
El papel del Web Scraping en la mejora de la precisión del modelo de IA
Publicado: 2023-12-27La IA evoluciona constantemente, impulsada por la inmensa cantidad de datos necesarios para perfeccionar el aprendizaje automático. Este proceso de aprendizaje implica reconocer patrones y tomar decisiones informadas.
Ingrese al web scraping, un actor vital en la búsqueda de datos. Implica extraer una gran cantidad de información de sitios web, un tesoro escondido para entrenar modelos de IA. La armonía entre la IA y el web scraping subraya la esencia basada en datos del aprendizaje automático contemporáneo. A medida que avanza la IA, aumenta el hambre por conjuntos de datos variados, lo que convierte al web scraping en un activo indispensable para los desarrolladores que crean sistemas de IA más nítidos y eficientes.
La evolución del Web Scraping: del manual al mejorado con IA
El desarrollo del web scraping refleja los avances tecnológicos. Los primeros métodos eran básicos y requerían la extracción manual de datos, una tarea que a menudo requería mucho tiempo y era propensa a errores. A medida que Internet se expandió rápidamente, estas técnicas no pudieron seguir el ritmo del creciente volumen de datos. Se introdujeron scripts y bots para automatizar el scraping, pero carecían de sofisticación.
Ingrese a la IA de web scraping, que revoluciona la recolección de datos. El aprendizaje automático ahora permite analizar datos complejos y no estructurados, dándoles sentido de manera eficiente. Este cambio no solo acelera la recopilación de datos, sino que también mejora la calidad de los datos extraídos, permitiendo aplicaciones más sofisticadas y proporcionando un terreno de alimentación más rico para los modelos de IA que aprenden continuamente de conjuntos de datos vastos y matizados.
Fuente de la imagen: https://www.scrapingdog.com/
Comprender las tecnologías de inteligencia artificial en el web scraping
Gracias a la inteligencia artificial, las herramientas de web scraping se han vuelto más poderosas. La IA automatiza el reconocimiento de patrones en la extracción de datos, lo que la hace más rápida y precisa a la hora de identificar información relevante. Los web scrapers impulsados por IA pueden:
- Adáptese a diferentes diseños de sitios web mediante el aprendizaje automático, reduciendo así la necesidad de diseñar plantillas manualmente.
- Emplee procesamiento de lenguaje natural (NLP) para comprender y categorizar datos basados en texto, mejorando la calidad de los datos recopilados.
- Utilice capacidades de reconocimiento de imágenes para extraer contenido visual, lo que puede ser fundamental en determinados contextos de análisis de datos.
- Implemente algoritmos de detección de anomalías para identificar y gestionar valores atípicos o errores de extracción de datos, garantizando la integridad de los datos.
Con el poder de la IA, el web scraping se vuelve más potente y adaptable, cumpliendo con los amplios requisitos de datos de los modelos avanzados de IA actuales.
El papel del aprendizaje automático en la extracción inteligente de datos
El aprendizaje automático revoluciona la extracción de datos al permitir que los sistemas reconozcan, comprendan y extraigan información relevante de forma independiente. Las contribuciones clave incluyen:
- Reconocimiento de patrones : los algoritmos de aprendizaje automático se destacan en el reconocimiento de patrones y anomalías en grandes conjuntos de datos, lo que los hace ideales para identificar puntos de datos relevantes durante el web scraping.
- Procesamiento del lenguaje natural (PNL) : al utilizar PNL, el aprendizaje automático puede comprender e interpretar el lenguaje humano, facilitando la extracción de información de fuentes de datos no estructurados como las redes sociales.
- Aprendizaje adaptativo : a medida que los modelos de aprendizaje automático están expuestos a más datos, aprenden y mejoran su precisión, lo que garantiza que el proceso de extracción de datos se vuelva más eficiente con el tiempo.
- Reducción del error humano : con el aprendizaje automático, la probabilidad de errores asociados con la extracción manual de datos se reduce significativamente, lo que mejora la calidad del conjunto de datos para los modelos de IA.
Fuente de la imagen: https://research.aimultiple.com/
Reconocimiento de patrones impulsado por IA para un raspado eficiente
El web scraping juega un papel vital para satisfacer la creciente demanda de datos en modelos de aprendizaje automático. A la vanguardia de esto se encuentra el reconocimiento de patrones impulsado por IA, que agiliza la extracción de datos con una eficiencia notable. Esta técnica avanzada identifica y clasifica grandes cantidades de datos con una mínima participación humana.
Aprovechando algoritmos complejos, la IA de web scraping navega rápidamente a través de páginas web, reconociendo patrones y extrayendo conjuntos de datos estructurados. Estos sistemas automatizados no solo funcionan más rápido sino que también mejoran significativamente la precisión, minimizando los errores en comparación con los métodos de raspado manual. A medida que la IA evolucione, su capacidad para discernir patrones intrincados seguirá remodelando el panorama del web scraping y la adquisición de datos.
Procesamiento de lenguaje natural para agregación de contenido
La función crucial del procesamiento del lenguaje natural (PNL) pasa a primer plano en la agregación de contenidos, permitiendo a los sistemas de inteligencia artificial comprender, interpretar y organizar datos de manera eficiente. Dota a los raspadores con la capacidad de discernir información relevante de conversaciones irrelevantes. Al analizar la semántica y la sintáctica del texto, la PNL clasifica el contenido, extrae entidades clave y resume la información.

Estos datos destilados se convierten en el material de capacitación fundamental para los modelos que aprenden a reconocer patrones, anticipar las consultas de los usuarios y brindar respuestas reveladoras. En consecuencia, la agregación de contenidos impulsada por la PNL es fundamental para desarrollar modelos de IA más inteligentes y conscientes del contexto. Facilita un enfoque específico en la recopilación de datos, refinando la entrada sin procesar que alimenta el insaciable apetito de datos de la IA contemporánea.
Superar captchas y desafíos de contenido dinámico con IA
Los captchas y el contenido dinámico presentan barreras formidables para el web scraping eficaz. Estos mecanismos están diseñados para diferenciar entre usuarios humanos y servicios automatizados, lo que a menudo interrumpe los esfuerzos de recopilación de datos. Sin embargo, los avances en inteligencia artificial han introducido soluciones sofisticadas:
- Los algoritmos de aprendizaje automático han mejorado significativamente en la interpretación de captchas visuales, imitando las capacidades de reconocimiento de patrones humanos.
- Las herramientas impulsadas por IA ahora pueden adaptarse al contenido dinámico aprendiendo las estructuras de las páginas y prediciendo cambios en la ubicación de los datos.
- Algunos sistemas utilizan redes generativas adversarias (GAN) para entrenar modelos que puedan resolver captchas complejos.
- Las técnicas de procesamiento del lenguaje natural (PNL) ayudan a comprender la semántica detrás de los textos generados dinámicamente, lo que facilita la extracción de datos precisa.
A medida que se desarrolla la lucha actual entre los creadores de captcha y los desarrolladores de IA, cada paso en la tecnología de captcha es contrarrestado por una contramedida más astuta y ágil impulsada por la IA. Esta interacción dinámica garantiza un flujo fluido de datos, lo que impulsa la incesante expansión de la industria de la IA.
Mejora de la calidad y precisión de los datos mediante el poder de las aplicaciones de IA
Las aplicaciones de inteligencia artificial (IA) mejoran significativamente la calidad y precisión de los datos, lo que es fundamental para entrenar modelos eficaces. Al emplear algoritmos sofisticados, la IA puede:
- Detecte y rectifique inconsistencias en grandes conjuntos de datos.
- Filtre información irrelevante, concentrándose en subconjuntos de datos vitales para la comprensión del modelo.
- Validar datos contra puntos de referencia de calidad preestablecidos.
- Realice una limpieza de datos en tiempo real, lo que garantiza que los conjuntos de datos de entrenamiento permanezcan actualizados y precisos.
- Utilice el aprendizaje no supervisado para identificar patrones o anomalías que puedan escapar al escrutinio humano.
El uso de IA en la preparación de datos no sólo hace que el proceso sea más fluido; eleva la calidad de los conocimientos obtenidos a partir de los datos, lo que da como resultado modelos de IA más inteligentes y confiables.
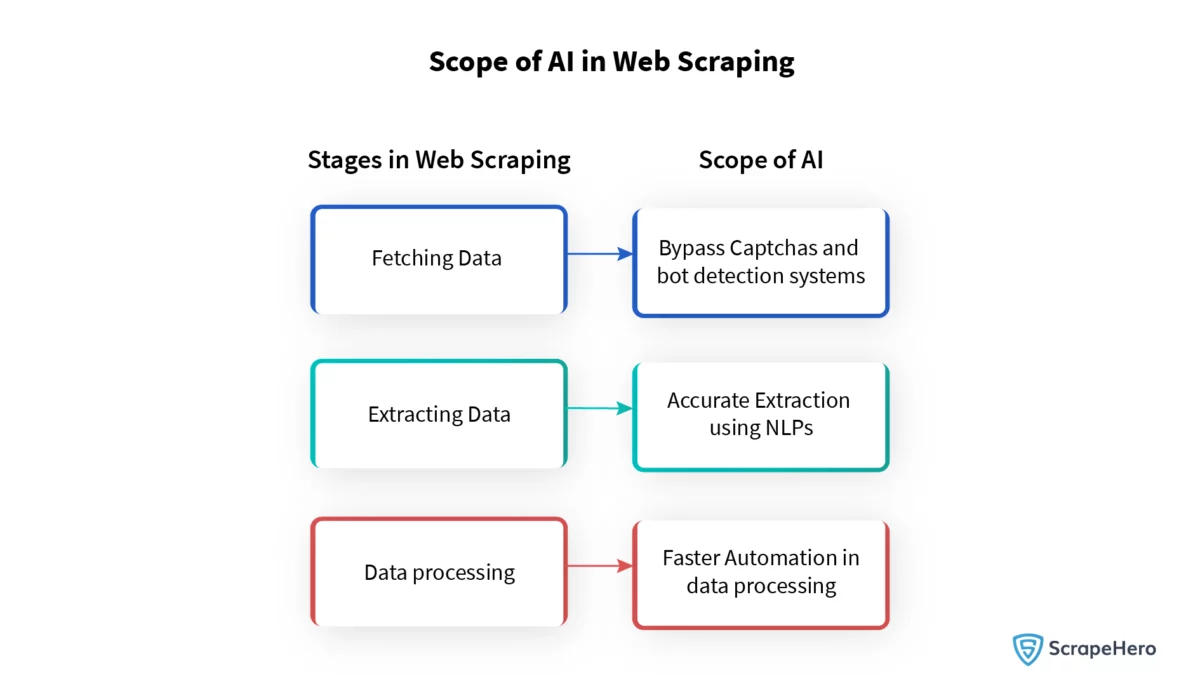
Ampliación de las operaciones de web scraping con integración de IA
La integración de la IA en las prácticas de web scraping mejora significativamente la eficiencia y escalabilidad de los procesos de recopilación de datos. Los sistemas impulsados por IA pueden adaptarse a diferentes diseños de sitios web y extraer datos con precisión, incluso si el sitio sufre cambios. Esta adaptabilidad surge de algoritmos de aprendizaje automático que aprenden de patrones y anomalías durante el proceso de raspado.
Además, la IA puede priorizar y categorizar puntos de datos, reconociendo rápidamente información valiosa. Las habilidades de procesamiento del lenguaje natural (PNL) permiten que las herramientas de scraping comprendan y procesen el lenguaje humano, lo que permite extraer sentimientos o intenciones de datos textuales. A medida que los trabajos de scraping aumentan en complejidad y volumen, la integración de la IA garantiza que estas tareas se realicen con una supervisión manual reducida, lo que lleva a una operación más ágil y rentable. La implementación de este tipo de sistemas inteligentes facilita:
- Automatizar la identificación y extracción de datos relevantes.
- Aprender y adaptarnos continuamente a nuevas estructuras web.
- Análisis e interpretación de datos no estructurados con técnicas de PNL.
- Mejorar la precisión y reducir la necesidad de intervención humana
Próximas tendencias: el panorama futuro de la IA de web scraping
A medida que navegamos por el ámbito en constante evolución de la Inteligencia Artificial, surge un punto focal sobre los notables avances en la IA del web scraping. Explore estas tendencias fundamentales que darán forma al futuro:
- Comprensión integral: la IA se expande para comprender videos, imágenes y audio contextualmente.
- Aprendizaje adaptativo: la IA ajusta las estrategias de scraping basadas en las estructuras del sitio web, reduciendo la intervención humana.
- Extracción de datos precisa: los algoritmos están ajustados para una extracción de datos precisa y relevante.
- Integración perfecta: las herramientas de scraping impulsadas por IA se integran perfectamente con las plataformas de análisis de datos.
- Adquisición ética de datos: la IA incorpora pautas éticas para el consentimiento del usuario y la protección de datos.
Fuente de la imagen: https://www.scrapehero.com/
Experimente la sinergia del web scraping y la IA para sus necesidades de datos. Comuníquese con PromptCloud en sales@promptcloud.com para obtener servicios de web scraping de última generación que mejoren la precisión de sus modelos de IA.
Preguntas frecuentes:
¿Puede la IA hacer web scraping?
Ciertamente, la IA es experta en el manejo de tareas de web scraping. Equipados con algoritmos avanzados, los sistemas de inteligencia artificial pueden recorrer sitios web de forma independiente, identificar patrones y extraer datos pertinentes con notable eficiencia. Esta capacidad marca un avance significativo, ya que amplifica la rapidez, precisión y flexibilidad de los procedimientos de extracción de datos.
¿Es ilegal el web scraping?
Cuando se trata de la legalidad del web scraping, el panorama presenta matices. El web scraping en sí no es inherentemente ilegal, pero la legalidad depende de cómo se ejecuta. El scraping responsable y ético, alineado con los términos de servicio de los sitios web objetivo, es crucial para evitar complicaciones legales. Es esencial abordar el web scraping con una mentalidad consciente y dócil.
¿Puede ChatGPT realizar web scraping?
En cuanto a ChatGPT, no participa en actividades de web scraping. Su punto fuerte radica en la comprensión y generación del lenguaje natural, proporcionando respuestas basadas en la información que recibe. Para las tareas reales de web scraping, se necesitan herramientas y programación especializadas.
¿Cuánto cuesta la IA raspadora?
Al considerar el costo de los servicios de inteligencia artificial de scraper, es importante tener en cuenta variables como la complejidad de la tarea de scraping, el volumen de datos que se extraerán y las necesidades de personalización específicas. Los modelos de precios pueden incluir tarifas únicas, planes de suscripción o cargos basados en el uso. Para obtener una cotización personalizada adaptada a sus necesidades, es recomendable comunicarse con un proveedor de servicios de web scraping como PromptCloud.