
Selección y configuración de motores de inferencia para LLM
Publicado: 2024-04-02Introducción a los motores de inferencia
Existen muchas técnicas de optimización desarrolladas para mitigar las ineficiencias que ocurren en las diferentes etapas del proceso de inferencia. Es difícil escalar la inferencia a escala con técnicas/transformadores básicos. Los motores de inferencia agrupan las optimizaciones en un solo paquete y nos facilitan el proceso de inferencia.
Para un conjunto muy pequeño de pruebas ad hoc o una referencia rápida, podemos usar el código básico del transformador para hacer la inferencia.
El panorama de los motores de inferencia está evolucionando rápidamente, ya que tenemos múltiples opciones, es importante probar y hacer una lista corta de lo mejor para casos de uso específicos. A continuación, se muestran algunos experimentos con motores de inferencia que realizamos y las razones por las que descubrimos por qué funcionó en nuestro caso.
Para nuestro modelo Vicuña-7B afinado, hemos probado
- TGI
- vllm
- Afrodita
- Optimum-Nvidia
- Inferir energía
- LLAMACPP
- Ctranslate2
Revisamos la página de github y su guía de inicio rápido para configurar estos motores. PowerInfer, LlaamaCPP, Ctranslate2 no son muy flexibles y no admiten muchas técnicas de optimización como procesamiento por lotes continuo, atención paginada y rendimiento inferior al promedio en comparación con otros motores mencionados. .
Para obtener un mayor rendimiento, el motor/servidor de inferencia debe maximizar la memoria y las capacidades informáticas y tanto el cliente como el servidor deben trabajar de forma paralela/asincrónica para atender solicitudes para mantener el servidor siempre en funcionamiento. Como se mencionó anteriormente, sin la ayuda de técnicas de optimización como PagedAttention, Flash Attention y el procesamiento por lotes continuo, siempre conducirá a un rendimiento subóptimo.
TGI, vLLM y Aphrodite son candidatos más adecuados en este sentido y, al realizar múltiples experimentos que se detallan a continuación, encontramos la configuración óptima para obtener el máximo rendimiento de la inferencia. Técnicas como el procesamiento por lotes continuo y la atención paginada están habilitadas de forma predeterminada; la decodificación especulativa debe habilitarse manualmente en el motor de inferencia para las siguientes pruebas.
Análisis comparativo de motores de inferencia
TGI
Para usar TGI, podemos ir a la sección 'Comenzar' de la página de github, aquí Docker es la forma más sencilla de configurar y usar el motor TGI.
Argumentos del iniciador de generación de texto -> esta lista muestra diferentes configuraciones que podemos usar en el lado del servidor. Pocos importantes,
- –max-input-length : determina la longitud máxima de entrada al modelo, esto requiere cambios en la mayoría de los casos, ya que el valor predeterminado es 1024.
- –max-total-tokens: máximo tokens totales, es decir, longitud del token de entrada + salida.
- –speculate, –quantiz, –max-concurrent-requests -> el valor predeterminado es solo 128, que obviamente es menos.
Para iniciar un modelo local ajustado,
docker run –gpus dispositivo=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Para iniciar un modelo desde hub,
modelo=”lmsys/vicuña-7b-v1.5″; volumen=$PWD/datos; token="<hf_token>"; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Puede pedirle a chatGPT que le explique el comando anterior para una comprensión más detallada. Aquí estamos iniciando el servidor de inferencia en el puerto 9091. Y podemos usar un cliente de cualquier idioma para publicar una solicitud en el servidor. API de inferencia de generación de texto -> menciona todos los puntos finales y parámetros de carga útil para realizar solicitudes.
P.ej
carga útil =”<mensaje aquí>”
curl -XPOST “0.0.0.0:9091/generar” -H “Tipo de contenido: aplicación/json” -d “{“entradas”: $carga útil, “parámetros”: {“max_new_tokens”: 400”,do_sample”:false ,”best_of”: nulo,”repetition_penalty”: 1,”return_full_text”: false,”seed”: null,”stop_sequences”: null,”temperatura”: 0.1,”top_k”: 100,”top_p”: 0.3,” truncar”: nulo”, “típico_p”: nulo”, “marca de agua”: falso”, “decoder_input_details”: falso}}”
Pocas observaciones,
- La latencia aumenta con max-token-tokens, lo cual es obvio que, si procesamos texto largo, el tiempo total aumentará.
- Especular ayuda, pero depende del caso de uso y de la distribución de entrada y salida.
- La cuantificación de Eetq es la que más ayuda a aumentar el rendimiento.
- Si tiene una GPU múltiple, ejecutar 1 API en cada GPU y tener estas API de GPU múltiples detrás de un equilibrador de carga da como resultado un rendimiento mayor que la fragmentación realizada por TGI.
vllm
Para iniciar un servidor vLLM, podemos utilizar un servidor/acoplador API REST compatible con OpenAI. Es muy sencillo comenzar, siga Implementación con Docker - vLLM, si va a usar un modelo local, luego adjunte el volumen y use la ruta como nombre del modelo.
docker run –runtime nvidia –gpus dispositivo=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – modelo /modelo
Arriba se iniciará un servidor vLLM en el puerto 8000 mencionado, como siempre puedes jugar con argumentos.
Realizar solicitud de publicación con,
“`cáscara
carga útil =”<mensaje aquí>”
curl -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “Tipo de contenido: aplicación/json” -d “{“prompt”: $carga útil”,modelo”:”/modelo”, max_tokens ”: 400,”top_p”: 0.3, “top_k”: 100, “temperatura”: 0.1}”
“`
Afrodita
“`cáscara
pip install motor-afrodita
python -m aphrodite.endpoints.openai.api_server –modelo PygmalionAI/pygmalion-2-7b
“`
O
“`
docker run -v /ruta/a/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus dispositivo=1 –ipc host alpindale/aphrodite-engine

“`
Aphrodite proporciona la instalación de pip y docker como se menciona en la sección de introducción. Docker es generalmente relativamente más fácil de poner en marcha y probar. Opciones de uso, las opciones del servidor nos ayudan a realizar solicitudes.
- Aphrodite y vLLM utilizan cargas útiles basadas en servidor openAI, por lo que puede consultar su documentación.
- Probamos deepspeed-mii, dado que se encuentra en un estado de transición (cuando lo intentamos) del código base heredado al nuevo, no parece confiable ni fácil de usar.
- Optimum-NVIDIA no admite otras optimizaciones importantes y da como resultado un rendimiento subóptimo, enlace de referencia.
- Se agregó una esencia, el código que usamos para realizar las solicitudes paralelas ad hoc.
Métricas y medidas
Queremos probar y encontrar:
- Óptimo no. de subprocesos para el cliente/servidor del motor de inferencia.
- Cómo crece el rendimiento frente al aumento de la memoria
- Cómo crece el rendimiento con respecto a los núcleos tensoriales.
- Efecto de los subprocesos frente a las solicitudes paralelas por parte del cliente.
Una forma muy básica de observar la utilización es observarla a través de las utilidades de Linux nvidia-smi, nvtop, esto nos indicará la memoria ocupada, la utilización de cómputo, la velocidad de transferencia de datos, etc.
Otra forma es perfilar el proceso usando GPU con nsys.
| S.No | GPU | Memoria RAM | Máquina de inferencia | Hilos | Tiempo (s) | Especular |
| 1 | A6000 | 48/48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48/48GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48/48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48/48GB | TGI | 256 | 568 | – |
Según los experimentos anteriores, 128/256 subprocesos es mejor que un número de subprocesos más bajo y más allá de 256 la sobrecarga comienza a contribuir a un rendimiento reducido. Se descubre que esto depende de la CPU y la GPU, y necesita su propio experimento. | ||||||
| 5 | A6000 | 48/48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48/48GB | TGI | 128 | 945 | 8 |
Un valor especulativo más alto provoca más rechazos para nuestro modelo ajustado y, por lo tanto, reduce el rendimiento. 1/2 como valor especulado está bien, esto está sujeto al modelo y no se garantiza que funcione igual en todos los casos de uso. Pero la conclusión es que la decodificación especulativa mejora el rendimiento. | ||||||
| 7 | 3090 | 24/24GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24GB | TGI | 128 | 481 | 2 |
Aunque el 4090 tiene menos vRAM en comparación con el A6000, supera debido al mayor número de núcleos tensoriales y la velocidad del ancho de banda de la memoria. | ||||||
| 8 | A6000 | 24/48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2x24/48GB | TGI | 128 | 1205 | 2 |
Instalación y configuración de TGI para alto rendimiento
Configure solicitudes asincrónicas en un lenguaje de secuencias de comandos de su elección como python/ruby y use el mismo archivo para la configuración que encontramos:
- El tiempo necesario aumenta con respecto a la longitud máxima de salida de la generación de secuencia.
- 128/256 subprocesos en el cliente y el servidor es mejor que 24, 64, 512. Cuando se utilizan subprocesos inferiores, la computación se infrautiliza y, más allá de un umbral como 128, la sobrecarga aumenta y, por lo tanto, el rendimiento se reduce.
- Hay una mejora del 6 % al pasar de solicitudes asincrónicas a solicitudes paralelas usando 'GNU paralelo' en lugar de subprocesos en lenguajes como Go, Python/Ruby.
- 4090 tiene un rendimiento un 12% mayor que A6000. Aunque el 4090 tiene menos vRAM en comparación con el A6000, supera debido al mayor número de núcleos tensoriales y la velocidad del ancho de banda de la memoria.
- Dado que el A6000 tiene 48 GB de vRAM, para concluir si la RAM adicional ayuda a mejorar el rendimiento o no, intentamos usar fracciones de memoria de GPU en el experimento 8 de la tabla; vemos que la RAM adicional ayuda a mejorar, pero no de forma lineal. Además, cuando se intenta dividir, es decir, alojar 2 API en la misma GPU usando la mitad de la memoria para cada API, se comporta como 2 API secuenciales en ejecución, en lugar de aceptar solicitudes en paralelo.
Observaciones y métricas
A continuación se muestran gráficos de algunos experimentos y el tiempo necesario para completar un conjunto de entradas fijo; cuanto menor sea el tiempo necesario, mejor.
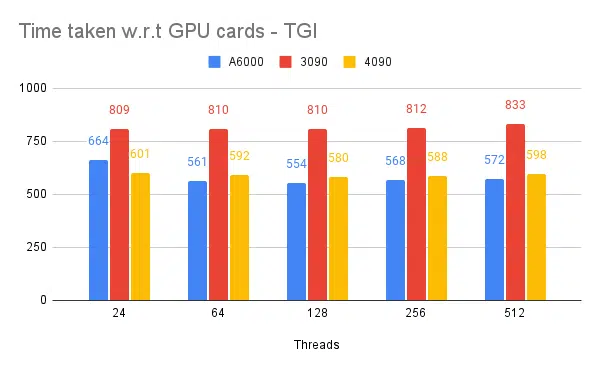
- Se mencionan los hilos del lado del cliente. Del lado del servidor debemos mencionarlo al iniciar el motor de inferencia.
Pruebas especulativas:

Pruebas de múltiples motores de inferencia:
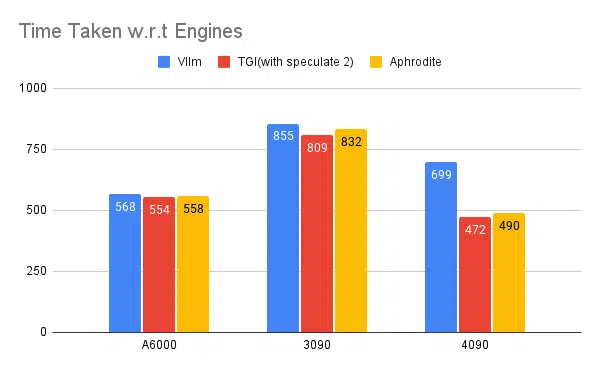
Con el mismo tipo de experimentos realizados con otros motores como vLLM y Aphrodite, observamos resultados similares. Al escribir este artículo, vLLM y Aphrodite aún no admiten la decodificación especulativa, lo que nos deja elegir TGI, ya que ofrece un mayor rendimiento que el resto. a la decodificación especulativa.
Además, puede configurar perfiladores de GPU para mejorar la observabilidad, lo que ayuda a identificar áreas con uso excesivo de recursos y optimiza el rendimiento. Lectura adicional: Herramientas para desarrolladores de Nvidia Nsight: Max Katz
Conclusión
Vemos que el panorama de la generación de inferencias evoluciona constantemente y mejorar el rendimiento en LLM requiere una buena comprensión de la GPU, las métricas de rendimiento, las técnicas de optimización y los desafíos asociados con las tareas de generación de texto. Esto ayuda a elegir las herramientas adecuadas para el trabajo. Al comprender los aspectos internos de la GPU y cómo se corresponden con la inferencia LLM, como aprovechar los núcleos tensoriales y maximizar el ancho de banda de la memoria, los desarrolladores pueden elegir la GPU rentable y optimizar el rendimiento de manera efectiva.
Las diferentes tarjetas GPU ofrecen distintas capacidades y comprender las diferencias es fundamental para seleccionar el hardware más adecuado para tareas específicas. Técnicas como el procesamiento por lotes continuo, la atención paginada, la fusión del núcleo y la atención flash ofrecen soluciones prometedoras para superar los desafíos que surgen y mejorar la eficiencia. TGI parece la mejor opción para nuestro caso de uso según los experimentos y resultados que obtenemos.
Lea otros artículos relacionados con el modelo de lenguaje grande:
Comprensión de la arquitectura de GPU para la optimización de inferencia de LLM
Técnicas avanzadas para mejorar el rendimiento de LLM