
Dominar los scrapers de páginas web: una guía para principiantes para extraer datos en línea
Publicado: 2024-04-09¿Qué son los raspadores de páginas web?
El raspador de páginas web es una herramienta diseñada para extraer datos de sitios web. Simula la navegación humana para recopilar contenido específico. Los principiantes suelen aprovechar estos scrapers para diversas tareas, incluida la investigación de mercado, el seguimiento de precios y la recopilación de datos para proyectos de aprendizaje automático.
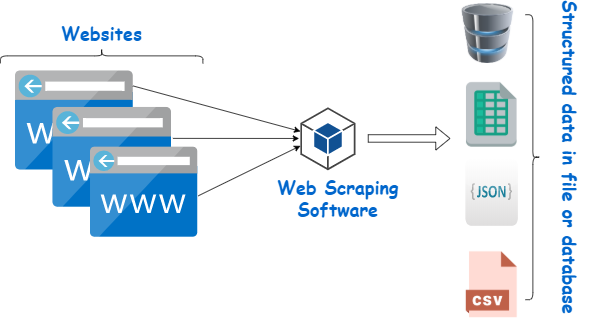
Fuente de la imagen: https://www.webharvy.com/articles/what-is-web-scraping.html
- Facilidad de uso: Son fáciles de usar, lo que permite a personas con habilidades técnicas mínimas capturar datos web de manera efectiva.
- Eficiencia: los scrapers pueden recopilar grandes cantidades de datos rápidamente, superando con creces los esfuerzos de recopilación de datos manuales.
- Precisión: el scraping automatizado reduce el riesgo de error humano, mejorando la precisión de los datos.
- Rentable: Eliminan la necesidad de entrada manual, ahorrando tiempo y costos de mano de obra.
Comprender la funcionalidad de los raspadores de páginas web es fundamental para cualquiera que busque aprovechar el poder de los datos web.
Crear un raspador de página web simple con Python
Para comenzar a crear un raspador de páginas web en Python, es necesario instalar ciertas bibliotecas, a saber, solicitudes para realizar solicitudes HTTP a una página web y BeautifulSoup de bs4 para analizar documentos HTML y XML.
- Herramientas de recolección:
- Bibliotecas: utilice solicitudes para buscar páginas web y BeautifulSoup para analizar el contenido HTML descargado.
- Orientación a la página web:
- Defina la URL de la página web que contiene los datos que queremos extraer.
- Descargando el contenido:
- Utilizando solicitudes, descargue el código HTML de la página web.
- Analizando el HTML:
- BeautifulSoup transformará el HTML descargado en un formato estructurado para facilitar la navegación.
- Extrayendo los datos:
- Identifique las etiquetas HTML específicas que contienen la información deseada (por ejemplo, títulos de productos dentro de etiquetas <div>).
- Utilizando los métodos de BeautifulSoup, extraiga y procese los datos que necesita.
Recuerde apuntar a elementos HTML específicos relevantes para la información que desea extraer.
Proceso paso a paso para raspar una página web
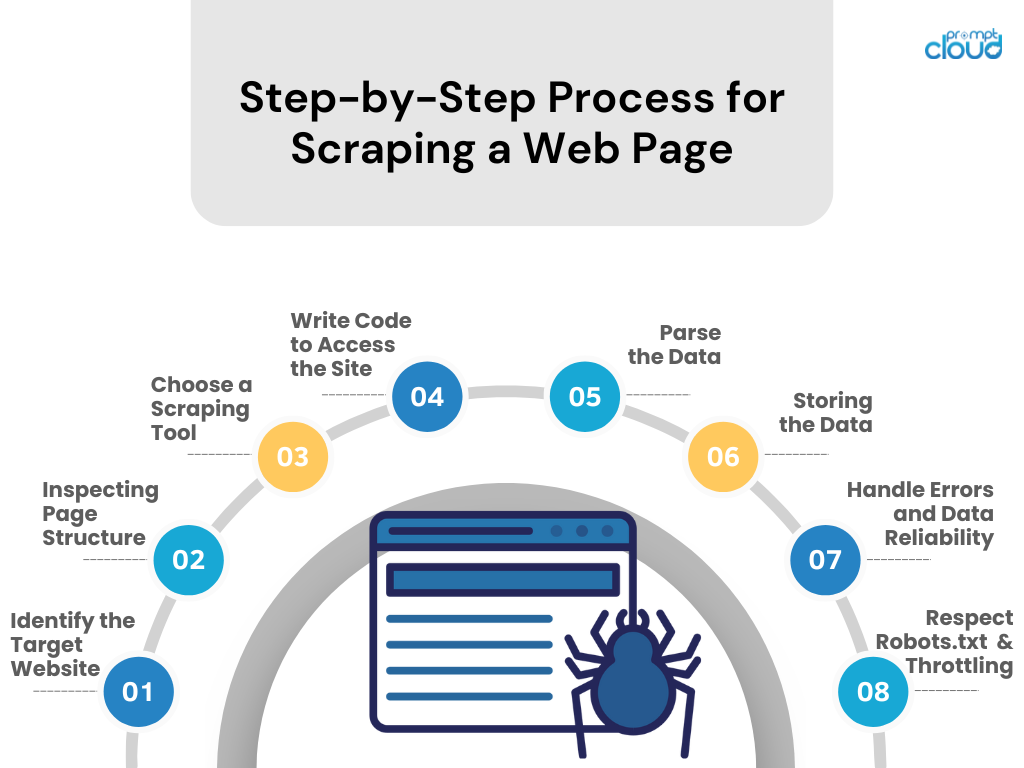
- Identificar el sitio web de destino
Investiga el sitio web que te gustaría eliminar. Asegúrese de que sea legal y ético hacerlo. - Inspeccionar la estructura de la página
Utilice las herramientas de desarrollo del navegador para examinar la estructura HTML, los selectores de CSS y el contenido basado en JavaScript. - Elija una herramienta de raspado
Seleccione una herramienta o biblioteca en un lenguaje de programación con el que se sienta cómodo (por ejemplo, BeautifulSoup o Scrapy de Python). - Escribir código para acceder al sitio
Cree un script que solicite datos del sitio web, utilizando llamadas API si están disponibles o solicitudes HTTP. - Analizar los datos
Extraiga los datos relevantes de la página web analizando HTML/CSS/JavaScript. - Almacenamiento de datos
Guarde los datos extraídos en un formato estructurado, como CSV, JSON o directamente en una base de datos. - Manejar errores y confiabilidad de los datos
Implemente el manejo de errores para gestionar fallas en las solicitudes y mantener la integridad de los datos. - Respete Robots.txt y aceleración
Siga las reglas del archivo robots.txt del sitio y evite saturar el servidor controlando la tasa de solicitudes.
Seleccionar las herramientas de Web Scraping ideales para sus necesidades
Al navegar por la web, es fundamental seleccionar herramientas alineadas con su competencia y objetivos. Los principiantes deberían considerar:
- Facilidad de uso: opte por herramientas intuitivas con asistencia visual y documentación clara.
- Requisitos de datos: evalúe la estructura y complejidad de los datos de destino para determinar si es necesaria una extensión simple o un software sólido.
- Presupuesto: compare el costo con las características; Muchos scrapers eficaces ofrecen niveles gratuitos.
- Personalización: asegúrese de que la herramienta sea adaptable a necesidades específicas de raspado.
- Soporte: el acceso a una útil comunidad de usuarios ayuda a solucionar problemas y mejorar.
Elija sabiamente para un viaje de raspado sin problemas.
Consejos y trucos para optimizar el raspador de su página web
- Utilice bibliotecas de análisis eficientes como BeautifulSoup o Lxml en Python para un procesamiento HTML más rápido.
- Implemente el almacenamiento en caché para evitar volver a descargar páginas y reducir la carga en el servidor.
- Respete los archivos robots.txt y utilice la limitación de velocidad para evitar que el sitio web de destino lo prohíba.
- Gire los agentes de usuario y los servidores proxy para imitar el comportamiento humano y evitar la detección.
- Programe scrapers durante las horas de menor actividad para minimizar el impacto en el rendimiento del sitio web.
- Opte por puntos finales API si están disponibles, ya que proporcionan datos estructurados y, en general, son más eficientes.
- Evite extraer datos innecesarios siendo selectivo con sus consultas, reduciendo el ancho de banda y el almacenamiento necesarios.
- Actualice periódicamente sus raspadores para adaptarse a los cambios en la estructura del sitio web y mantener la integridad de los datos.
Manejo de problemas comunes y solución de problemas en el scraping de páginas web
Al trabajar con raspadores de páginas web, los principiantes pueden enfrentar varios problemas comunes:

- Problemas con el selector : asegúrese de que los selectores coincidan con la estructura actual de la página web. Herramientas como las de desarrollo de navegadores pueden ayudar a identificar los selectores correctos.
- Contenido dinámico : algunas páginas web cargan contenido dinámicamente con JavaScript. En tales casos, considere utilizar navegadores sin cabeza o herramientas que representen JavaScript.
- Solicitudes bloqueadas : los sitios web pueden bloquear los raspadores. Emplee estrategias como rotar agentes de usuario, usar proxies y respetar robots.txt para mitigar el bloqueo.
- Problemas con el formato de datos : es posible que los datos extraídos necesiten limpieza o formateo. Utilice expresiones regulares y manipulación de cadenas para estandarizar los datos.
Recuerde consultar la documentación y los foros de la comunidad para obtener orientación específica para la solución de problemas.
Conclusión
Los principiantes ahora pueden recopilar datos de la web cómodamente a través del raspador de páginas web, lo que hace que la investigación y el análisis sean más eficientes. Comprender los métodos correctos y al mismo tiempo considerar los aspectos legales y éticos permite a los usuarios aprovechar todo el potencial del web scraping. Siga estas pautas para una introducción fluida al raspado de páginas web, llena de información valiosa y toma de decisiones informada.
Preguntas frecuentes:
¿Qué es raspar una página?
El web scraping, también conocido como data scraping o web Harvesting, consiste en extraer automáticamente datos de sitios web mediante programas informáticos que imitan los comportamientos de navegación humana. Con un raspador de páginas web, se pueden clasificar rápidamente grandes cantidades de información, centrándose únicamente en secciones importantes en lugar de compilarlas manualmente.
Las empresas aplican el web scraping para funciones como examinar costos, gestionar reputaciones, analizar tendencias y ejecutar análisis competitivos. La implementación de proyectos de web scraping garantiza verificar que los sitios web visitados aprueben la acción y el cumplimiento de todos los protocolos relevantes de robots.txt y no-follow.
¿Cómo puedo raspar una página completa?
Para extraer una página web completa, generalmente se necesitan dos componentes: una forma de ubicar los datos requeridos dentro de la página web y un mecanismo para guardar esos datos en otro lugar. Muchos lenguajes de programación admiten el web scraping, en particular Python y JavaScript.
Existen varias bibliotecas de código abierto para ambos, lo que simplifica aún más el proceso. Algunas opciones populares entre los desarrolladores de Python incluyen BeautifulSoup, Requests, LXML y Scrapy. Alternativamente, las plataformas comerciales como ParseHub y Octoparse permiten a personas menos técnicas crear visualmente flujos de trabajo complejos de web scraping. Después de instalar las bibliotecas necesarias y comprender los conceptos básicos detrás de la selección de elementos DOM, comience por identificar los puntos de datos de interés dentro de la página web de destino.
Utilice herramientas de desarrollo del navegador para inspeccionar etiquetas y atributos HTML y luego traduzca estos hallazgos a la sintaxis correspondiente compatible con la biblioteca o plataforma elegida. Por último, especifique las preferencias de formato de salida, ya sea CSV, Excel, JSON, SQL u otra opción, junto con los destinos donde residen los datos guardados.
¿Cómo uso el raspador de Google?
Contrariamente a la creencia popular, Google no ofrece directamente una herramienta pública de web scraping per se, a pesar de proporcionar API y SDK para facilitar una integración perfecta con múltiples productos. No obstante, desarrolladores capacitados han creado soluciones de terceros basadas en las tecnologías centrales de Google, expandiendo efectivamente las capacidades más allá de la funcionalidad nativa. Los ejemplos incluyen SerpApi, que abstrae aspectos complicados de Google Search Console y presenta una interfaz fácil de usar para el seguimiento de la clasificación de palabras clave, la estimación del tráfico orgánico y la exploración de vínculos de retroceso.
Si bien técnicamente son distintos del web scraping tradicional, estos modelos híbridos desdibujan las líneas que separan las definiciones convencionales. Otros casos muestran esfuerzos de ingeniería inversa aplicados para reconstruir la lógica interna que impulsa Google Maps Platform, YouTube Data API v3 o Google Shopping Services, generando funcionalidades notablemente cercanas a sus contrapartes originales, aunque sujetas a diversos grados de legalidad y riesgos de sostenibilidad. En última instancia, los aspirantes a raspadores de páginas web deben explorar diversas opciones y evaluar los méritos en relación con los requisitos específicos antes de comprometerse con un camino determinado.
¿Es legal el raspador de Facebook?
Como se indica en las Políticas para desarrolladores de Facebook, el web scraping no autorizado constituye una clara violación de los estándares de su comunidad. Los usuarios aceptan no desarrollar ni operar aplicaciones, scripts u otros mecanismos diseñados para eludir o exceder los límites de velocidad API designados, ni intentarán descifrar, descompilar ni realizar ingeniería inversa en ningún aspecto del Sitio o Servicio. Además, destaca las expectativas en torno a la protección de datos y la privacidad, al requerir el consentimiento explícito del usuario antes de compartir información de identificación personal fuera de los contextos permitidos.
Cualquier incumplimiento de los principios descritos desencadena una escalada de medidas disciplinarias que comienzan con advertencias y avanzan progresivamente hacia el acceso restringido o la revocación completa de privilegios, según los niveles de gravedad. A pesar de las excepciones establecidas para los investigadores de seguridad que operan bajo programas aprobados de recompensas por errores, el consenso general aboga por evitar iniciativas no autorizadas de raspado de Facebook para evitar complicaciones innecesarias. En su lugar, considere buscar alternativas compatibles con las normas y convenciones vigentes respaldadas por la plataforma.