
Superar los desafíos técnicos en Web Scraping: soluciones expertas
Publicado: 2024-03-29El web scraping es una práctica que conlleva numerosos desafíos técnicos, incluso para los mineros de datos experimentados. Implica el uso de técnicas de programación para obtener y recuperar datos de sitios web, lo que no siempre es fácil debido a la naturaleza compleja y variada de las tecnologías web.
Además, muchos sitios web cuentan con medidas de protección para evitar la recopilación de datos, lo que hace que sea esencial para los scrapers negociar mecanismos anti-scraping, contenido dinámico y estructuras complicadas del sitio.
A pesar de que el objetivo de adquirir información útil parece sencillo rápidamente, lograrlo requiere superar varias barreras formidables, lo que exige fuertes capacidades analíticas y técnicas.
Manejo de contenido dinámico
El contenido dinámico, que se refiere a la información de la página web que se actualiza en función de las acciones del usuario o se carga después de la vista inicial de la página, comúnmente plantea desafíos para las herramientas de web scraping.
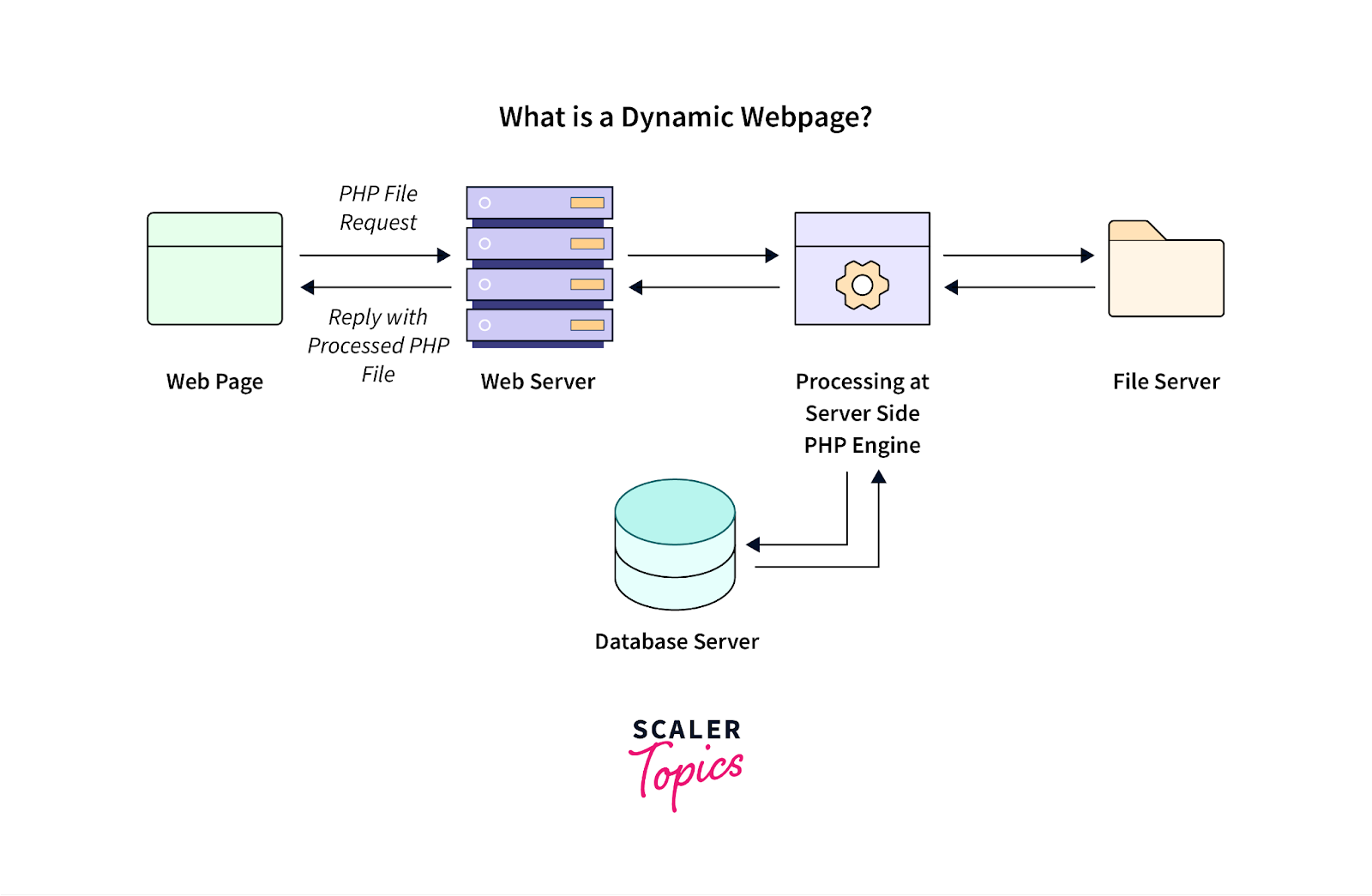
Fuente de la imagen: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
Este tipo de contenido dinámico se utiliza con frecuencia en aplicaciones web contemporáneas creadas con marcos de JavaScript. Para administrar y extraer con éxito datos de dicho contenido generado dinámicamente, considere estas mejores prácticas:
- Considere el uso de herramientas de automatización web como Selenium, Puppeteer o Playwright, que permiten que su web scraper se comporte en la página web de manera similar a como lo haría un usuario genuino.
- Implementar técnicas de manejo de WebSockets o AJAX si el sitio web utiliza estas tecnologías para cargar contenido de forma dinámica.
- Espere a que se carguen los elementos utilizando esperas explícitas en su código de extracción para asegurarse de que el contenido esté completamente cargado antes de intentar extraerlo.
- Explore utilizando navegadores sin cabeza que pueden ejecutar JavaScript y representar la página completa, incluido el contenido cargado dinámicamente.
Al dominar estas estrategias, los scrapers pueden extraer datos de manera efectiva incluso de los sitios web más interactivos y que cambian dinámicamente.
Tecnologías anti-raspado
Es común que los desarrolladores web implementen medidas destinadas a evitar la extracción de datos no aprobados para salvaguardar sus sitios web. Estas medidas pueden plantear desafíos importantes para los web scrapers. A continuación se presentan varios métodos y estrategias para navegar a través de tecnologías anti-scraping:

Fuente de la imagen: https://kinsta.com/knowledgebase/what-is-web-scraping/
- Factoring dinámico : los sitios web pueden generar contenido dinámicamente, lo que dificulta la predicción de URL o estructuras HTML. Utilice herramientas que puedan ejecutar JavaScript y manejar solicitudes AJAX.
- Bloqueo de IP : las solicitudes frecuentes de la misma IP pueden provocar bloqueos. Utilice un grupo de servidores proxy para rotar las IP e imitar patrones de tráfico humano.
- CAPTCHA : están diseñados para distinguir entre humanos y bots. Aplique servicios de resolución de CAPTCHA u opte por la entrada manual si es posible.
- Limitación de tarifas : para evitar superar los límites de tarifas, limite las tarifas de sus solicitudes e implemente retrasos aleatorios entre las solicitudes.
- Agente de usuario : los sitios web pueden bloquear agentes de usuario raspadores conocidos. Gire los agentes de usuario para imitar diferentes navegadores o dispositivos.
Superar estos desafíos requiere un enfoque sofisticado que respete los términos de servicio del sitio web y al mismo tiempo acceda de manera eficiente a los datos necesarios.
Lidiar con CAPTCHA y trampas Honeypot
Los web scrapers a menudo encuentran desafíos CAPTCHA diseñados para distinguir a los usuarios humanos de los bots. Superar esto requiere:
- Utilizar servicios de resolución de CAPTCHA que aprovechen las capacidades humanas o de inteligencia artificial.
- Implementar retrasos y aleatorizar solicitudes para imitar el comportamiento humano.
Para trampas de honeypot, que son invisibles para los usuarios pero atrapan scripts automatizados:
- Inspeccione cuidadosamente el código del sitio web para evitar la interacción con enlaces ocultos.
- Emplear prácticas de scraping menos agresivas para permanecer fuera del radar.
Los desarrolladores deben equilibrar éticamente la eficacia con el respeto a los términos del sitio web y la experiencia del usuario.
Eficiencia de raspado y optimización de la velocidad
Los procesos de web scraping se pueden mejorar optimizando tanto la eficiencia como la velocidad. Para superar los desafíos en este ámbito:
- Utilice subprocesos múltiples para permitir la extracción simultánea de datos, aumentando el rendimiento.
- Aproveche los navegadores sin cabeza para una ejecución más rápida eliminando la carga innecesaria de contenido gráfico.
- Optimice el código de raspado para ejecutarlo con una latencia mínima.
- Implemente una limitación de solicitudes adecuada para evitar prohibiciones de propiedad intelectual y, al mismo tiempo, mantener un ritmo estable.
- Almacene en caché el contenido estático para evitar descargas repetidas, conservando el ancho de banda y el tiempo.
- Emplear técnicas de programación asincrónica para optimizar las operaciones de E/S de la red.
- Elija selectores y bibliotecas de análisis eficientes para reducir la sobrecarga de la manipulación DOM.
Al incorporar estas estrategias, los web scrapers pueden lograr un rendimiento sólido con inconvenientes operativos minimizados.

Extracción y análisis de datos
El web scraping requiere extracción y análisis precisos de datos, lo que presenta distintos desafíos. He aquí formas de abordarlos:
- Utilice bibliotecas sólidas como BeautifulSoup o Scrapy, que pueden manejar varias estructuras HTML.
- Implemente expresiones regulares con cautela para apuntar a patrones específicos con precisión.
- Aproveche las herramientas de automatización del navegador como Selenium para interactuar con sitios web con mucho JavaScript, garantizando que los datos se representen antes de la extracción.
- Adopte selectores XPath o CSS para identificar con precisión los elementos de datos dentro del DOM.
- Maneje la paginación y el desplazamiento infinito identificando y manipulando el mecanismo que carga contenido nuevo (por ejemplo, actualizando los parámetros de URL o manejando llamadas AJAX).
Dominar el arte del web scraping
El web scraping es una habilidad invaluable en el mundo basado en datos. Superar desafíos técnicos, que van desde contenido dinámico hasta detección de bots, requiere perseverancia y adaptabilidad. El web scraping exitoso implica una combinación de estos enfoques:
- Implemente rastreo inteligente para respetar los recursos del sitio web y navegar sin ser detectado.
- Utilice análisis avanzado para manejar contenido dinámico, garantizando que la extracción de datos sea sólida frente a los cambios.
- Emplee estratégicamente servicios de resolución de CAPTCHA para mantener el acceso sin interrumpir el flujo de datos.
- Administre cuidadosamente las direcciones IP y solicite encabezados para disfrazar las actividades de scraping.
- Maneje los cambios en la estructura del sitio web actualizando periódicamente los scripts del analizador.
Al dominar estas técnicas, uno puede navegar con destreza por las complejidades del rastreo web y desbloquear grandes almacenes de datos valiosos.
Gestión de proyectos de scraping a gran escala
Los proyectos de web scraping a gran escala requieren una gestión sólida para garantizar la eficiencia y el cumplimiento. Asociarse con proveedores de servicios de web scraping ofrece varias ventajas:

Confiar proyectos de scraping a profesionales puede optimizar los resultados y minimizar la tensión técnica de su equipo interno.
Preguntas frecuentes
¿Cuáles son las limitaciones del web scraping?
El web scraping enfrenta ciertas limitaciones que uno debe considerar antes de incorporarlo a sus operaciones. Legalmente, algunos sitios web no permiten el scraping mediante términos y condiciones o archivos robot.txt; ignorar estas restricciones podría tener graves consecuencias.
Técnicamente, los sitios web pueden implementar contramedidas contra el scraping, como CAPTCHA, bloques de IP y Honey Pots, evitando así el acceso no autorizado. La precisión de los datos extraídos también puede convertirse en un problema debido a la representación dinámica y las fuentes actualizadas con frecuencia. Por último, el web scraping requiere conocimientos técnicos, inversión en recursos y esfuerzo continuo, lo que presenta desafíos, especialmente para las personas sin conocimientos técnicos.
¿Por qué la extracción de datos es un problema?
Los problemas surgen principalmente cuando la extracción de datos se produce sin los permisos necesarios o sin una conducta ética. La extracción de información confidencial viola las normas de privacidad y transgrede los estatutos diseñados para salvaguardar los intereses individuales.
El uso excesivo de scraping afecta a los servidores, lo que afecta negativamente el rendimiento y la disponibilidad. El robo de propiedad intelectual constituye otra preocupación que surge del scraping ilícito debido a posibles demandas por violación de derechos de autor iniciadas por las partes agraviadas.
Por lo tanto, cumplir con las estipulaciones políticas, defender los estándares éticos y buscar el consentimiento cuando sea necesario sigue siendo crucial al realizar tareas de extracción de datos.
¿Por qué el web scraping puede ser inexacto?
El web scraping, que consiste en extraer automáticamente datos de sitios web mediante software especializado, no garantiza una precisión total debido a varios factores. Por ejemplo, las modificaciones en la estructura del sitio web podrían provocar que la herramienta de raspado no funcione correctamente o capture información errónea.
Además, ciertos sitios web implementan medidas anti-scraping, como pruebas CAPTCHA, bloqueos de IP o representación de JavaScript, lo que genera datos perdidos o distorsionados. En ocasiones, los descuidos de los desarrolladores durante la creación también contribuyen a resultados subóptimos.
Sin embargo, asociarse con proveedores de servicios de web scraping competentes puede reforzar la precisión, ya que aportan los conocimientos y los activos necesarios para construir scrapers resilientes y ágiles capaces de mantener altos niveles de precisión a pesar de los cambios en los diseños de los sitios web. Expertos cualificados prueban y validan meticulosamente estos raspadores antes de su implementación, garantizando la corrección durante todo el proceso de extracción.
¿Es tedioso el web scraping?
De hecho, participar en actividades de web scraping puede resultar laborioso y exigente, especialmente para quienes carecen de experiencia en codificación o comprensión de las plataformas digitales. Estas tareas requieren elaborar códigos personalizados, rectificar raspadores defectuosos, administrar arquitecturas de servidores y mantenerse al tanto de las modificaciones que se producen en los sitios web específicos, todo lo cual requiere capacidades técnicas considerables junto con inversiones sustanciales en términos de tiempo.
Ampliar más allá de las tareas básicas de web scraping se vuelve cada vez más complejo dadas las consideraciones sobre el cumplimiento normativo, la gestión del ancho de banda y la implementación de sistemas informáticos distribuidos.
Por el contrario, optar por servicios profesionales de web scraping reduce sustancialmente las cargas asociadas a través de ofertas listas para usar diseñadas de acuerdo con las demandas específicas del usuario. En consecuencia, los clientes se concentran principalmente en aprovechar los datos recopilados y, al mismo tiempo, dejan la logística de recopilación a equipos dedicados compuestos por desarrolladores capacitados y especialistas en TI responsables de la optimización del sistema, la asignación de recursos y la resolución de consultas legales, lo que reduce notablemente el tedio general relacionado con las iniciativas de web scraping.