
Comprensión de la arquitectura de GPU para la optimización de inferencia de LLM
Publicado: 2024-04-02Introducción a los LLM y la importancia de la optimización de GPU
En la era actual de avances en el procesamiento del lenguaje natural (PLN), los modelos de lenguaje grande (LLM) han surgido como herramientas poderosas para una gran variedad de tareas, desde la generación de texto hasta la respuesta a preguntas y el resumen. Estos son más que el próximo generador de tokens probable. Sin embargo, la creciente complejidad y tamaño de estos modelos plantea desafíos importantes en términos de eficiencia y rendimiento computacional.
En este blog, profundizamos en las complejidades de la arquitectura de GPU y exploramos cómo los diferentes componentes contribuyen a la inferencia de LLM. Analizaremos métricas de rendimiento clave, como el ancho de banda de la memoria y la utilización del núcleo tensorial, y dilucidaremos las diferencias entre varias tarjetas GPU, lo que le permitirá tomar decisiones informadas al seleccionar hardware para sus tareas de modelos de lenguaje grandes.
En un panorama en rápida evolución donde las tareas de PNL exigen recursos computacionales cada vez mayores, optimizar el rendimiento de inferencia de LLM es primordial. Únase a nosotros mientras nos embarcamos en este viaje para desbloquear todo el potencial de los LLM a través de técnicas de optimización de GPU y profundizar en varias herramientas que nos permiten mejorar el rendimiento de manera efectiva.
Conceptos básicos de la arquitectura de GPU para LLM: conozca los aspectos internos de su GPU
Dada la naturaleza de realizar cálculos paralelos altamente eficientes, las GPU se convierten en el dispositivo elegido para ejecutar todas las tareas de aprendizaje profundo, por lo que es importante comprender la descripción general de alto nivel de la arquitectura de la GPU para comprender los cuellos de botella subyacentes que surgen durante la etapa de inferencia. Se prefieren las tarjetas Nvidia debido a CUDA (Compute Unified Device Architecture), una plataforma de computación paralela patentada y API desarrollada por NVIDIA, que permite a los desarrolladores especificar el paralelismo a nivel de subproceso en el lenguaje de programación C, proporcionando acceso directo al conjunto de instrucciones virtuales de la GPU y al paralelo. elementos computacionales.
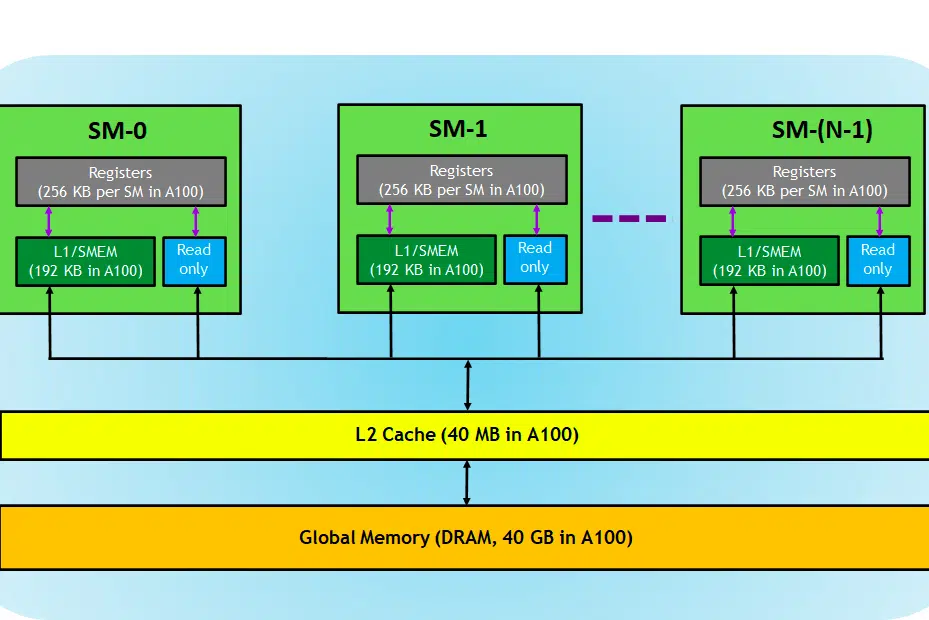
Para el contexto, utilizamos una tarjeta NVIDIA como explicación porque es ampliamente preferida para tareas de aprendizaje profundo, como ya se indicó, y algunos otros términos como Tensor Cores se aplican a eso.
Echemos un vistazo a la tarjeta GPU, aquí en la imagen podemos ver tres partes principales y (una parte oculta más importante) de un dispositivo GPU.
- SM (Multiprocesadores de transmisión por secuencias)
- caché L2
- ancho de banda de memoria
- Memoria global (DRAM)
Al igual que la CPU y la RAM funcionan juntas, la RAM es el lugar para la residencia de los datos (es decir, la memoria) y la CPU para las tareas de procesamiento (es decir, el proceso). En una GPU, la memoria global de alto ancho de banda (DRAM) contiene los pesos del modelo (por ejemplo, LLAMA 7B) que se cargan en la memoria y, cuando es necesario, estos pesos se transfieren a la unidad de procesamiento (es decir, al procesador SM) para realizar cálculos.
Multiprocesadores de transmisión
Un multiprocesador de transmisión o SM es una colección de unidades de ejecución más pequeñas llamadas núcleos CUDA (plataforma de computación paralela patentada de NVIDIA), junto con unidades funcionales adicionales responsables de la búsqueda, decodificación, programación y envío de instrucciones. Cada SM opera de forma independiente y contiene su propio archivo de registro, memoria compartida, caché L1 y unidad de textura. Los SM están altamente paralelizados, lo que les permite procesar miles de subprocesos simultáneamente, lo cual es esencial para lograr un alto rendimiento en las tareas informáticas de GPU. El rendimiento del procesador generalmente se mide en FLOPS, el no. de operaciones flotantes que puede realizar cada segundo.
Las tareas de aprendizaje profundo consisten principalmente en operaciones tensoriales, es decir, multiplicación matriz-matriz; nvidia introdujo núcleos tensoriales en GPU de nueva generación, que están diseñados específicamente para realizar estas operaciones tensoriales de una manera altamente eficiente. Como se mencionó, los núcleos tensoriales son útiles cuando se trata de tareas de aprendizaje profundo y, en lugar de los núcleos CUDA, debemos verificar los núcleos tensoriales para determinar qué tan eficientemente una GPU puede realizar el entrenamiento/inferencia de LLM.
Caché L2
La caché L2 es una memoria de gran ancho de banda que se comparte entre SM con el objetivo de optimizar el acceso a la memoria y la eficiencia de la transferencia de datos dentro del sistema. Es un tipo de memoria más pequeño y más rápido que reside más cerca de las unidades de procesamiento (como los multiprocesadores de transmisión) en comparación con la DRAM. Ayuda a mejorar la eficiencia general del acceso a la memoria al reducir la necesidad de acceder a la DRAM más lenta para cada solicitud de memoria.
ancho de banda de memoria
Entonces, el rendimiento depende de qué tan rápido podamos transferir los pesos de la memoria al procesador y de qué tan eficiente y rápidamente el procesador pueda procesar los cálculos dados.
Cuando la capacidad de cómputo es mayor o más rápida que la velocidad de transferencia de datos entre la memoria y el SM, el SM se quedará sin datos para procesar y, por lo tanto, el cómputo se subutiliza; esta situación en la que el ancho de banda de la memoria es menor que la tasa de consumo se conoce como fase ligada a la memoria. . Es muy importante tener esto en cuenta, ya que es el cuello de botella predominante en el proceso de inferencia.
Por el contrario, si el procesamiento tarda más tiempo en procesarse y si hay más datos en cola para el cálculo, este estado es una fase vinculada a la computación .
Para aprovechar al máximo la GPU, debemos estar en un estado de computación mientras realizamos los cálculos que ocurren de la manera más eficiente posible.

Memoria DRAM
La DRAM sirve como memoria principal en una GPU y proporciona una gran cantidad de memoria para almacenar datos e instrucciones necesarias para el cálculo. Por lo general, está organizado en una jerarquía, con múltiples bancos de memoria y canales para permitir el acceso de alta velocidad.
Para la tarea de inferencia, la DRAM de la GPU determina el tamaño del modelo que podemos cargar y los FLOPS de cálculo y el ancho de banda determinan el rendimiento que podemos obtener.
Comparación de tarjetas GPU para tareas de LLM
Para obtener información sobre la cantidad de núcleos tensoriales y la velocidad del ancho de banda, se puede consultar el documento técnico publicado por el fabricante de la GPU. Aquí hay un ejemplo,
| RTX A6000 | RTX 4090 | RTX 3090 | |
| Tamaño de la memoria | 48GB | 24GB | 24GB |
| Tipo de memoria | GDDR6 | GDDR6X | |
| Banda ancha | 768,0 GB/s | 1008 GB/seg | 936,2 GB/s |
| Núcleos CUDA/GPU | 10752 | 16384 | 10496 |
| Núcleos tensores | 336 | 512 | 328 |
| Caché L1 | 128 KB (por SM) | 128 KB (por SM) | 128 KB (por SM) |
| FP16 No Tensor | 38,71 TFLOPS (1:1) | 82,6 | 35,58 TFLOPS (1:1) |
| FP32 sin tensor | 38,71 TFLOPS | 82,6 | 35,58 TFLOPS |
| FP64 sin tensor | 1210 GFLOPS (1:32) | 556,0 GFLOPS (1:64) | |
| TFLOPS máximo del tensor FP16 con acumulación de FP16 | 154,8/309,6 | 330,3/660,6 | 142/284 |
| Peak FP16 Tensor TFLOPS con FP32 acumulado | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Pico TFLOPS del tensor BF16 con FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Tensor pico TF32 TFLOPS | 77,4/154,8 | 82,6/165,2 | 35,6/71 |
| Tensor pico INT8 TOPS | 309,7/619,4 | 660,6/1321,2 | 284/568 |
| Tensor pico INT4 TOPS | 619,3/1238,6 | 1321,2/2642,4 | 568/1136 |
| Caché L2 | 6 megas | 72 megas | 6 megas |
| Autobús de memoria | 384 bits | 384 bits | 384 bits |
| TMU | 336 | 512 | 328 |
| ROP | 112 | 176 | 112 |
| Conteo de SM | 84 | 128 | 82 |
| Núcleos RT | 84 | 128 | 82 |
Aquí podemos ver que FLOPS se menciona específicamente para operaciones Tensor, estos datos nos ayudarán a comparar las diferentes tarjetas GPU y seleccionar la adecuada para nuestro caso de uso. Según la tabla, aunque el A6000 tiene el doble de memoria que el 4090, los flops tensores y el ancho de banda de la memoria del 4090 son mejores en números y, por lo tanto, más potentes para la inferencia de modelos de lenguaje grandes.
Lectura adicional: Nvidia CUDA en 100 segundos
Conclusión
En el campo de la PNL que avanza rápidamente, la optimización de modelos de lenguaje grandes (LLM) para tareas de inferencia se ha convertido en un área crítica de enfoque. Como hemos explorado, la arquitectura de las GPU juega un papel fundamental para lograr un alto rendimiento y eficiencia en estas tareas. Comprender los componentes internos de las GPU, como los multiprocesadores de transmisión (SM), la caché L2, el ancho de banda de la memoria y la DRAM, es esencial para identificar los posibles cuellos de botella en los procesos de inferencia LLM.
La comparación entre diferentes tarjetas GPU NVIDIA (RTX A6000, RTX 4090 y RTX 3090) revela diferencias significativas en términos de tamaño de memoria, ancho de banda y cantidad de CUDA y Tensor Cores, entre otros factores. Estas distinciones son cruciales para tomar decisiones informadas sobre qué GPU es la más adecuada para tareas específicas de LLM. Por ejemplo, mientras que el RTX A6000 ofrece un tamaño de memoria más grande, el RTX 4090 sobresale en términos de Tensor FLOPS y ancho de banda de memoria, lo que lo convierte en una opción más potente para tareas exigentes de inferencia LLM.
La optimización de la inferencia de LLM requiere un enfoque equilibrado que considere tanto la capacidad computacional de la GPU como los requisitos específicos de la tarea de LLM en cuestión. Seleccionar la GPU adecuada implica comprender las compensaciones entre la capacidad de memoria, la potencia de procesamiento y el ancho de banda para garantizar que la GPU pueda manejar de manera eficiente los pesos del modelo y realizar cálculos sin convertirse en un cuello de botella. A medida que el campo de la PNL continúa evolucionando, mantenerse informado sobre las últimas tecnologías de GPU y sus capacidades será primordial para aquellos que buscan ampliar los límites de lo que es posible con los modelos de lenguajes grandes.
Terminología utilizada
- Rendimiento:
En caso de inferencia, el rendimiento es la medida de cuántas solicitudes/solicitudes se procesan durante un período de tiempo determinado. El rendimiento normalmente se mide de dos maneras:
- Solicitudes por segundo (RPS) :
- RPS mide la cantidad de solicitudes de inferencia que un modelo puede manejar en un segundo. Una solicitud de inferencia normalmente implica generar una respuesta o predicción basada en datos de entrada.
- Para la generación de LLM, RPS indica la rapidez con la que el modelo puede responder a las solicitudes o consultas entrantes. Los valores de RPS más altos sugieren una mejor capacidad de respuesta y escalabilidad para aplicaciones en tiempo real o casi en tiempo real.
- Lograr valores altos de RPS a menudo requiere estrategias de implementación eficientes, como agrupar múltiples solicitudes para amortizar los gastos generales y maximizar la utilización de los recursos computacionales.
- Fichas por segundo (TPS) :
- TPS mide la velocidad a la que un modelo puede procesar y generar tokens (palabras o subpalabras) durante la generación de texto.
- En el contexto de la generación de LLM, TPS refleja el rendimiento del modelo en términos de generación de texto. Indica la rapidez con la que el modelo puede producir respuestas coherentes y significativas.
- Los valores de TPS más altos implican una generación de texto más rápida, lo que permite que el modelo procese más datos de entrada y genere respuestas más largas en un período de tiempo determinado.
- Lograr valores altos de TPS a menudo implica optimizar la arquitectura del modelo, paralelizar los cálculos y aprovechar aceleradores de hardware como las GPU para acelerar la generación de tokens.
- Latencia:
La latencia en LLM se refiere al retraso de tiempo entre la entrada y la salida durante la inferencia. Minimizar la latencia es esencial para mejorar la experiencia del usuario y permitir interacciones en tiempo real en aplicaciones que aprovechan los LLM. Es esencial lograr un equilibrio entre rendimiento y latencia en función del servicio que necesitamos brindar. La baja latencia es deseable para casos como chatbots/copiloto de interacción en tiempo real, pero no es necesaria para casos de procesamiento de datos masivos como el reprocesamiento de datos internos.
Lea más sobre técnicas avanzadas para mejorar el rendimiento de LLM aquí.