
Liberar el potencial de la IA en el scraping de sitios web: descripción general
Publicado: 2024-02-02Hoy en día, el web scraping ha pasado de ser una actividad de programación de nicho a una herramienta empresarial esencial. Inicialmente, el scraping era un proceso manual en el que las personas copiaban datos de páginas web. La evolución de la tecnología introdujo scripts automatizados que podían extraer datos de manera más eficiente, aunque de forma tosca.
A medida que los sitios web se volvieron más avanzados, las técnicas de scraping también avanzaron, adaptándose a estructuras intrincadas y resistiendo las medidas anti-scraping. El progreso en la IA y el aprendizaje automático ha impulsado el web scraping a territorios inexplorados, permitiendo la comprensión contextual y enfoques adaptables que emulan los comportamientos de navegación humanos. Esta progresión continua da forma a cómo las organizaciones aprovechan los datos web a escala y con una sofisticación sin precedentes.
La aparición de la IA en el web scraping

Fuente de la imagen: https://www.scrapehero.com/
No se puede subestimar el impacto de la Inteligencia Artificial (IA) en el web scraping; ha cambiado absolutamente el panorama, haciendo el proceso más eficiente. Atrás quedaron los días de laboriosas configuraciones manuales y vigilancia constante para adaptarse a las estructuras cambiantes de los sitios web.
Ahora, gracias a la IA, los web scrapers han evolucionado hasta convertirse en herramientas intuitivas capaces de aprender de patrones y adaptarse de forma autónoma a los cambios estructurales sin una supervisión humana constante. Esto significa que pueden captar el contexto de los datos, discernir lo que es relevante con notable precisión y dejar atrás lo superfluo.
Este método más inteligente y flexible ha transformado el proceso de extracción de datos, brindando a las industrias las herramientas para tomar decisiones mejor informadas basadas en una calidad de datos de primer nivel. A medida que avanza la tecnología de inteligencia artificial, su incorporación a las herramientas de web scraping está preparada para establecer nuevos estándares, alterando fundamentalmente la forma en que recopilamos información de la web.
Consideraciones éticas y legales en el web scraping moderno
A medida que el web scraping evoluciona con los avances de la IA, las implicaciones éticas y legales se vuelven más complejas. Los raspadores web deben navegar:
- Leyes de privacidad de datos : los desarrolladores de Scraper deben comprender leyes como GDPR y CCPA para evitar infracciones legales que involucren datos personales.
- Cumplimiento de los términos de servicio : respetar los términos de servicio de un sitio web es crucial; El raspado contrario a estos puede dar lugar a litigios o denegación de acceso.
- Material con derechos de autor : el contenido obtenido no debe infringir los derechos de autor, lo que genera preocupaciones sobre la distribución y el uso de los datos extraídos.
- Estándar de exclusión de robots : adherirse al archivo robots.txt de los sitios web indica una conducta ética al respetar las preferencias de scraping del propietario del sitio.
- Consentimiento del usuario : cuando se trata de datos personales, garantizar que se haya obtenido el consentimiento del usuario preserva la integridad ética.
- Transparencia : la comunicación clara sobre la intención y el alcance de las operaciones de scraping fomenta un ambiente de confianza y responsabilidad.
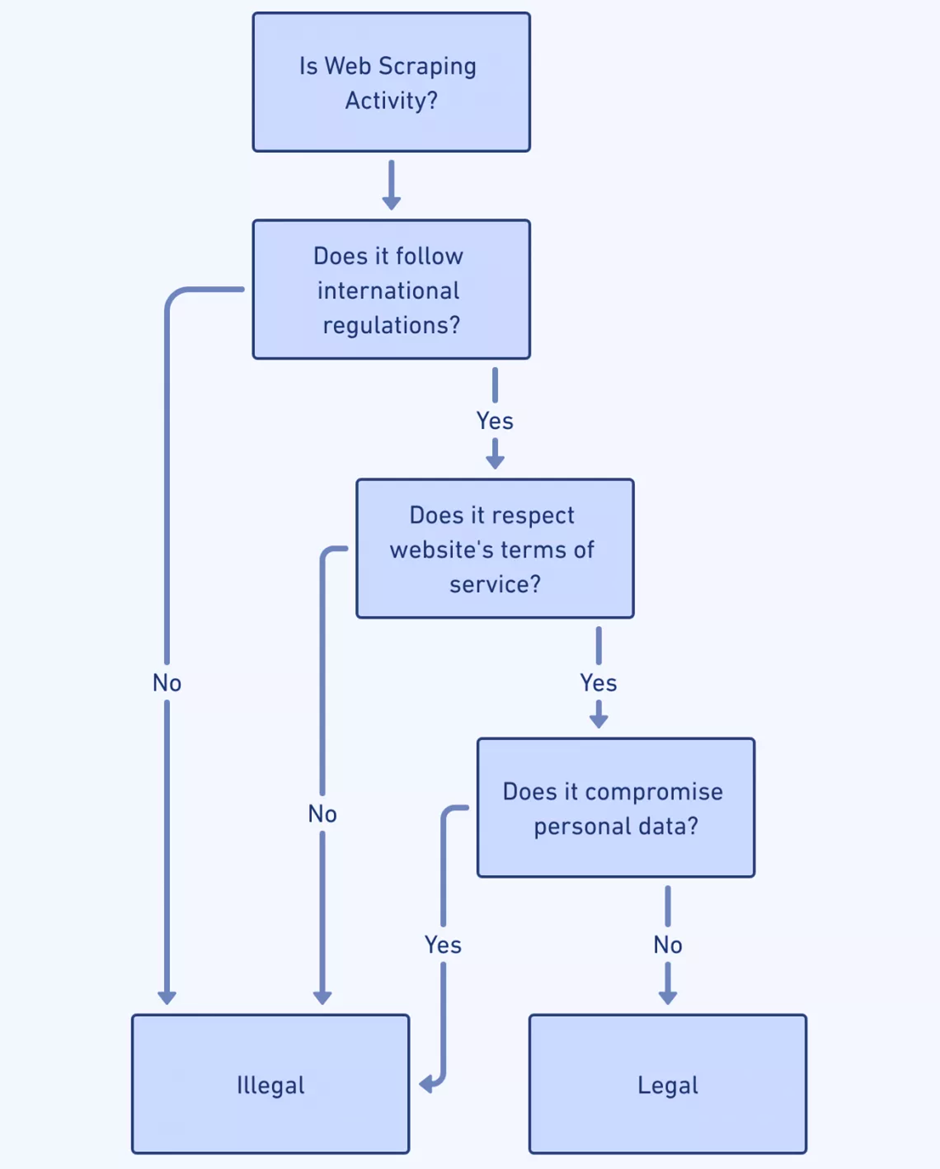
Fuente de la imagen: https://scrape-it.cloud/
Navegar por estas consideraciones requiere vigilancia y compromiso con las prácticas éticas.

Avances en algoritmos de IA para una extracción de datos mejorada
Últimamente, hemos observado una evolución notable en los algoritmos de IA, lo que ha remodelado significativamente el panorama de las capacidades de extracción de datos. Los modelos avanzados de aprendizaje automático, que demuestran una capacidad mejorada para descifrar patrones complejos, han elevado la precisión de la extracción de datos a niveles sin precedentes.
Los avances en el procesamiento del lenguaje natural (PNL) han profundizado la comprensión contextual, no solo facilitando la extracción de información relevante sino también permitiendo la interpretación de sentimientos y matices semánticos sutiles.
La aparición de redes neuronales, en particular de redes neuronales convolucionales (CNN), ha provocado una revolución en la extracción de datos de imágenes. Este avance permite a la inteligencia artificial no solo reconocer sino también clasificar contenido visual procedente de la vasta extensión de Internet.
Además, el aprendizaje por refuerzo (RL) ha introducido un nuevo paradigma en el que las herramientas de inteligencia artificial perfeccionan las estrategias de scraping óptimas a lo largo del tiempo, mejorando así su eficiencia operativa. La integración de estos algoritmos en herramientas de web scraping ha dado como resultado:
- Interpretación y análisis de datos sofisticados
- Adaptabilidad mejorada a diversas estructuras web.
- Reducción de la necesidad de intervención humana para tareas complejas
- Eficiencia mejorada en el manejo de la extracción de datos a gran escala
Superar obstáculos: CAPTCHA, contenido dinámico y calidad de datos
La tecnología de web scraping debe sortear varios obstáculos:
- CAPTCHA : los raspadores de sitios web de IA ahora emplean algoritmos avanzados de reconocimiento de imágenes y aprendizaje automático para resolver CAPTCHA con mayor precisión, lo que permite el acceso sin intervención humana.
- Contenido dinámico : los raspadores de sitios web de IA están diseñados para interpretar JavaScript y AJAX que generan contenido dinámico, lo que garantiza que los datos se capturen de las aplicaciones web con la misma eficacia que de las páginas estáticas.

Fuente de la imagen: PromptCloud
- Calidad de los datos : la introducción de la IA ha traído mejoras en la identificación y clasificación de datos. Esto es para garantizar que la información recopilada sea relevante y de alta calidad, reduciendo la necesidad de limpieza y verificación manual. Los raspadores de sitios web de IA aprenden continuamente a distinguir entre ruido y datos valiosos, refinando su proceso de extracción de datos.
Fusión de IA con análisis de Big Data en Web Scraping
La integración de la Inteligencia Artificial (IA) con el análisis de Big Data representa un salto transformador en el web scraping. En esta integración:
- Se implementan algoritmos de IA para interpretar y analizar vastos conjuntos de datos aprovechados mediante scraping, logrando conocimientos a velocidades sin precedentes.
- Los elementos de aprendizaje automático dentro de la IA pueden mejorar aún más la extracción de datos, aprendiendo a identificar y extrapolar patrones e información de manera eficiente.
- Luego, el análisis de Big Data puede procesar esta información, proporcionando a las empresas inteligencia procesable.
- Además, la IA ayuda a limpiar y estructurar los datos, un paso crucial para aprovechar eficazmente el análisis de Big Data.
- Esta sinergia entre la IA y el análisis de Big Data en el web scraping es crucial para tomar decisiones urgentes y mantener ventajas competitivas.
El panorama futuro: predicciones y potencial para los raspadores de sitios web de IA
El ámbito del scraping de sitios web mediante IA se encuentra en un umbral significativo de transformación. Las predicciones apuntan a:
- Capacidades cognitivas mejoradas, que permiten a los raspadores interpretar datos complejos con una comprensión similar a la humana.
- Integración con otras tecnologías de inteligencia artificial, como el procesamiento del lenguaje natural, para una extracción de datos más matizada.
- Scrapers de autoaprendizaje que refinan sus métodos en función de las tasas de éxito, creando protocolos de recolección de datos más eficientes.
- Mayor cumplimiento de estándares éticos y legales a través de algoritmos de cumplimiento avanzados.
- Colaboración entre raspadores de IA y tecnologías blockchain para transacciones de datos seguras y transparentes.
Contáctenos hoy en [email protected] para descubrir cómo nuestra tecnología de punta de inteligencia artificial para raspar sitios web puede revolucionar sus procesos de extracción de datos e impulsar a su organización a nuevas alturas.