
Desafíos y soluciones del web scraping: navegando por las complejidades
Publicado: 2023-09-13El web scraping se ha convertido en una técnica invaluable para extraer datos de sitios web. Ya sea que necesite recopilar información con fines de investigación, realizar un seguimiento de precios o tendencias, o automatizar ciertas tareas en línea, el web scraping puede ahorrarle tiempo y esfuerzo. Navegar por las complejidades de los sitios web y abordar diversos desafíos del web scraping puede ser una tarea desalentadora. En este artículo, profundizaremos en la simplificación del proceso de web scraping obteniendo una comprensión integral del mismo. Cubriremos los pasos involucrados, seleccionando las herramientas apropiadas, identificando los datos de destino, navegando por las estructuras del sitio web, manejando la autenticación y captcha, y manejando contenido dinámico.
Comprender el raspado web
El web scraping es el procedimiento de extracción de datos de sitios web mediante el análisis y análisis de código HTML y CSS. Abarca el envío de solicitudes HTTP a páginas web, recuperar el contenido HTML y posteriormente extraer la información pertinente. Si bien el web scraping manual mediante la inspección del código fuente y la copia de datos es una opción, a menudo es ineficiente y requiere mucho tiempo, especialmente para una recopilación extensa de datos.
Para automatizar el proceso de web scraping, se pueden emplear lenguajes de programación como Python y bibliotecas como Beautiful Soup o Selenium, así como herramientas de web scraping dedicadas como Scrapy o Beautiful Soup. Estas herramientas ofrecen funcionalidades para interactuar con sitios web, analizar HTML y extraer datos de manera eficiente.
Desafíos de raspado web
Seleccionar las herramientas adecuadas
Seleccionar las herramientas adecuadas es crucial para el éxito de su esfuerzo de web scraping. Aquí hay algunas consideraciones al elegir las herramientas para su proyecto de web scraping:
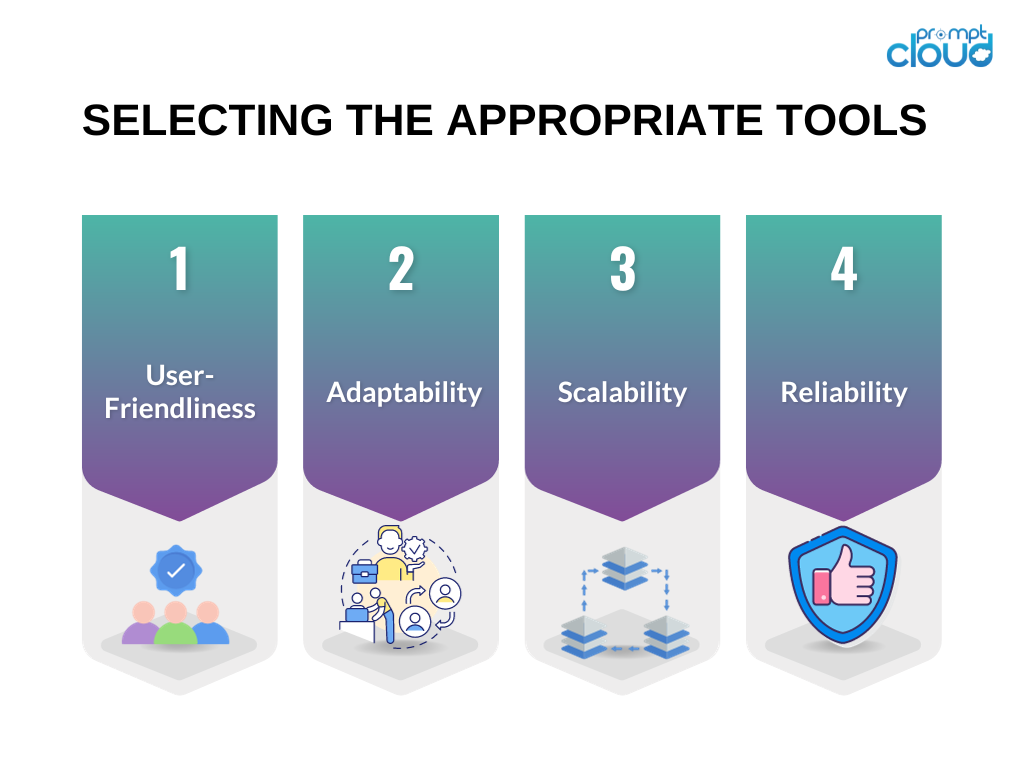
Facilidad de uso : priorice las herramientas con interfaces fáciles de usar o aquellas que proporcionen documentación clara y ejemplos prácticos.
Adaptabilidad : opte por herramientas capaces de manejar diversos tipos de sitios web y adaptarse a los cambios en las estructuras de los sitios web.
Escalabilidad : si su tarea de recopilación de datos implica una cantidad sustancial de datos o requiere capacidades avanzadas de web scraping, considere herramientas que puedan manejar grandes volúmenes y ofrecer funciones de procesamiento paralelo.
Confiabilidad : asegúrese de que las herramientas estén equipadas para administrar varios tipos de errores, como tiempos de espera de conexión o errores HTTP, y que vengan con mecanismos de manejo de errores integrados.
Según estos criterios, con frecuencia se recomiendan herramientas ampliamente utilizadas como Beautiful Soup y Selenium para proyectos de web scraping.
Identificación de datos de destino
Antes de comenzar un proyecto de web scraping, es esencial identificar los datos de destino que desea extraer de un sitio web. Podría ser información de productos, artículos de noticias, publicaciones en redes sociales o cualquier otro tipo de contenido. Comprender la estructura del sitio web de destino es crucial para extraer eficazmente los datos deseados.
Para identificar los datos de destino, puede utilizar herramientas de desarrollo de navegadores como Chrome DevTools o Firefox Developer Tools. Estas herramientas le permiten inspeccionar la estructura HTML de una página web, identificar los elementos específicos que contienen los datos que necesita y comprender los selectores CSS o las expresiones XPath necesarias para extraer esos datos.

Navegando por las estructuras del sitio web
Los sitios web pueden tener estructuras complejas con elementos HTML anidados, contenido JavaScript dinámico o solicitudes AJAX. Navegar a través de estas estructuras y extraer la información relevante requiere análisis y estrategias cuidadosos.
A continuación se presentan algunas técnicas que le ayudarán a navegar por estructuras complejas de sitios web:
Utilice selectores CSS o expresiones XPath : al comprender la estructura del código HTML, puede utilizar selectores CSS o expresiones XPath para apuntar a elementos específicos y extraer los datos deseados.
Manejar la paginación : si los datos de destino se distribuyen en varias páginas, debe implementar la paginación para extraer toda la información. Esto se puede hacer automatizando el proceso de hacer clic en los botones "siguiente" o "cargar más" o construyendo URL con diferentes parámetros.
Tratar con elementos anidados : a veces, los datos de destino están anidados en varios niveles de elementos HTML. En tales casos, debe recorrer los elementos anidados utilizando relaciones padre-hijo o relaciones entre hermanos para extraer la información deseada.
Manejo de autenticación y Captcha
Algunos sitios web pueden requerir autenticación o presentar captchas para evitar el scraping automático. Para superar estos desafíos del web scraping, puede utilizar las siguientes estrategias:
Gestión de sesión : mantenga el estado de la sesión con cookies o tokens para manejar los requisitos de autenticación.
Suplantación de agente de usuario : emule diferentes agentes de usuario para que aparezcan como usuarios normales y eviten la detección.
Servicios de resolución de captcha : utilice servicios de terceros que puedan resolver automáticamente captchas en su nombre.
Tenga en cuenta que, si bien se pueden omitir la autenticación y los captchas, debe asegurarse de que sus actividades de web scraping cumplan con los términos de servicio y las restricciones legales del sitio web.
Tratar con contenido dinámico
Los sitios web suelen utilizar JavaScript para cargar contenido de forma dinámica o recuperar datos a través de solicitudes AJAX. Es posible que los métodos tradicionales de web scraping no capturen este contenido dinámico. Para manejar contenido dinámico, considere los siguientes enfoques:
Utilice navegadores sin cabeza : herramientas como Selenium le permiten controlar navegadores web reales mediante programación e interactuar con el contenido dinámico.
Utilice bibliotecas de web scraping : ciertas bibliotecas como Puppeteer o Scrapy-Splash pueden manejar la representación de JavaScript y la extracción dinámica de contenido.
Al utilizar estas técnicas, puede asegurarse de poder eliminar sitios web que dependen en gran medida de JavaScript para la entrega de contenido.
Implementación del manejo de errores
El web scraping no siempre es un proceso sencillo. Los sitios web pueden cambiar sus estructuras, devolver errores o imponer limitaciones a las actividades de scraping. Para mitigar los riesgos asociados con estos desafíos del web scraping, es importante implementar mecanismos de manejo de errores:
Supervise los cambios del sitio web : verifique periódicamente si la estructura o el diseño del sitio web ha cambiado y ajuste su código de raspado en consecuencia.
Mecanismos de reintento y tiempo de espera : implemente mecanismos de reintento y tiempo de espera para manejar correctamente errores intermitentes, como tiempos de espera de conexión o errores HTTP.
Registre y maneje excepciones : capture y maneje diferentes tipos de excepciones, como errores de análisis o fallas de red, para evitar que su proceso de raspado falle por completo.
Al implementar técnicas de manejo de errores, puede garantizar la confiabilidad y solidez de su código de raspado web.
Resumen
En conclusión, los desafíos del web scraping se pueden facilitar comprendiendo el proceso, eligiendo las herramientas adecuadas, identificando los datos de destino, navegando por las estructuras del sitio web, manejando la autenticación y los captchas, manejando contenido dinámico e implementando técnicas de manejo de errores. Si sigue estas mejores prácticas, podrá superar las complejidades del web scraping y recopilar de manera eficiente los datos que necesita.