
Guía paso a paso para crear un rastreador web
Publicado: 2023-12-05En el intrincado entramado de Internet, donde la información está dispersa en innumerables sitios web, los rastreadores web emergen como héroes anónimos, que trabajan diligentemente para organizar, indexar y hacer accesible esta gran cantidad de datos. Este artículo se embarca en una exploración de los rastreadores web, arroja luz sobre su funcionamiento fundamental, distingue entre rastreo web y raspado web y proporciona información práctica, como una guía paso a paso para crear un rastreador web sencillo basado en Python. A medida que profundicemos, descubriremos las capacidades de herramientas avanzadas como Scrapy y descubriremos cómo PromptCloud eleva el rastreo web a una escala industrial.
¿Qué es un rastreador web?
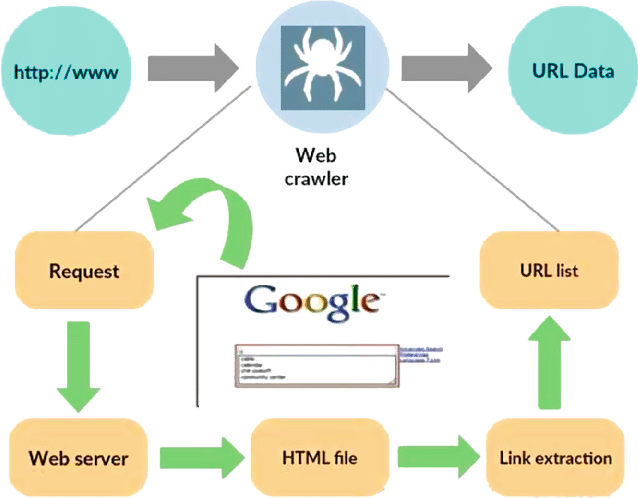
Fuente: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Un rastreador web, también conocido como araña o robot, es un programa especializado diseñado para navegar de forma sistemática y autónoma por la vasta extensión de la World Wide Web. Su función principal es recorrer sitios web, recopilar datos e indexar información para diversos fines, como optimización de motores de búsqueda, indexación de contenido o extracción de datos.
En esencia, un rastreador web imita las acciones de un usuario humano, pero a un ritmo mucho más rápido y eficiente. Comienza su viaje desde un punto de partida designado, a menudo denominado URL inicial, y luego sigue hipervínculos de una página web a otra. Este proceso de seguir enlaces es recursivo, lo que permite al rastreador explorar una parte importante de Internet.
A medida que el rastreador visita páginas web, extrae y almacena sistemáticamente datos relevantes, que pueden incluir texto, imágenes, metadatos y más. Luego, los datos extraídos se organizan e indexan, lo que facilita a los motores de búsqueda recuperar y presentar información relevante a los usuarios cuando la consultan.
Los rastreadores web desempeñan un papel fundamental en la funcionalidad de motores de búsqueda como Google, Bing y Yahoo. Al rastrear la web de forma continua y sistemática, garantizan que los índices de los motores de búsqueda estén actualizados, proporcionando a los usuarios resultados de búsqueda precisos y relevantes. Además, los rastreadores web se utilizan en otras aplicaciones, incluida la agregación de contenidos, la supervisión de sitios web y la extracción de datos.
La eficacia de un rastreador web depende de su capacidad para navegar por diversas estructuras de sitios web, manejar contenido dinámico y respetar las reglas establecidas por los sitios web a través del archivo robots.txt, que describe qué partes de un sitio se pueden rastrear. Comprender cómo funcionan los rastreadores web es fundamental para apreciar su importancia a la hora de hacer accesible y organizada la vasta red de información.
Cómo funcionan los rastreadores web
Los rastreadores web, también conocidos como arañas o bots, operan mediante un proceso sistemático de navegación por la World Wide Web para recopilar información de sitios web. A continuación se ofrece una descripción general de cómo funcionan los rastreadores web:
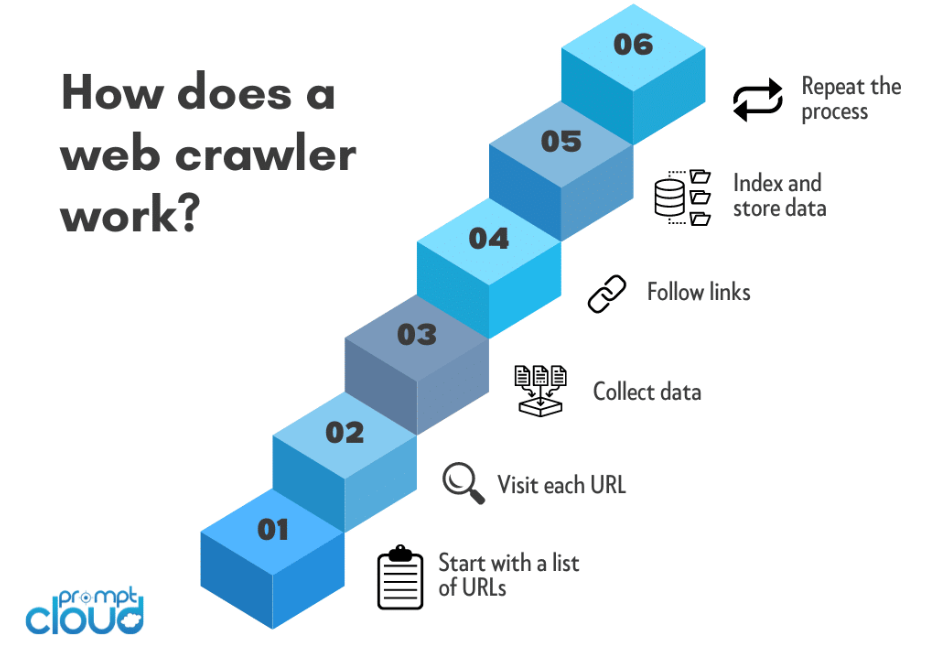
Selección de URL inicial:
El proceso de rastreo web normalmente comienza con una URL inicial. Esta es la página web o sitio web inicial desde donde el rastreador comienza su viaje.
Solicitud HTTP:
El rastreador envía una solicitud HTTP a la URL inicial para recuperar el contenido HTML de la página web. Esta solicitud es similar a las solicitudes realizadas por los navegadores web al acceder a un sitio web.
Análisis HTML:
Una vez que se recupera el contenido HTML, el rastreador lo analiza para extraer información relevante. Esto implica dividir el código HTML en un formato estructurado que el rastreador pueda navegar y analizar.
Extracción de URL:
El rastreador identifica y extrae hipervínculos (URL) presentes en el contenido HTML. Estas URL representan enlaces a otras páginas que el rastreador visitará posteriormente.
Cola y programador:
Las URL extraídas se agregan a una cola o programador. La cola garantiza que el rastreador visite las URL en un orden específico y, a menudo, prioriza primero las URL nuevas o no visitadas.
Recursión:
El rastreador sigue los enlaces en la cola, repitiendo el proceso de enviar solicitudes HTTP, analizar contenido HTML y extraer nuevas URL. Este proceso recursivo permite al rastreador navegar a través de múltiples capas de páginas web.
Extracción de datos:
A medida que el rastreador recorre la web, extrae datos relevantes de cada página visitada. El tipo de datos extraídos depende del propósito del rastreador y puede incluir texto, imágenes, metadatos u otro contenido específico.
Indexación de contenido:
Los datos recopilados están organizados e indexados. La indexación implica la creación de una base de datos estructurada que facilita la búsqueda, recuperación y presentación de información cuando los usuarios envían consultas.
Respetando Robots.txt:
Los rastreadores web suelen cumplir las reglas especificadas en el archivo robots.txt de un sitio web. Este archivo proporciona pautas sobre qué áreas del sitio se pueden rastrear y cuáles deben excluirse.
Retrasos en el rastreo y cortesía:
Para evitar sobrecargar los servidores y causar interrupciones, los rastreadores suelen incorporar mecanismos de cortesía y retrasos en el rastreo. Estas medidas garantizan que el rastreador interactúe con los sitios web de manera respetuosa y no disruptiva.
Los rastreadores web navegan sistemáticamente por la web, siguen enlaces, extraen datos y crean un índice organizado. Este proceso permite a los motores de búsqueda ofrecer resultados precisos y relevantes a los usuarios en función de sus consultas, lo que convierte a los rastreadores web en un componente fundamental del ecosistema moderno de Internet.

Rastreo web versus raspado web

Fuente: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Si bien el rastreo web y el web scraping a menudo se usan indistintamente, tienen propósitos distintos. El rastreo web implica navegar sistemáticamente por la web para indexar y recopilar información, mientras que el web scraping se centra en extraer datos específicos de las páginas web. En esencia, el rastreo web consiste en explorar y mapear la web, mientras que el web scraping consiste en recopilar información específica.
Construyendo un rastreador web
Crear un rastreador web simple en Python implica varios pasos, desde configurar el entorno de desarrollo hasta codificar la lógica del rastreador. A continuación se muestra una guía detallada que le ayudará a crear un rastreador web básico utilizando Python, utilizando la biblioteca de solicitudes para realizar solicitudes HTTP y BeautifulSoup para el análisis de HTML.
Paso 1: configurar el entorno
Asegúrese de tener Python instalado en su sistema. Puedes descargarlo desde python.org. Además, deberá instalar las bibliotecas necesarias:
pip install requests beautifulsoup4
Paso 2: importar bibliotecas
Cree un nuevo archivo Python (por ejemplo, simple_crawler.py) e importe las bibliotecas necesarias:
import requests from bs4 import BeautifulSoup
Paso 3: definir la función del rastreador
Cree una función que tome una URL como entrada, envíe una solicitud HTTP y extraiga información relevante del contenido HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Paso 4: prueba el rastreador
Proporcione una URL de muestra y llame a la función simple_crawler para probar el rastreador:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Paso 5: ejecute el rastreador
Ejecute el script Python en su terminal o símbolo del sistema:
python simple_crawler.py
El rastreador buscará el contenido HTML de la URL proporcionada, lo analizará e imprimirá el título. Puede ampliar el rastreador agregando más funciones para extraer diferentes tipos de datos.
Rastreo web con Scrapy
El rastreo web con Scrapy abre la puerta a un marco potente y flexible diseñado específicamente para un rastreo web eficiente y escalable. Scrapy simplifica las complejidades de la creación de rastreadores web, ofreciendo un entorno estructurado para crear arañas que pueden navegar por sitios web, extraer datos y almacenarlos de manera sistemática. He aquí un vistazo más de cerca al rastreo web con Scrapy:
Instalación:
Antes de comenzar, asegúrese de tener Scrapy instalado. Puedes instalarlo usando:
pip install scrapy
Creando un proyecto Scrapy:
Iniciar un proyecto Scrapy:
Abra una terminal y navegue hasta el directorio donde desea crear su proyecto Scrapy. Ejecute el siguiente comando:
scrapy startproject your_project_name
Esto crea una estructura básica del proyecto con los archivos necesarios.
Definir la araña:
Dentro del directorio del proyecto, navegue hasta la carpeta de arañas y cree un archivo Python para su araña. Defina una clase de araña subclasificando scrapy.Spider y proporcionando detalles esenciales como nombre, dominios permitidos y URL de inicio.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Extrayendo datos:
Usando selectores:
Scrapy utiliza potentes selectores para extraer datos de HTML. Puede definir selectores en el método de análisis de la araña para capturar elementos específicos.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Este ejemplo extrae el contenido de texto de la etiqueta <title>.
Siguientes enlaces:
Scrapy simplifica el proceso de seguir enlaces. Utilice el siguiente método para navegar a otras páginas.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Ejecutando la araña:
Ejecute su araña usando el siguiente comando desde el directorio del proyecto:
scrapy crawl your_spider
Scrapy iniciará la araña, seguirá los enlaces y ejecutará la lógica de análisis definida en el método de análisis.
El rastreo web con Scrapy ofrece un marco sólido y extensible para manejar tareas complejas de raspado. Su arquitectura modular y sus funciones integradas lo convierten en la opción preferida de los desarrolladores que participan en proyectos sofisticados de extracción de datos web.
Rastreo web a escala
El rastreo web a escala presenta desafíos únicos, especialmente cuando se trata de una gran cantidad de datos distribuidos en numerosos sitios web. PromptCloud es una plataforma especializada diseñada para agilizar y optimizar el proceso de rastreo web a escala. Así es como PromptCloud puede ayudar a manejar iniciativas de rastreo web a gran escala:
- Escalabilidad
- Extracción y enriquecimiento de datos
- Calidad y precisión de los datos
- Gestión de infraestructura
- Facilidad de uso
- Cumplimiento y Ética
- Monitoreo e informes en tiempo real
- Soporte y Mantenimiento
PromptCloud es una solución sólida para organizaciones e individuos que buscan realizar rastreo web a escala. Al abordar los desafíos clave asociados con la extracción de datos a gran escala, la plataforma mejora la eficiencia, confiabilidad y capacidad de administración de las iniciativas de rastreo web.
En resumen
Los rastreadores web son héroes anónimos en el vasto panorama digital y navegan diligentemente por la web para indexar, recopilar y organizar información. A medida que se expande la escala de los proyectos de rastreo web, PromptCloud interviene como una solución que ofrece escalabilidad, enriquecimiento de datos y cumplimiento ético para agilizar iniciativas a gran escala. Póngase en contacto con nosotros en sales@promptcloud.com