
Cómo impedir que las IA rastreen su contenido
Publicado: 2023-10-24Las herramientas generativas de IA, como Google Bard y Bing Chat, se crean a partir de muchas fuentes de contenido, incluida la web. Para consternación de muchos, los motores de búsqueda han estado entrenando silenciosamente sus modelos de IA en todo el contenido que encuentran mientras rastrean la búsqueda web tradicional.
Bing y Google han anunciado métodos para impedir que el contenido se utilice para el entrenamiento de IA y al mismo tiempo permanezca indexado para la búsqueda web.
Entonces, ¿deberías bloquear las IA y cómo hacerlo?
- ¿Deberías bloquear las IA?
- ¿Cómo se bloquean los robots de IA?
- Cómo bloquear la IA de Bing
- Cómo bloquear la IA de Google
- Cómo bloquear ChatGPT
- Pruebas
¿Deberías bloquear las IA?
Las empresas que fabrican sus propios productos pueden considerar beneficioso incluir su contenido en modelos de IA. La información, como las especificaciones técnicas o el soporte del producto, puede ayudar con las ventas y reducir los costos de soporte al cliente.
Pero para muchas otras empresas online, el contenido es su producto. Existen preocupaciones válidas de que la energía invertida en la creación de contenidos se utilice para mejorar los productos de IA propiedad de las grandes empresas tecnológicas sin aportar ningún valor en forma de tráfico.
Google y Bing están tratando de encontrar formas de dar crédito a las fuentes y generar algo de tráfico de referencia, pero es probable que sea menos que la búsqueda web tradicional y más probable que sea transaccional que consultas de búsqueda informativas.
Es importante tener en cuenta que bloquear contenido de estas IA no afectará el comportamiento de rastreo. Google dice que "el token de agente de usuario robots.txt se utiliza con fines de control". Los robots rastrearán su sitio normalmente para crear sus índices de búsqueda.
Y si los motores de búsqueda ya no pueden rastrear ciertas páginas, no es necesario bloquearlas específicamente para las IA.
¿Cómo se bloquean los robots de IA?
Actualmente es posible bloquear Google, Bing y ChatGPT utilizando métodos familiares para la mayoría de los SEO, el archivo robots.txt y las directivas de robots a nivel de página.
Google y ChatGPT han optado por el método robots.txt que permite especificar patrones de URL, y Bing ha optado por utilizar directivas robots aplicadas a páginas individuales.
El archivo robots.txt tiene la ventaja de ser fácil de configurar para un sitio web completo en un solo lugar. Es muy transparente qué URL se bloquean en comparación con las directivas de robots a nivel de página, que deben probarse recuperando cada página.
Cómo bloquear la IA de Bing
Bing busca las directivas de robots nocache o noarchive, que se pueden agregar a una página como una metaetiqueta o en un encabezado de respuesta X-Robots-Tag.
Nocache permitirá que se incluyan páginas en las respuestas de Bing Chat utilizando solo URL, títulos y fragmentos en el entrenamiento de los modelos de inteligencia artificial de Microsoft.
Noarchive no permite que se incluyan páginas en Bing Chat y no se utilizará ningún contenido para entrenar los modelos de inteligencia artificial de Microsoft.
Si una página tiene Nocache y Noarchive, el Nocache menos restrictivo tendrá prioridad.
El token ' robots ' aplicará la directiva a todos los rastreadores. Esto incluye a Google, que evitará que la página aparezca con un enlace almacenado en caché en los resultados de búsqueda.
<meta nombre=”robots” contenido=”noarchive”>
Puedes utilizar los tokens ' bingbot ' o ' msnbot ' más específicos para evitar afectar a otros motores de búsqueda.
<meta nombre=”bingbot” contenido=”nocache”>
Cómo bloquear la IA de Google
Google ha optado por el método robots.txt que le permite especificar patrones de URL para que coincidan con las páginas que no desea que se utilicen en Bard y su equivalente API Vertex. Actualmente no se aplica a la experiencia generativa de búsqueda (SGE).
Compararán con un token de agente de usuario extendido por Google. El caso del token no importa.
Agente de usuario: Google extendido
No permitir: /
Si no hay un bloque de reglas específico para el token extendido de Google, coincidirá con el token comodín (*).

Agente de usuario: *
No permitir: /
Tenga cuidado si tiene un bloque de reglas específico para Googlebot y un bloque de comodines separado. Extendido por Google coincidirá con el bloque comodín, no con el bloque del robot de Google.
Agente de usuario: robot de Google
Permitir: /
Agente de usuario: *
No permitir: /
Puede enumerar varios agentes de usuario antes de que se bloquee la regla para ser más precisos.
Agente de usuario: Google extendido
Agente de usuario: robot de Google
Permitir: /
Agente de usuario: *
No permitir: /
Cómo bloquear ChatGPT
ChatGPT también optó por el método robots.txt.
Chat GPT tiene dos tokens de agente de usuario diferentes, ChatGPT-User para consultas en nombre de los usuarios de ChatGPT y GPTBot, que es el rastreador web de OpenAI utilizado para construir sus modelos.
Actualmente, el sistema de exclusión voluntaria trata a ambos agentes de usuario de la misma manera, por lo que cualquier archivo robots.txt que no se permita a un agente cubrirá a ambos. Esto puede cambiar en el futuro, por lo que recomendamos bloquearlos por separado.
Agente de usuario: GPTBot
Agente de usuario: Usuario de ChatGPT
No permitir: /
Pruebas
La prueba es sencilla si está bloqueando todo su sitio web.
Para verificar si Google y ChatGPT están bloqueados, debes ver si tu robots.txt tiene una regla de no permitir todo para los bots que deseas bloquear.
Agente de usuario: Google extendido
Agente de usuario: GPTbot
No permitir: /
Si solo desea bloquear algunas URL, es posible que necesite un conjunto más complejo de directivas robots.txt. Puede considerar probar varias URL que espera que estén bloqueadas y no bloqueadas.
Tomo es nuestra herramienta gratuita de robots.txt que puede ayudarle a comprobar si URL específicas están bloqueadas en robots.txt. Puede definir pruebas en forma de lista de URL y el estado no permitido esperado para cada URL.
Se puede configurar con los tokens de agente de usuario Google-Extended, GPTBot y ChatGPT-User para mostrarle qué URL están bloqueadas para cada una y si coinciden con el resultado de la prueba esperado.
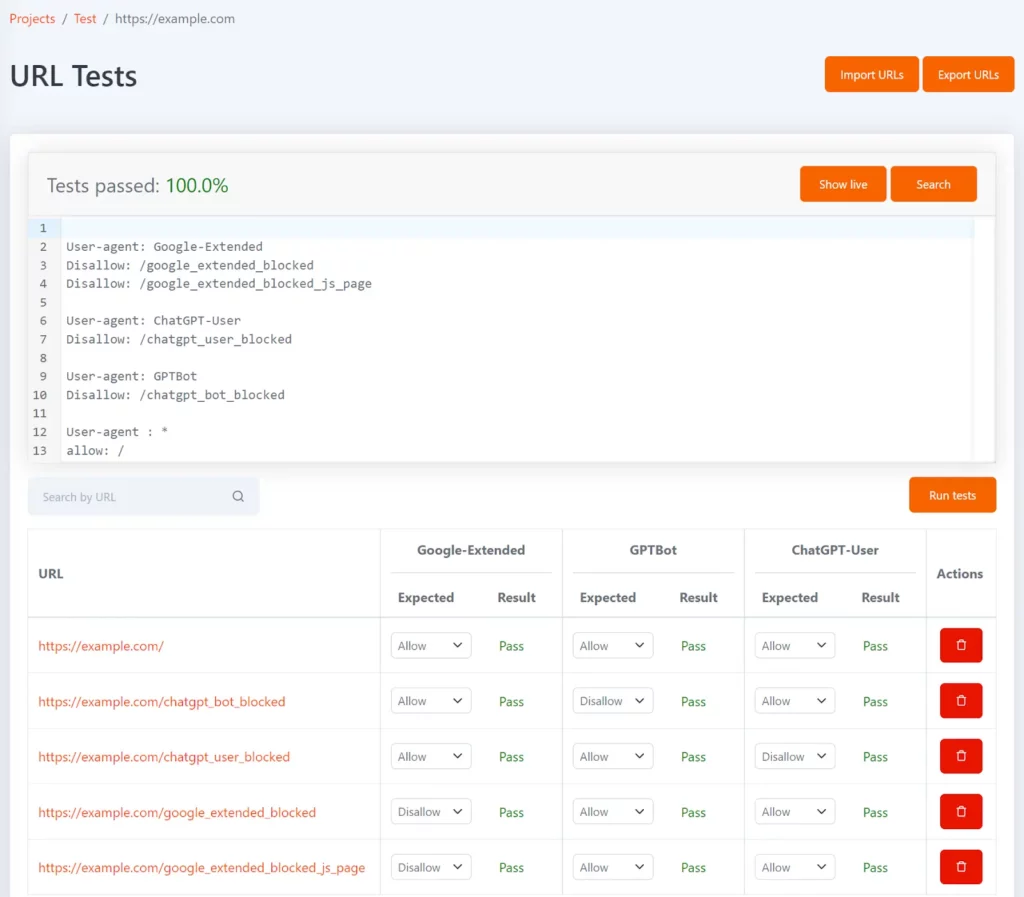
Siempre que se actualice su archivo robots.txt, las pruebas se volverán a ejecutar y se le notificará si los resultados no coinciden con lo esperado.
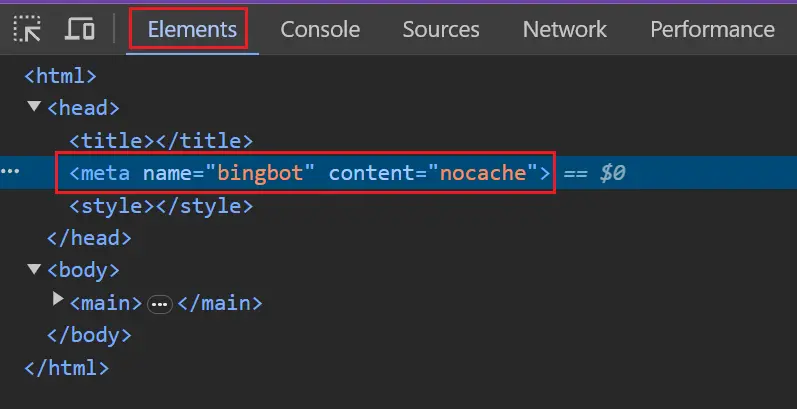
Para comprobar si Bing está bloqueado, puede inspeccionar las plantillas de páginas clave en el navegador y confirmar que tiene la etiqueta robots.
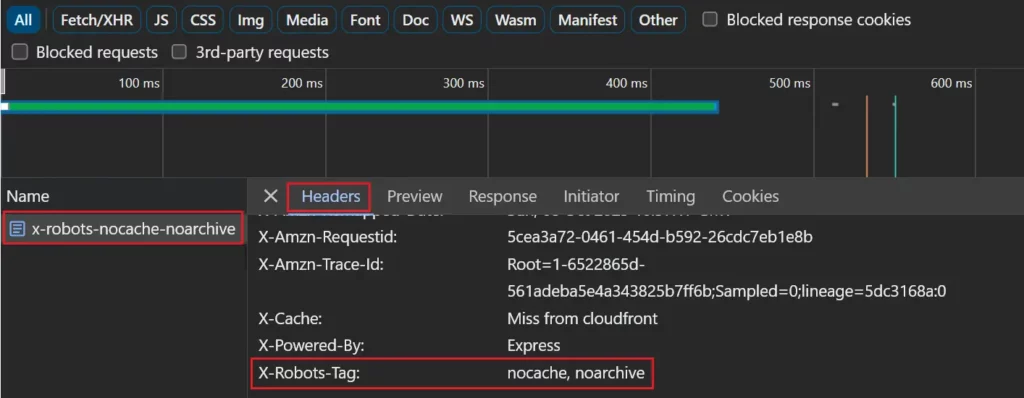
Si está utilizando un encabezado de respuesta X-Robots-Tag, se puede ver en la pestaña de red seleccionando la página en la lista de solicitudes de red y viendo la pestaña "Encabezados".
Las pruebas serán más complicadas si estás bloqueando un conjunto específico de páginas, pero existen algunas herramientas que pueden ayudar.
El rastreador Lumar ahora también informará automáticamente de todas las páginas donde las IA de Google y Bing estén bloqueadas.
¿Necesita soporte técnico adicional? ¡Conozca más sobre la oferta tecnológica de Semetrical o póngase en contacto para obtener más información!