
Cómo cargar datos en BigQuery con R y Python
Publicado: 2023-06-06El mundo del análisis web sigue avanzando hacia la fatídica fecha del 1 de julio, cuando Universal Analytics deja de procesar datos y es reemplazado por Google Analytics 4 (GA4). Uno de los cambios clave es que en GA4, solo puede retener datos en la plataforma por un máximo de 14 meses. Este es un cambio importante con respecto a UA, pero a cambio de esto, puede enviar datos de GA4 a BigQuery de forma gratuita, hasta un límite.
BigQuery es un recurso extremadamente útil para el almacenamiento de datos más allá de GA4. Dado que se vuelve más importante que nunca en unos pocos meses, es un buen momento para comenzar a usarlo para todas sus necesidades de almacenamiento de datos. A menudo, será preferible manipular los datos de alguna manera antes de cargarlos. Para esto, recomendamos usar un script escrito en R o Python, especialmente si este tipo de manipulación debe realizarse repetidamente. También puede cargar datos en BigQuery directamente desde estos scripts, y eso es exactamente lo que este blog le guiará.
Subir a BigQuery desde R
R es un lenguaje extremadamente poderoso para la ciencia de datos y el más fácil de usar para cargar datos en BigQuery. El primer paso es importar todas las bibliotecas necesarias. Para este tutorial, necesitaremos las siguientes bibliotecas:
library(googleAuthR)
library(bigQueryR)
Si no ha usado estas bibliotecas antes, ejecute install.packages(<PACKAGE NAME>) en la consola para instalarlas.
A continuación, debemos abordar lo que a menudo es la parte más complicada y consistentemente más frustrante de trabajar con API: la autorización. Afortunadamente, con R, esto es relativamente simple. Necesitará un archivo JSON que contenga las credenciales de autorización. Esto se puede encontrar en Google Cloud Console, el mismo lugar donde se encuentra BigQuery. Primero, navegue a Google Cloud Console y haga clic en 'API y servicios'.
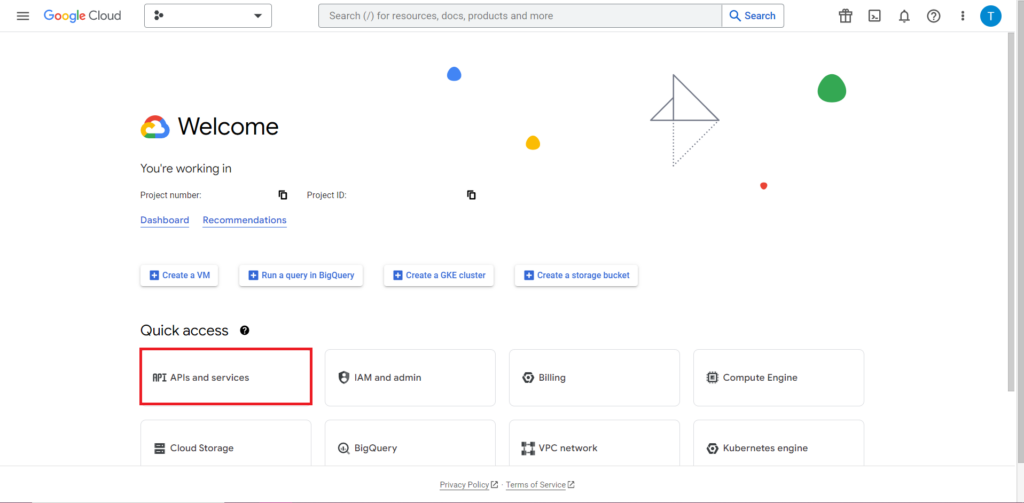
A continuación, haga clic en 'Credenciales' en la barra lateral.
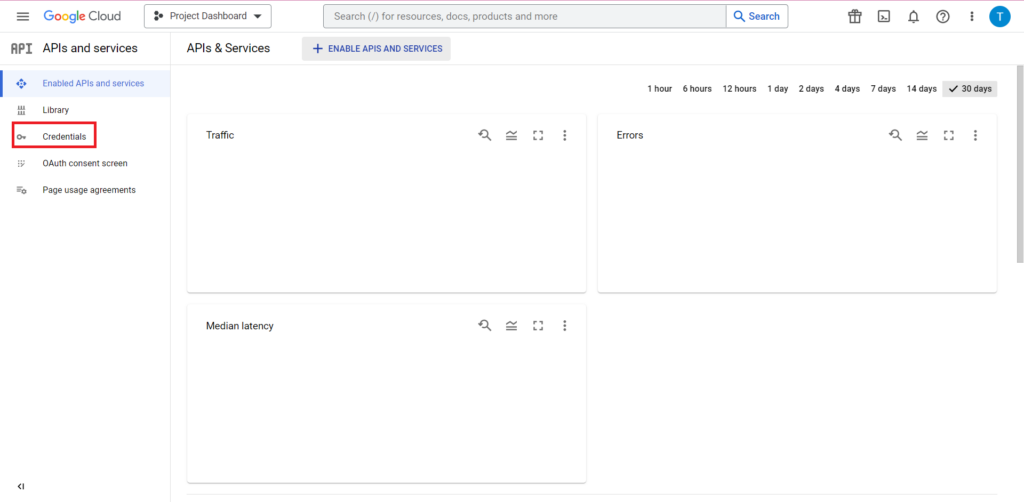
En la página Credenciales, puede ver sus claves de API existentes, los ID de cliente de OAuth 2.0 y las cuentas de servicio. Querrá una ID de cliente de OAuth 2.0 para esto, así que presione el botón de descarga al final de la fila correspondiente para su ID, o cree una nueva ID haciendo clic en 'Crear credenciales' en la parte superior de la página. Asegúrese de que su ID tenga permiso para ver y editar el proyecto de BigQuery relevante; para hacerlo, abra la barra lateral, desplace el cursor sobre "IAM y administrador" y haga clic en "IAM". En esta página, puede otorgar acceso a su cuenta de servicio al proyecto correspondiente mediante el botón "Otorgar acceso" en la parte superior de la página.
Con el archivo JSON obtenido y guardado, puede pasarle la ruta con la función gar_set_client() para establecer sus credenciales. El código completo para la autorización se encuentra a continuación:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Obviamente, querrá reemplazar la ruta en la función gar_set_client() con la ruta a su propio archivo JSON e insertar la dirección de correo electrónico que usa para acceder a BigQuery en la función bqr_auth().
Una vez que la autorización esté configurada, necesitamos algunos datos para cargarlos en BigQuery. Tendremos que poner estos datos en un marco de datos. Para los fines de este artículo, voy a crear algunos datos ficticios con varias ubicaciones y recuentos de ventas, pero lo más probable es que esté leyendo datos reales de un archivo .csv o una hoja de cálculo. Para leer datos de un archivo .csv, simplemente puede usar la función read.csv(), pasando como argumento la ruta al archivo:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Alternativamente, si tiene sus datos almacenados en una hoja de cálculo, su método variará dependiendo de dónde se encuentre esta hoja de cálculo. Si su hoja de cálculo está almacenada en Google Sheets, puede leer sus datos en R usando la biblioteca googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Como antes, si no ha usado este paquete antes, deberá ejecutar install.packages ("googlesheets4") en la consola antes de ejecutar su código.
Si su hoja de cálculo está en Excel, deberá usar la biblioteca readxl, que es parte de la biblioteca tidyverse, algo que recomiendo usar. Contiene una gran cantidad de funciones que hacen que la manipulación de datos en R sea mucho más fácil:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
Y una vez más, ¡asegúrate de ejecutar install.package(“tidyverse”) si no lo has hecho antes!
El paso final es cargar los datos en BigQuery. Para esto, necesitará un lugar en BigQuery para cargarlo. Su tabla se ubicará dentro de un conjunto de datos, que se ubicará dentro de un proyecto, y necesitará los nombres de los tres en el siguiente formato:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
En mi caso, esto significa que mi código dice:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
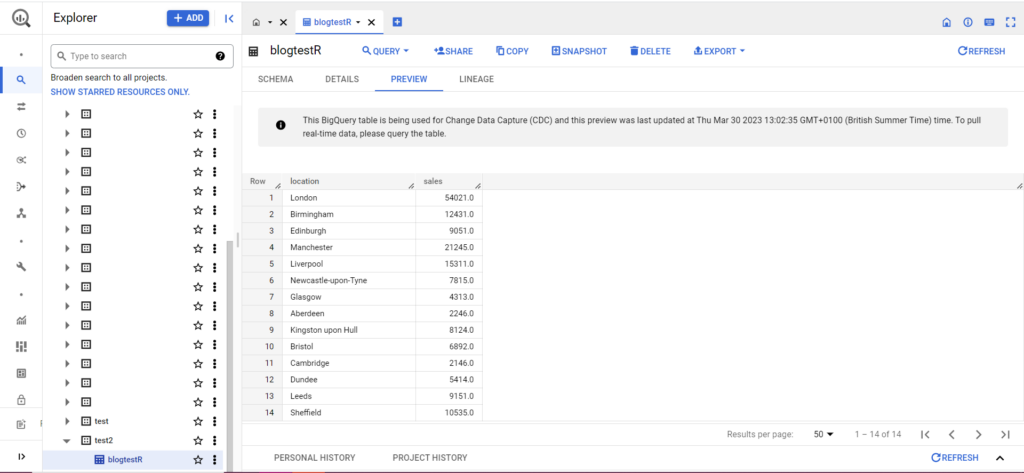
Si tu tabla aún no existe, no te preocupes, el código la creará por ti. ¡No olvide insertar los nombres de su proyecto, conjunto de datos y tabla en el código anterior (entre comillas) y asegúrese de cargar el marco de datos correcto! Una vez hecho esto, debería ver sus datos en BigQuery, como se muestra a continuación:

Como paso final, supongamos que tiene datos adicionales que le gustaría agregar a BigQuery. Por ejemplo, en mis datos anteriores, digamos que olvidé incluir un par de ubicaciones del continente y quiero subir a BigQuery, pero no quiero sobrescribir los datos existentes. Para esto, bqr_upload_data tiene un parámetro llamado writeDisposition. writeDisposition tiene dos configuraciones, "WRITE_TRUNCATE" y "WRITE_APPEND". El primero le dice a bqr_upload_data() que sobrescriba los datos existentes en la tabla, mientras que el segundo le dice que agregue los nuevos datos. Por lo tanto, para cargar estos nuevos datos, escribiré:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
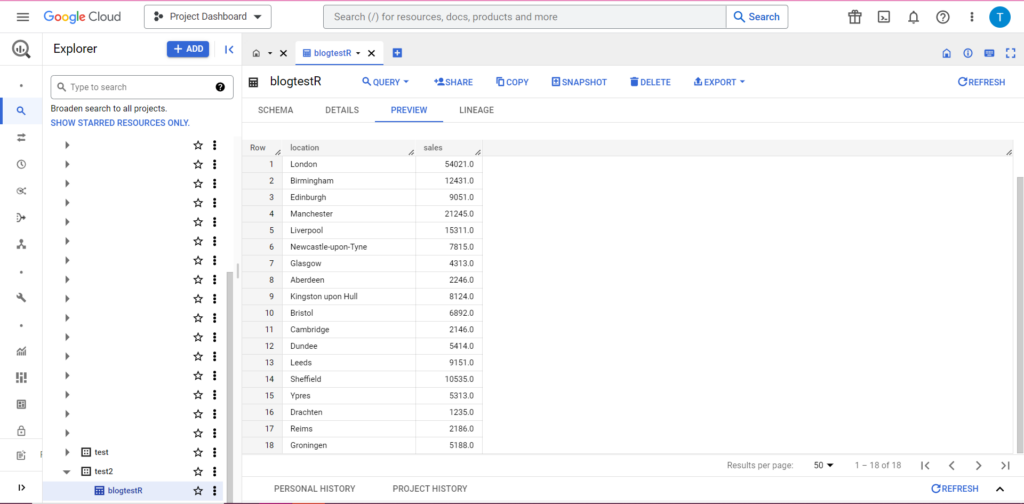
Y, por supuesto, en BigQuery podemos ver que nuestros datos tienen nuevos compañeros de habitación:
Subir a BigQuery desde Python
En Python, las cosas son un poco diferentes. Una vez más, necesitaremos importar algunos paquetes, así que comencemos con estos:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
La autorización es complicada. Una vez más, necesitaremos un archivo JSON que contenga las credenciales. Como arriba, navegaremos a Google Cloud Console y haremos clic en 'API y servicios', luego haremos clic en 'Credenciales' en la barra lateral. Esta vez, en la parte inferior de la página, habrá una sección llamada 'Cuentas de servicio'.
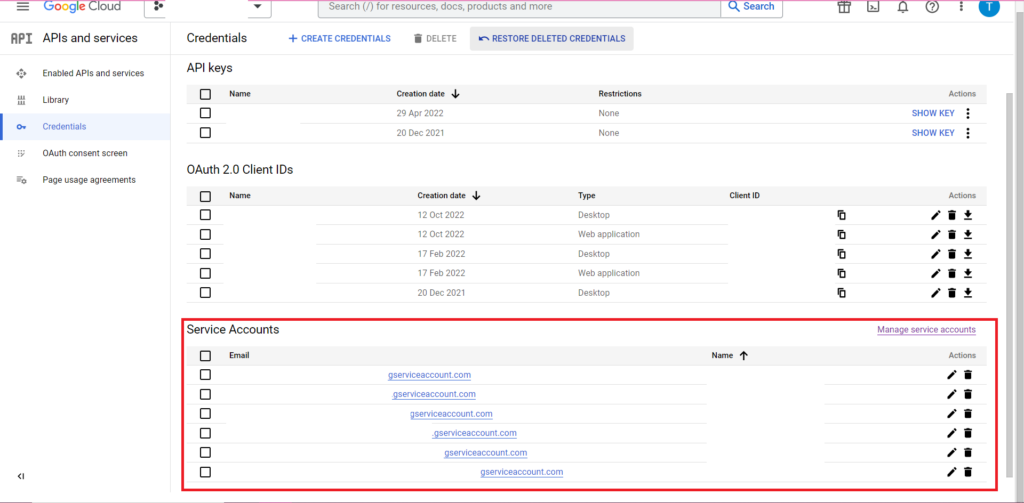
Allí puede descargar la clave para su cuenta de servicio o, al hacer clic en 'Administrar cuenta de servicio', puede crear una nueva clave o una nueva cuenta de servicio para la cual puede descargar las credenciales.
Luego querrá asegurarse de que su cuenta de servicio tenga permiso para acceder y editar su proyecto de BigQuery. Una vez más, navegue a la página de IAM en 'IAM y administración' en la barra lateral, y allí podrá otorgar acceso a su cuenta de servicio al proyecto correspondiente mediante el botón 'Otorgar acceso' en la parte superior de la página.
Tan pronto como lo haya resuelto, puede escribir el código de autorización:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
A continuación, deberá colocar sus datos en un marco de datos. Los marcos de datos pertenecen al paquete pandas y son muy simples de crear. Para leer desde un CSV, siga este ejemplo:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Obviamente, deberá reemplazar la ruta anterior con la de su propio archivo CSV. Para leer desde un archivo de Excel, siga este ejemplo:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Leer desde Hojas de cálculo de Google es complicado y requiere otra ronda de autorización. Tendremos que importar algunos paquetes nuevos y usar el archivo de credenciales JSON que recuperamos durante el tutorial de R anterior. Puedes seguir este código para autorizar y leer tus datos:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Una vez que tenga sus datos en su marco de datos, ¡es hora de subirlos a BigQuery una vez más! Puedes hacerlo siguiendo esta plantilla:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Como ejemplo, aquí está el código que acabo de escribir para cargar los datos que hice anteriormente:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Una vez hecho esto, los datos deberían aparecer inmediatamente en BigQuery.
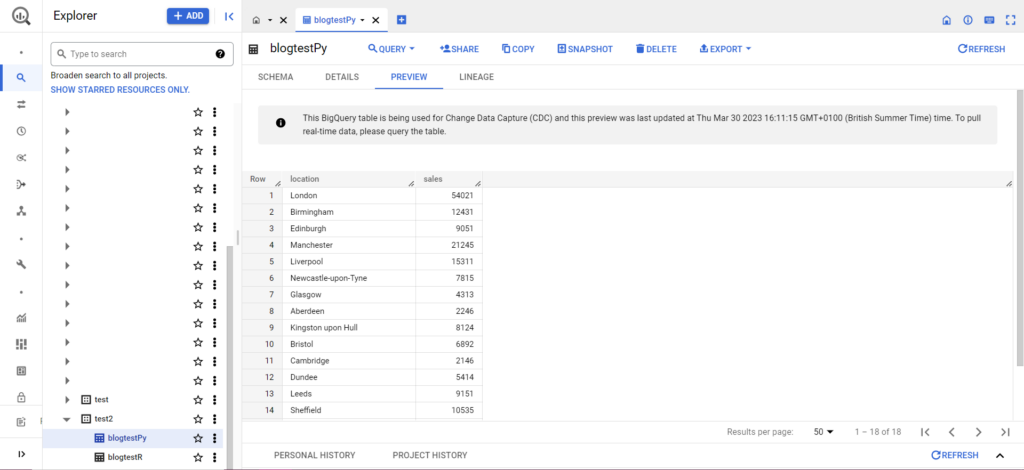
Hay mucho más que puede hacer con estas funciones una vez que las domine. Si desea tener un mayor control sobre su configuración de análisis, ¡Semetrical está aquí para ayudarlo! Consulte nuestro blog para obtener más información sobre cómo aprovechar al máximo sus datos. O, para obtener más asistencia en todo lo relacionado con análisis, diríjase a Web Analytics para averiguar cómo podemos ayudarlo.