme que los datos se han almacenado correctamente.
[código idioma=”r”] cabeza(datos) [/código]
3. Instalación del paquete
Ahora instalaremos los paquetes necesarios para realizar un análisis más detallado. Estos paquetes son `psych` y `GPArotation`. En el código que se proporciona a continuación, estamos llamando a `install.packages()` para la instalación.
[code language=”r”] install.packages('psych') install.packages('GPArotation') [/code]
4. Número de factores
A continuación, averiguaremos la cantidad de factores que seleccionaremos para el análisis factorial. Esto se evalúa a través de métodos como `Análisis paralelo` y `valor propio`, etc.
Análisis paralelo
Usaremos la función `fa.parallel` del paquete `Psych` para ejecutar el análisis paralelo. Aquí especificamos el marco de datos y el método factorial (`minres` en nuestro caso). Ejecute lo siguiente para encontrar un número aceptable de factores y generar el `gráfico de pantalla`:
[code language=”r”] paralelo <- fa.parallel(data, fm = 'minres', fa = 'fa') [/code]
La consola mostraría el número máximo de factores que podemos considerar. Así es como se vería.
“El análisis paralelo sugiere que el número de factores = 5 y el número de componentes = NA“
A continuación, en el `gráfico de pantalla` generado a partir del código anterior:
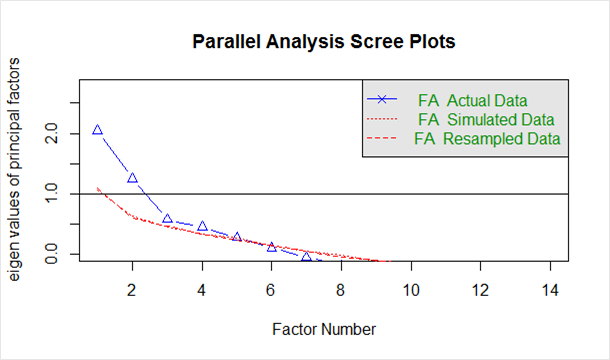
La línea azul muestra los valores propios de los datos reales y las dos líneas rojas (colocadas una encima de la otra) muestran datos simulados y remuestreados. Aquí observamos las grandes caídas en los datos reales y detectamos el punto donde se estabiliza hacia la derecha. Además, ubicamos el punto de inflexión: el punto donde la brecha entre los datos simulados y los datos reales tiende a ser mínima.

Mirando esta gráfica y el análisis paralelo, entre 2 y 5 factores sería una buena opción.
Análisis factorial
Ahora que hemos llegado a un número probable de factores, comencemos con 3 como el número de factores. Para realizar un análisis factorial, usaremos la función `psych` packages`fa(). A continuación se presentan los argumentos que proporcionaremos:
- r – Datos sin procesar o matriz de correlación o covarianza
- nfactors – Número de factores a extraer
- rotar: aunque hay varios tipos de rotaciones, `Varimax` y `Oblimin` son las más populares
- fm: una de las técnicas de extracción de factores como 'Residuo mínimo (OLS)', 'Máxima probabilidad', 'Eje principal', etc.
En este caso, seleccionaremos la rotación oblicua (rotate = “oblimin”) ya que creemos que existe una correlación en los factores. Tenga en cuenta que la rotación Varimax se utiliza bajo el supuesto de que los factores no están correlacionados en absoluto. Usaremos la factorización `Ordinary Least Squared/Minres` (fm = “minres”), ya que se sabe que proporciona resultados similares a `Máxima probabilidad` sin asumir una distribución normal multivariada y deriva soluciones a través de la descomposición propia iterativa como un eje principal.
Ejecute lo siguiente para iniciar el análisis.
[code language=”r”] threefactor <- fa(data,nfactors = 3, rotar = "oblimin",fm = "minres") imprimir (tres factores) [/ código]
Aquí está la salida que muestra factores y cargas:
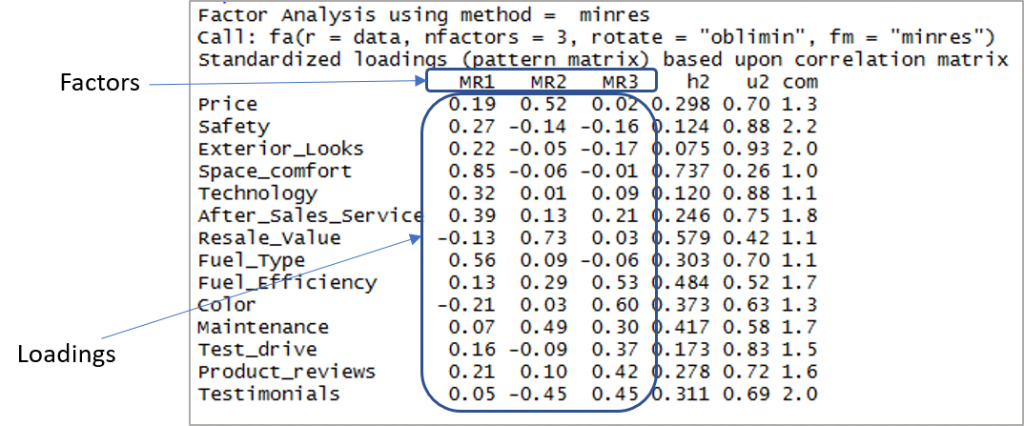
Ahora necesitamos considerar las cargas de más de 0.3 y no cargar en más de un factor. Tenga en cuenta que los valores negativos son aceptables aquí. Así que primero establezcamos el corte para mejorar la visibilidad.
[code language=”r”] print(tresfactores$cargas,cutoff = 0.3) [/code]
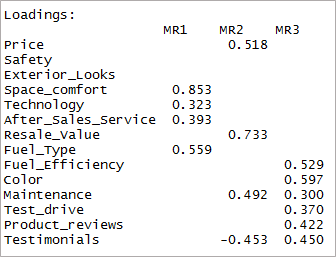
Como puede ver, dos variables se han vuelto insignificantes y otras dos tienen doble carga. A continuación, consideraremos los '4' factores.
[code language=”r”] fourfactor <- fa(data,nfactors = 4, rotar = “oblimin”,fm=”minres”) print(cuatrofactores$cargas,corte = 0.3) [/código]
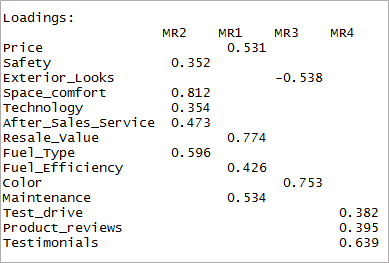
Podemos ver que da como resultado una sola carga. Esto se conoce como la estructura simple.
Presione lo siguiente para ver el mapeo de factores.
[code language=”r”] fa.diagram(fourfactor) [/code]
Prueba de adecuación
Ahora que hemos logrado una estructura simple, es hora de que validemos nuestro modelo. Veamos el resultado del análisis factorial para continuar.

La raíz significa que el cuadrado de los residuos (RMSR) es 0,05. Esto es aceptable ya que este valor debería estar más cerca de 0. A continuación, debemos comprobar el índice RMSEA (error cuadrático medio de aproximación). Su valor, 0.001 muestra un buen ajuste del modelo ya que está por debajo de 0.05. Finalmente, el índice de Tucker-Lewis (TLI) es 0,93, un valor aceptable teniendo en cuenta que está por encima de 0,9.
Nombrar los factores

Después de establecer la adecuación de los factores, es hora de que nombremos los factores. Este es el lado teórico del análisis donde formamos los factores dependiendo de las cargas variables. En este caso, así es como se pueden crear los factores.
Conclusión
En este tutorial para el análisis en r, discutimos la idea básica de EFA (análisis factorial exploratorio en R), cubrimos el análisis paralelo y la interpretación de diagramas de sedimentación. Luego pasamos al análisis factorial en R para lograr una estructura simple y validar la misma para asegurar la adecuación del modelo. Finalmente llegó a los nombres de los factores de las variables. Ahora adelante, pruébelo y publique sus hallazgos en la sección de comentarios.