
Rastreador web Python: tutorial paso a paso
Publicado: 2023-12-07Los rastreadores web son herramientas fascinantes en el mundo de la recopilación de datos y el web scraping. Automatizan el proceso de navegación por la web para recopilar datos, que pueden utilizarse para diversos fines, como indexación en motores de búsqueda, extracción de datos o análisis competitivo. En este tutorial, nos embarcaremos en un viaje informativo para crear un rastreador web básico utilizando Python, un lenguaje conocido por su simplicidad y poderosas capacidades para manejar datos web.
Python, con su rico ecosistema de bibliotecas, proporciona una excelente plataforma para desarrollar rastreadores web. Si es un desarrollador en ciernes, un entusiasta de los datos o simplemente tiene curiosidad sobre cómo funcionan los rastreadores web, esta guía paso a paso está diseñada para presentarle los conceptos básicos del rastreo web y brindarle las habilidades para crear su propio rastreador. .
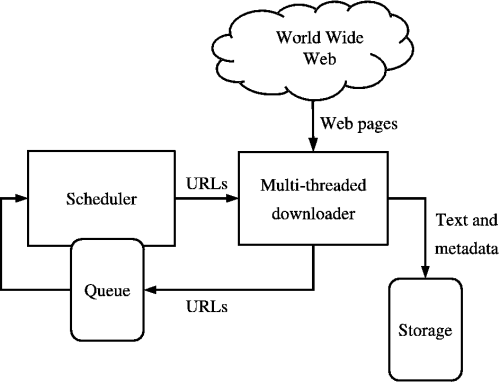
Fuente: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Rastreador web Python: cómo crear un rastreador web
Paso 1: comprender los conceptos básicos
Un rastreador web, también conocido como araña, es un programa que navega por la World Wide Web de forma metódica y automatizada. Para nuestro rastreador, usaremos Python debido a su simplicidad y potentes bibliotecas.
Paso 2: configure su entorno
Instalar Python : asegúrese de tener Python instalado. Puedes descargarlo desde python.org.
Instalar bibliotecas : necesitará solicitudes para realizar solicitudes HTTP y BeautifulSoup de bs4 para analizar HTML. Instálalos usando pip:
solicitudes de instalación de pip instalación de pip beautifulsoup4
Paso 3: escribir un rastreador básico
Importar bibliotecas :
solicitudes de importación desde bs4 import BeautifulSoup
Obtener una página web :
Aquí, buscaremos el contenido de una página web. Reemplace 'URL' con la página web que desea rastrear.
url = 'URL' respuesta = solicitudes.get(url) contenido = respuesta.contenido
Analizar el contenido HTML :
sopa = BeautifulSoup(contenido, 'html.parser')
Extraer información :
Por ejemplo, para extraer todos los hipervínculos, puede hacer:
para enlace en sopa.find_all('a'): print(link.get('href'))
Paso 4: expanda su rastreador
Manejo de URL relativas :
Utilice urljoin para manejar URL relativas.
desde urllib.parse importar urljoin
Evite rastrear la misma página dos veces :
Mantenga un conjunto de URL visitadas para evitar redundancias.
Agregar retrasos :
El rastreo respetuoso incluye retrasos entre solicitudes. Utilice time.sleep().
Paso 5: Respeta el archivo Robots.txt
Asegúrese de que su rastreador respete el archivo robots.txt de los sitios web, que indica qué partes del sitio no deben rastrearse.
Paso 6: Manejo de errores
Implemente bloques try-except para manejar errores potenciales como tiempos de espera de conexión o acceso denegado.
Paso 7: profundizar
Puede mejorar su rastreador para manejar tareas más complejas, como envíos de formularios o representación de JavaScript. Para sitios web con mucho JavaScript, considere usar Selenium.
Paso 8: almacene los datos
Decide cómo almacenar los datos que has rastreado. Las opciones incluyen archivos simples, bases de datos o incluso enviar datos directamente a un servidor.
Paso 9: Sea ético
- No sobrecargue los servidores; agregue retrasos en sus solicitudes.
- Siga los términos de servicio del sitio web.
- No extraiga ni almacene datos personales sin permiso.
Quedarse bloqueado es un desafío común cuando se rastrea una web, especialmente cuando se trata de sitios web que cuentan con medidas para detectar y bloquear el acceso automatizado. Aquí hay algunas estrategias y consideraciones que lo ayudarán a resolver este problema en Python:
Comprender por qué te bloquean
Solicitudes frecuentes: las solicitudes rápidas y repetidas desde la misma IP pueden provocar el bloqueo.
Patrones no humanos: los bots a menudo exhiben un comportamiento distinto de los patrones de navegación humanos, como acceder a páginas demasiado rápido o en una secuencia predecible.
Mala gestión de encabezados: los encabezados HTTP faltantes o incorrectos pueden hacer que sus solicitudes parezcan sospechosas.
Ignorar robots.txt: no cumplir con las directivas del archivo robots.txt de un sitio puede provocar bloqueos.
Estrategias para evitar el bloqueo
Respetar robots.txt : Siempre revisa y cumple con el archivo robots.txt del sitio web. Es una práctica ética y puede evitar bloqueos innecesarios.
Agentes de usuario rotativos : los sitios web pueden identificarlo a través de su agente de usuario. Al rotarlo, reduce el riesgo de ser marcado como bot. Utilice la biblioteca fake_useragent para implementar esto.
de fake_useragent importar UserAgent ua = UserAgent() encabezados = {'User-Agent': ua.random}
Agregar retrasos : implementar un retraso entre solicitudes puede imitar el comportamiento humano. Utilice time.sleep() para agregar un retraso fijo o aleatorio.

importar tiempo time.sleep(3) # Espera 3 segundos
Rotación de IP : si es posible, utilice servicios de proxy para rotar su dirección IP. Hay servicios tanto gratuitos como de pago disponibles para esto.
Uso de sesiones : un objeto request.Session en Python puede ayudar a mantener una conexión consistente y compartir encabezados, cookies, etc., entre solicitudes, haciendo que su rastreador se parezca más a una sesión de navegador normal.
con request.Session() como sesión: session.headers = {'User-Agent': ua.random} respuesta = session.get(url)
Manejo de JavaScript : algunos sitios web dependen en gran medida de JavaScript para cargar contenido. Herramientas como Selenium o Puppeteer pueden imitar un navegador real, incluida la representación de JavaScript.
Manejo de errores : implemente un manejo sólido de errores para administrar y responder a bloques u otros problemas con elegancia.
Consideraciones éticas
- Respete siempre los términos de servicio de un sitio web. Si un sitio prohíbe explícitamente el web scraping, es mejor cumplirlo.
- Tenga en cuenta el impacto que tiene su rastreador en los recursos del sitio web. La sobrecarga de un servidor puede causar problemas al propietario del sitio.
Técnicas avanzadas
- Marcos de web scraping : considere usar marcos como Scrapy, que tienen funciones integradas para manejar diversos problemas de rastreo.
- Servicios de resolución de CAPTCHA : para sitios con desafíos de CAPTCHA, existen servicios que pueden resolver CAPTCHA, aunque su uso plantea preocupaciones éticas.
Mejores prácticas de rastreo web en Python
Participar en actividades de rastreo web requiere un equilibrio entre eficiencia técnica y responsabilidad ética. Al utilizar Python para el rastreo web, es importante seguir las mejores prácticas que respeten los datos y los sitios web de los que provienen. A continuación se presentan algunas consideraciones clave y mejores prácticas para el rastreo web en Python:
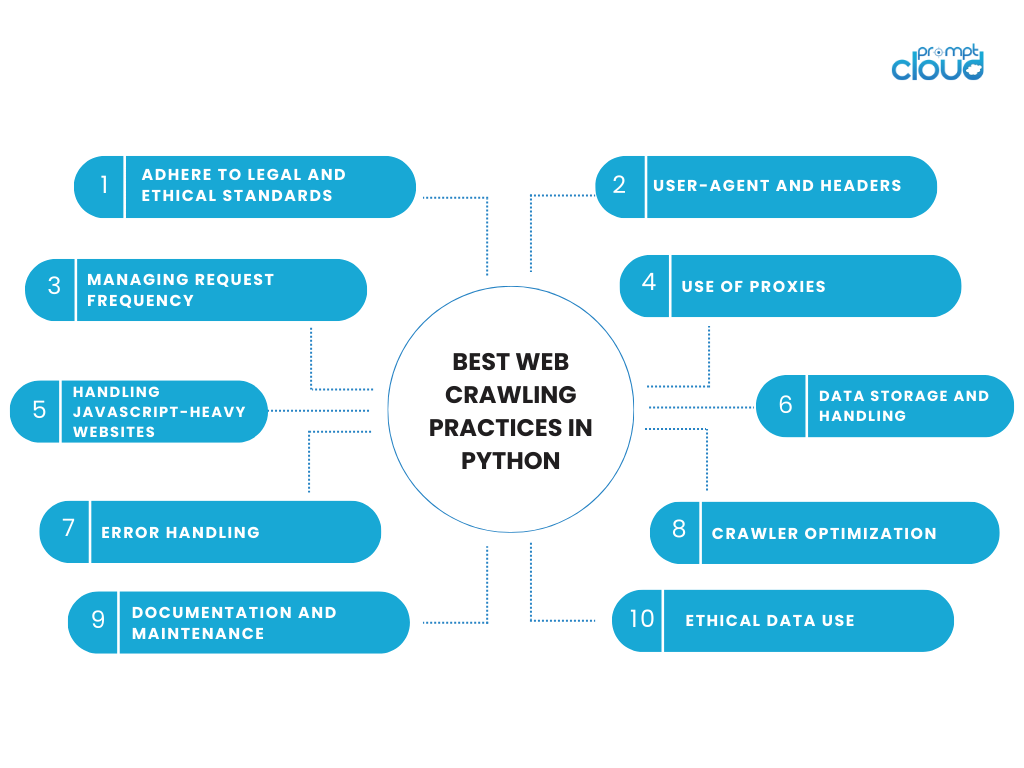
Adherirse a los estándares legales y éticos
- Respete el archivo robots.txt: compruebe siempre el archivo robots.txt del sitio web. Este archivo describe las áreas del sitio que el propietario del sitio web prefiere que no se rastreen.
- Siga los Términos de servicio: muchos sitios web incluyen cláusulas sobre web scraping en sus términos de servicio. Respetar estos términos es ético y legalmente prudente.
- Evite sobrecargar los servidores: realice solicitudes a un ritmo razonable para evitar sobrecargar el servidor del sitio web.
Agente de usuario y encabezados
- Identifíquese: utilice una cadena de agente de usuario que incluya su información de contacto o el propósito de su rastreo. Esta transparencia puede generar confianza.
- Utilice los encabezados de forma adecuada: los encabezados HTTP bien configurados pueden reducir la probabilidad de ser bloqueado. Pueden incluir información como agente de usuario, idioma de aceptación, etc.
Administrar la frecuencia de las solicitudes
- Agregar retrasos: implemente un retraso entre solicitudes para imitar los patrones de navegación humana. Utilice la función time.sleep() de Python.
- Limitación de velocidad: tenga en cuenta cuántas solicitudes envía a un sitio web dentro de un período de tiempo determinado.
Uso de poderes
- Rotación de IP: el uso de servidores proxy para rotar su dirección IP puede ayudar a evitar el bloqueo basado en IP, pero debe hacerse de manera responsable y ética.
Manejo de sitios web con mucho JavaScript
- Contenido dinámico: para sitios que cargan contenido dinámicamente con JavaScript, herramientas como Selenium o Puppeteer (en combinación con Pyppeteer para Python) pueden representar las páginas como un navegador.
Almacenamiento y manejo de datos
- Almacenamiento de datos: almacene los datos rastreados de manera responsable, considerando las leyes y regulaciones de privacidad de datos.
- Minimice la extracción de datos: extraiga solo los datos que necesita. Evite recopilar información personal o sensible a menos que sea absolutamente necesario y legal.
Manejo de errores
- Manejo sólido de errores: implemente un manejo integral de errores para gestionar problemas como tiempos de espera, errores del servidor o contenido que no se carga.
Optimización del rastreador
- Escalabilidad: diseñe su rastreador para manejar un aumento en escala, tanto en términos de la cantidad de páginas rastreadas como de la cantidad de datos procesados.
- Eficiencia: Optimice su código para lograr eficiencia. El código eficiente reduce la carga tanto en su sistema como en el servidor de destino.
Documentación y Mantenimiento
- Guarde la documentación: documente su código y la lógica de rastreo para referencia y mantenimiento futuros.
- Actualizaciones periódicas: mantenga actualizado su código de rastreo, especialmente si cambia la estructura del sitio web de destino.
Uso ético de datos
- Utilización ética: utilice los datos que ha recopilado de manera ética, respetando la privacidad del usuario y las normas de uso de datos.
En conclusión
Al concluir nuestra exploración de la creación de un rastreador web en Python, hemos recorrido las complejidades de la recopilación automatizada de datos y las consideraciones éticas que la acompañan. Este esfuerzo no solo mejora nuestras habilidades técnicas sino que también profundiza nuestra comprensión del manejo responsable de datos en el vasto panorama digital.
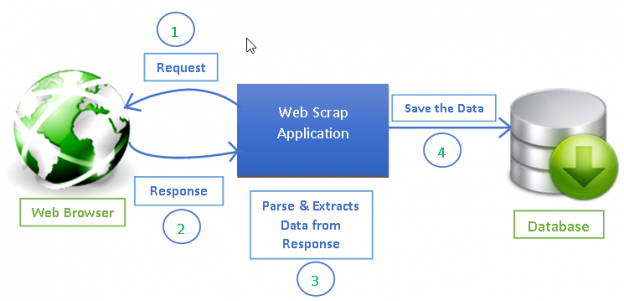
Fuente: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Sin embargo, crear y mantener un rastreador web puede ser una tarea compleja y que requiere mucho tiempo, especialmente para empresas con necesidades de datos específicas a gran escala. Aquí es donde entran en juego los servicios de web scraping personalizados de PromptCloud. Si está buscando una solución personalizada, eficiente y ética para sus requisitos de datos web, PromptCloud ofrece una variedad de servicios que se adaptan a sus necesidades únicas. Desde manejar sitios web complejos hasta proporcionar datos limpios y estructurados, garantizan que sus proyectos de web scraping sean sencillos y estén alineados con sus objetivos comerciales.
Para las empresas y las personas que tal vez no tengan el tiempo o la experiencia técnica para desarrollar y administrar sus propios rastreadores web, subcontratar esta tarea a expertos como PromptCloud puede cambiar las reglas del juego. Sus servicios no solo ahorran tiempo y recursos, sino que también garantizan que usted obtenga los datos más precisos y relevantes, al mismo tiempo que cumplen con los estándares legales y éticos.
¿Está interesado en obtener más información sobre cómo PromptCloud puede satisfacer sus necesidades de datos específicas? Comuníquese con ellos en sales@promptcloud.com para obtener más información y analizar cómo sus soluciones de web scraping personalizadas pueden ayudarlo a impulsar su negocio.
En el dinámico mundo de los datos web, contar con un socio confiable como PromptCloud puede potenciar su negocio y brindarle la ventaja en la toma de decisiones basada en datos. Recuerde, en el ámbito de la recopilación y el análisis de datos, el socio adecuado marca la diferencia.
¡Feliz búsqueda de datos!