
La voz del bazar
Publicado: 2024-04-24Este artículo sobre la modernización de los sistemas heredados es complementario de una charla que presenté recientemente en la Cumbre de datos de AWS para empresas de software sobre la generación de valor a partir de los datos aprovechando nuestras mejores prácticas para garantizar el éxito en los proyectos de aprendizaje automático. Puedes saltar hasta el final aquí para verlo si lo prefieres.
Seamos realistas: el software es más fácil de escribir que de mantener. Es por eso que nosotros, como ingenieros de software, preferimos simplemente "arrancarlo y empezar de nuevo" en lugar de intentar comprender lo que otro desarrollador (o nuestro yo pasado) estaba pensando. Parece que hemos olvidado colectivamente que “los programas deben escribirse para que las personas los lean y, sólo de paso, para que las máquinas los ejecuten”.
Sabes que es verdad: todos hemos tenido que rastrear minuciosamente una cazuela de código de espagueti y abstracciones delgadas al estilo del viejo mundo buscando la esencia del programa solo para encontrar nada más que un desastre en el fondo de nuestros platos.
Es fácil gritar "WTF" y culpar al desarrollador anterior, pero la verdad suele ser más complicada. No podemos ver el futuro, por lo que es imposible entender cómo crecerán los requisitos, la tecnología o los objetivos comerciales cuando diseñemos un sistema completamente nuevo. Como resultado, los sistemas pueden volverse ilegibles a medida que aumenta su alcance junto con la dependencia de la empresa de ellos. Esto es un poco paradójico: los sistemas más antiguos y más difíciles de mantener suelen ofrecer el mayor valor. Es difícil trabajar en ellos porque han crecido con la empresa, y da miedo trabajar en ellos porque romperlos podría ser una catástrofe.
Aquí es donde te llamo: si te gustan los problemas difíciles y gratificantes... pruébalo. Tome el sistema más antiguo que tenga y hágalo mantenible. Ya sabes de qué estoy hablando: aquel del que nadie será “dueño”. Ese del que dependen los demás departamentos pero que los ingenieros odian. En el que tuviste que parchear Log4Shell primero . Hazlo. Te reto.
Recientemente tuve la oportunidad de actualizar un sistema de aprendizaje automático de una década de antigüedad en Bazaarvoice. A primera vista, no parecía nada emocionante : ¡aquella cosa ni siquiera tenía redes neuronales! ¡A quién le importa! Bueno… importaba. Este sistema procesa casi todas las reseñas de productos generadas por usuarios que recibe Bazaarvoice (casi 9 millones por mes) y lo hace con 90 millones de llamadas de inferencia a modelos de aprendizaje automático. Sí, ¡90 millones de inferencias! Es una escala enorme y no podía esperar para sumergirme.
En esta publicación, compartiré cómo la modernización de este sistema heredado a través de una re-arquitectura, en lugar de una reescritura, nos permitió hacerlo escalable y rentable sin tener que eliminar todo el código y empezar de nuevo. El sistema resultante no tiene servidor, está en contenedores y es fácil de mantener, al tiempo que reduce nuestros costos de alojamiento en casi un 80 %.
¿Qué es un sistema heredado?
Un sistema heredado se refiere a un software y/o hardware informático antiguo que permanece en funcionamiento. Si bien aún puede cumplir su propósito original, carece de escalabilidad para un crecimiento futuro.
Viejos sistemas heredados
Primero, echemos un vistazo a lo que estamos tratando aquí. El sistema heredado que mi equipo estaba actualizando modera el contenido generado por el usuario para todo Bazaarvoice. Específicamente, determina si cada contenido es apropiado para los sitios web de nuestros clientes.

Esto suena sencillo (eliminar infracciones obvias como el discurso de odio, el lenguaje soez o las solicitudes), pero en la práctica tiene muchos más matices. Cada cliente tiene requerimientos únicos de lo que considera apropiado. Las marcas de cerveza, por ejemplo, esperarían que se hablara sobre el alcohol, pero una marca para niños tal vez no. Capturamos estas opciones específicas del cliente cuando incorporamos nuevos clientes y nuestro equipo de Servicios al Cliente las codifica en una base de datos de administración.
Para mayor complejidad, también probamos un subconjunto de nuestro contenido para que lo moderen moderadores humanos. Esto nos permite medir continuamente el rendimiento de nuestros modelos y descubrir oportunidades para construir más modelos.
La arquitectura completa de nuestro sistema heredado se muestra a continuación:
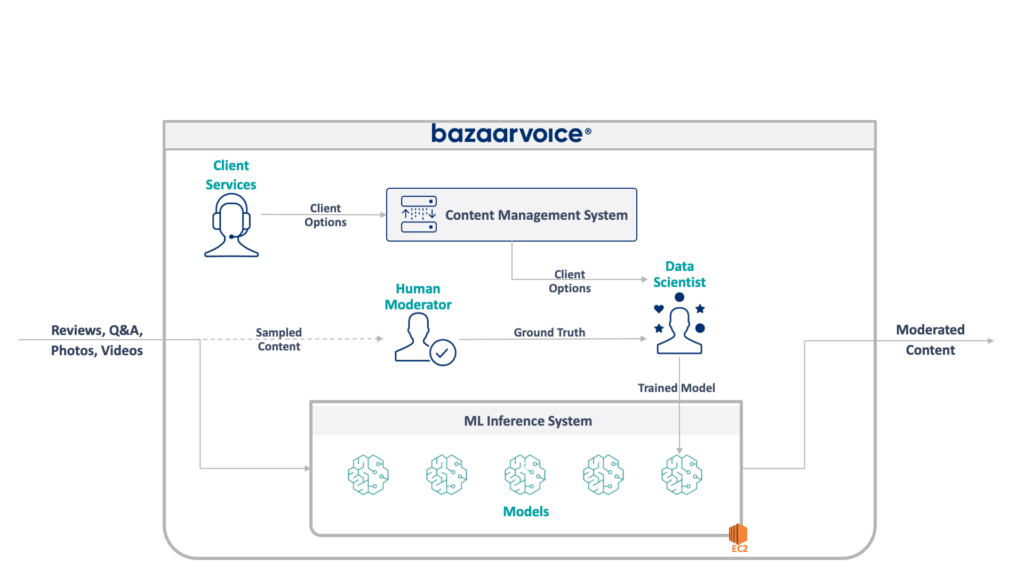
Este sistema tiene algunos inconvenientes graves. Específicamente, todos los modelos están alojados en una única instancia EC2. Esto no se debió a una mala ingeniería, sino simplemente a la incapacidad de los programadores originales para prever la escala deseada por la empresa. Nadie pensó que crecería tanto.
Además, el sistema sufrió el rechazo de los desarrolladores: estaba escrito en Scala, que pocos ingenieros entendían. Por lo tanto, a menudo se pasaba por alto para mejorarlo ya que nadie quería tocarlo.
Como resultado, el sistema continuó creciendo de manera constante. Una vez que empezamos a rediseñarlo, se estaba ejecutando en una única instancia x1e.8xlarge. Esta cosa tenía casi un terabyte de RAM y su funcionamiento cuesta alrededor de $ 5,000 al mes (sin reservas). Pero no se preocupe, acabamos de lanzar un segundo para redundancia y un tercero para control de calidad.
Este sistema era costoso de ejecutar y corría un alto riesgo de fallar (un solo modelo defectuoso puede arruinar todo el servicio). Además, el código base no se había desarrollado activamente y, por lo tanto, estaba significativamente desactualizado con respecto a los paquetes modernos de ciencia de datos y no seguía nuestras prácticas estándar para servicios escritos en Scala.
un nuevo sistema
Al rediseñar este sistema teníamos un objetivo claro: hacerlo escalable. Reducir los costos operativos era un objetivo secundario, al igual que facilitar la gestión de modelos y códigos.
El nuevo diseño que se nos ocurrió se ilustra a continuación:

Nuestro enfoque para resolver todo esto fue colocar cada modelo de aprendizaje automático en un punto final aislado de SageMaker Serverless. Al igual que las funciones de AWS Lambda, los puntos finales sin servidor se apagan cuando no están en uso, lo que nos ahorra costos de tiempo de ejecución para modelos que se utilizan con poca frecuencia. También pueden escalar rápidamente en respuesta a aumentos en el tráfico.

Además, expusimos las opciones del cliente a un único microservicio que enruta el contenido a los modelos apropiados. Esta fue la mayor parte del código nuevo que tuvimos que escribir: una pequeña API que era fácil de mantener y permitía a nuestros científicos de datos actualizar e implementar nuevos modelos más fácilmente.
Este enfoque tiene los siguientes beneficios:
- Se redujo el tiempo de obtención de valor en más de 6 veces. Específicamente, el enrutamiento del tráfico a los modelos existentes es instantáneo y la implementación de nuevos modelos se puede realizar en menos de 5 minutos en lugar de 30.
- Escala sin límite: actualmente tenemos 400 modelos, pero planeamos escalar a miles para seguir aumentando la cantidad de contenido que podemos moderar automáticamente.
- Obtuvimos una reducción de costos del 82 % al abandonar EC2, ya que las funciones se apagan cuando no están en uso y no pagamos por máquinas de primer nivel que están infrautilizadas.
Sin embargo, simplemente diseñar una arquitectura ideal no es la parte difícil realmente interesante de reconstruir un sistema heredado: hay que migrar a él.
Nuestro primer desafío en la migración fue descubrir cómo diablos migrar un modelo Java WEKA para ejecutarlo en SageMaker, y mucho menos en SageMaker Serverless.
Afortunadamente, SageMaker implementa modelos en contenedores Docker, por lo que al menos podríamos congelar las versiones de Java y de dependencia para que coincidan con nuestro código anterior. Esto ayudaría a garantizar que los modelos alojados en el nuevo sistema arrojaran los mismos resultados que el anterior.

Para que el contenedor sea compatible con SageMaker, todo lo que necesita hacer es implementar algunos puntos finales HTTP específicos:
-
POST /invocation: acepta entradas, realiza inferencias y devuelve resultados. -
GET /ping: devuelve 200 si el servidor JVM está en buen estado
(Elegimos ignorar todos los problemas relacionados con los contenedores multimodelo BYO y el kit de herramientas de inferencia SageMaker).
Unas cuantas abstracciones rápidas sobre com.sun.net.httpserver.HttpServer y estábamos listos para comenzar.
¿Y sabes qué? En realidad, esto fue muy divertido. Jugar con contenedores Docker y forzar algo de 10 años a ingresar a SageMaker Serverless tenía una sensación de retoque. Fue muy emocionante cuando lo hicimos funcionar, especialmente cuando obtuvimos el código del sistema heredado para construirlo en nuestra nueva pila sbt en lugar de maven.
La nueva pila sbt facilitó el trabajo y la contenedorización garantizó que pudiéramos obtener un comportamiento adecuado mientras ejecutábamos en el entorno de SageMaker.
Migrar a un nuevo sistema
Entonces tenemos los modelos en contenedores y podemos implementarlos en SageMaker; casi listo, ¿verdad? No exactamente.
La dura lección de migrar a una nueva arquitectura es que debe construir tres veces su sistema real solo para admitir la migración. Además del nuevo sistema, tuvimos que construir:
- Un canal de captura de datos en el sistema antiguo para registrar entradas y salidas del modelo. Los usamos para confirmar que el nuevo sistema arrojaría los mismos resultados.
- Un canal de procesamiento de datos en el nuevo sistema para calcular los resultados y compararlos con los datos del sistema anterior. Esto implicó una gran cantidad de mediciones con Datadog y necesitaba ofrecer la capacidad de reproducir datos cuando encontráramos discrepancias.
- Un sistema de implementación de modelo completo para evitar impactar a los usuarios del sistema antiguo (que simplemente subiría modelos a S3). Sabíamos que eventualmente queríamos moverlos a una API, pero para el lanzamiento inicial, necesitábamos hacerlo sin problemas.
Todo esto era código desechable que sabíamos que podíamos desechar una vez que termináramos de migrar a todos los usuarios, pero aún teníamos que compilarlo y asegurarnos de que los resultados del nuevo sistema coincidieran con el anterior.
Espere esto desde el principio.
Si bien la creación de herramientas y sistemas de migración ciertamente tomó más del 60 % de nuestro tiempo de ingeniería en este proyecto, también fue una experiencia divertida. Las pruebas unitarias se volvieron más como experimentos de ciencia de datos: escribimos conjuntos completos para asegurarnos de que nuestro resultado coincidiera exactamente . Era una forma diferente de pensar que hacía que el trabajo fuera mucho más divertido. Un paso fuera de nuestras cajas habituales, por así decirlo.
Modernizar los sistemas heredados mediante una reestructuración
La próxima vez que tenga la tentación de reconstruir un sistema desde el código, me gustaría animarlo a que intente migrar la arquitectura en lugar del código. Encontrará desafíos técnicos interesantes y gratificantes y probablemente los disfrutará mucho más que depurar casos extremos inesperados de su nuevo código.
¿Querer aprender más? Mire la charla que di en AWS Data Summit a continuación, que profundiza en el lado de MLOps.