
¿Cómo funciona un rastreador web?
Publicado: 2023-12-05Los rastreadores web desempeñan una función vital en la indexación y estructuración de la extensa información presente en Internet. Su función consiste en recorrer páginas web, recopilar datos y hacer que se puedan realizar búsquedas. Este artículo profundiza en la mecánica de un rastreador web y brinda información sobre sus componentes, operaciones y diversas categorías. ¡Profundicemos en el mundo de los rastreadores web!
¿Qué es un rastreador web?
Un rastreador web, conocido como araña o bot, es un script o programa automatizado diseñado para navegar metódicamente a través de sitios web de Internet. Comienza con una URL inicial y luego sigue enlaces HTML para visitar otras páginas web, formando una red de páginas interconectadas que pueden indexarse y analizarse.
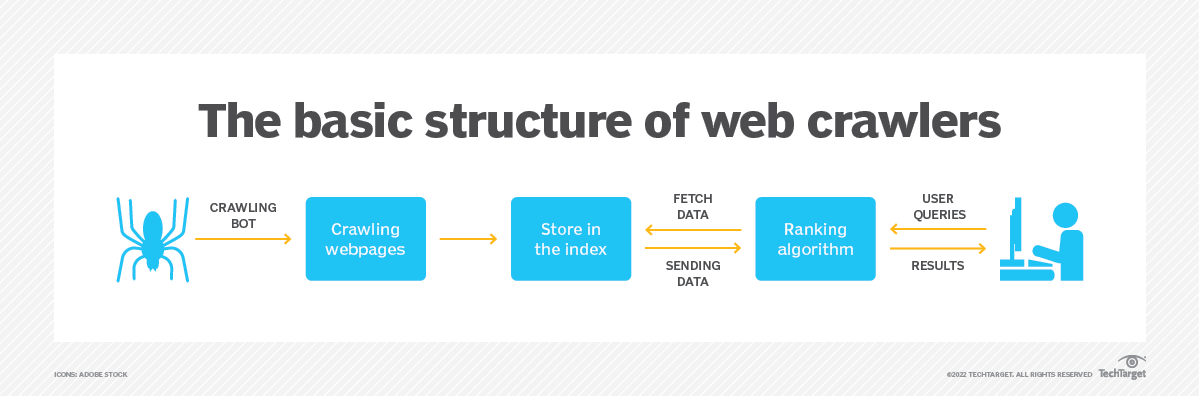
Fuente de la imagen: https://www.techtarget.com/
El propósito de un rastreador web
El objetivo principal de un rastreador web es recopilar información de las páginas web y generar un índice de búsqueda para una recuperación eficiente. Los principales motores de búsqueda, como Google, Bing y Yahoo, dependen en gran medida de los rastreadores web para construir sus bases de datos de búsqueda. A través del examen sistemático del contenido web, los motores de búsqueda pueden ofrecer a los usuarios resultados de búsqueda pertinentes y actuales.
Es importante señalar que la aplicación de los rastreadores web se extiende más allá de los motores de búsqueda. También son utilizados por varias organizaciones para tareas como extracción de datos, agregación de contenido, monitoreo de sitios web e incluso ciberseguridad.
Los componentes de un rastreador web
Un rastreador web consta de varios componentes que trabajan juntos para lograr sus objetivos. Estos son los componentes clave de un rastreador web:
- Frontera de URL: este componente gestiona la colección de URL en espera de ser rastreadas. Prioriza las URL en función de factores como la relevancia, la actualidad o la importancia del sitio web.
- Descargador: el descargador recupera páginas web según las URL proporcionadas por la frontera de URL. Envía solicitudes HTTP a servidores web, recibe respuestas y guarda el contenido web obtenido para su posterior procesamiento.
- Analizador: el analizador procesa las páginas web descargadas y extrae información útil como enlaces, texto, imágenes y metadatos. Analiza la estructura de la página y extrae las URL de las páginas vinculadas para agregarlas a la frontera de URL.
- Almacenamiento de datos: el componente de almacenamiento de datos almacena los datos recopilados, incluidas páginas web, información extraída y datos de indexación. Estos datos se pueden almacenar en varios formatos, como una base de datos o un sistema de archivos distribuido.
¿Cómo funciona un rastreador web?
Una vez comprendidos los elementos implicados, profundicemos en el procedimiento secuencial que aclara el funcionamiento de un rastreador web:
- URL inicial: el rastreador comienza con una URL inicial, que podría ser cualquier página web o una lista de URL. Esta URL se agrega a la frontera de URL para iniciar el proceso de rastreo.
- Obtención: el rastreador selecciona una URL de la frontera de URL y envía una solicitud HTTP al servidor web correspondiente. El servidor responde con el contenido de la página web, que luego es recuperado por el componente de descarga.
- Análisis: el analizador procesa la página web recuperada y extrae información relevante, como enlaces, texto y metadatos. También identifica y agrega nuevas URL encontradas en la página a la frontera de URL.
- Análisis de enlaces: el rastreador prioriza y agrega las URL extraídas a la frontera de URL en función de ciertos criterios como relevancia, actualidad o importancia. Esto ayuda a determinar el orden en el que el rastreador visitará y rastreará las páginas.
- Repetir proceso: el rastreador continúa el proceso seleccionando URL de la frontera de URL, obteniendo su contenido web, analizando las páginas y extrayendo más URL. Este proceso se repite hasta que no haya más URL para rastrear o hasta que se alcance un límite predefinido.
- Almacenamiento de datos: durante todo el proceso de rastreo, los datos recopilados se almacenan en el componente de almacenamiento de datos. Estos datos se pueden utilizar posteriormente para indexación, análisis u otros fines.
Tipos de rastreadores web
Los rastreadores web vienen en diferentes variaciones y tienen casos de uso específicos. A continuación se muestran algunos tipos de rastreadores web utilizados habitualmente:

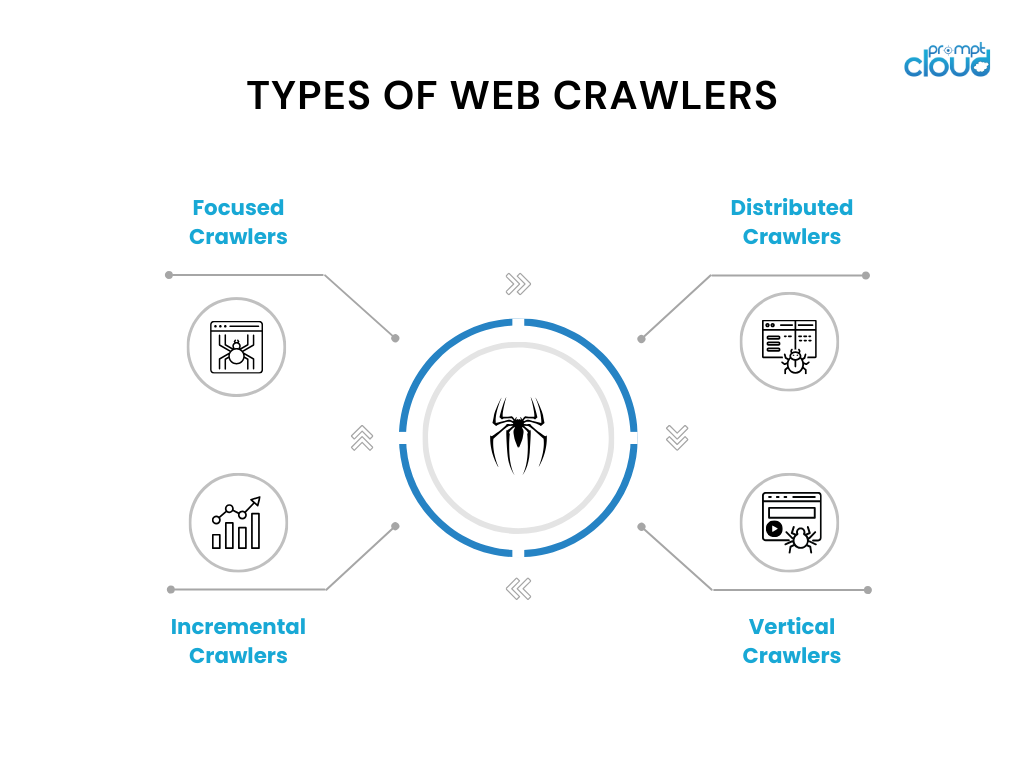
- Rastreadores enfocados: estos rastreadores operan dentro de un dominio o tema específico y rastrean páginas relevantes para ese dominio. Los ejemplos incluyen rastreadores de actualidad utilizados para sitios web de noticias o artículos de investigación.
- Rastreadores incrementales: los rastreadores incrementales se centran en rastrear contenido nuevo o actualizado desde el último rastreo. Utilizan técnicas como análisis de marcas de tiempo o algoritmos de detección de cambios para identificar y rastrear páginas modificadas.
- Rastreadores distribuidos: en los rastreadores distribuidos, varias instancias del rastreador se ejecutan en paralelo, compartiendo la carga de trabajo de rastrear una gran cantidad de páginas. Este enfoque permite un rastreo más rápido y una escalabilidad mejorada.
- Rastreadores verticales: los rastreadores verticales se dirigen a tipos específicos de contenido o datos dentro de páginas web, como imágenes, videos o información de productos. Están diseñados para extraer e indexar tipos específicos de datos para motores de búsqueda especializados.
¿Con qué frecuencia deberías rastrear páginas web?
La frecuencia de rastreo de páginas web depende de varios factores, incluido el tamaño y la frecuencia de actualización del sitio web, la importancia de las páginas y los recursos disponibles. Algunos sitios web pueden requerir un rastreo frecuente para garantizar que se indexe la información más reciente, mientras que otros pueden rastrearse con menos frecuencia.
Para sitios web con mucho tráfico o aquellos con contenido que cambia rápidamente, un rastreo más frecuente es esencial para mantener la información actualizada. Por otro lado, los sitios web más pequeños o las páginas con actualizaciones poco frecuentes se pueden rastrear con menos frecuencia, lo que reduce la carga de trabajo y los recursos necesarios.
Rastreador web interno frente a herramientas de rastreo web
Al contemplar la creación de un rastreador web, es fundamental evaluar la complejidad, la escalabilidad y los recursos necesarios. Construir un rastreador desde cero puede ser una tarea que requiere mucho tiempo y abarca actividades como la gestión de la concurrencia, la supervisión de sistemas distribuidos y la solución de obstáculos de infraestructura. Por otro lado, optar por marcos o herramientas de rastreo web puede ofrecer una resolución más rápida y efectiva.
Alternativamente, el uso de marcos o herramientas de rastreo web puede proporcionar una solución más rápida y eficiente. Estas herramientas ofrecen funciones como reglas de rastreo personalizables, capacidades de extracción de datos y opciones de almacenamiento de datos. Al aprovechar las herramientas existentes, los desarrolladores pueden centrarse en sus requisitos específicos, como el análisis de datos o la integración con otros sistemas.
Sin embargo, es fundamental considerar las limitaciones y los costos asociados con el uso de herramientas de terceros, como las restricciones de personalización, la propiedad de los datos y los posibles modelos de precios.
Conclusión
Los motores de búsqueda dependen en gran medida de los rastreadores web, que desempeñan un papel decisivo en la tarea de organizar y catalogar la extensa información presente en Internet. Comprender la mecánica, los componentes y las diversas categorías de los rastreadores web permite una comprensión más profunda de la intrincada tecnología que sustenta este proceso fundamental.
Ya sea que opte por construir un rastreador web desde cero o aprovechar herramientas preexistentes para el rastreo web, resulta imperativo adoptar un enfoque alineado con sus necesidades específicas. Esto implica considerar factores como la escalabilidad, la complejidad y los recursos a su disposición. Al tener en cuenta estos elementos, puede utilizar eficazmente el rastreo web para recopilar y analizar datos valiosos, impulsando así su negocio o sus esfuerzos de investigación .
En PromptCloud, nos especializamos en la extracción de datos web, obteniendo datos de recursos en línea disponibles públicamente. Póngase en contacto con nosotros en sales@promptcloud.com