
Web Data Scraping en la era del Big Data: oportunidades y dilemas éticos
Publicado: 2024-05-29Web Data Scraping y análisis de Big Data
El raspado de datos web se ha convertido en un mecanismo fundamental para recopilar datos en línea. Este proceso implica la recuperación automatizada de información de sitios web, transformando la web no estructurada en una gran cantidad de datos estructurados listos para el análisis.
Fuente de la imagen: https://www.sas.com/
Al mismo tiempo, el análisis de big data se ha hecho un hueco en la capacidad de discernir patrones, tendencias y conocimientos a partir de conjuntos de datos masivos acumulados, a menudo mediante extracción de datos web. A medida que grandes volúmenes de datos (aproximadamente 2,5 quintillones de bytes de datos generados cada día) se vuelven más accesibles, la síntesis de la extracción de datos web con análisis de big data abre una infinidad de posibilidades para empresas, investigadores y formuladores de políticas.
Al combinar hábilmente estas capacidades tecnológicas, se posicionan para capitalizar la toma de decisiones guiada por datos, estimular innovaciones en servicios y moldear iniciativas estratégicas adaptadas a sus objetivos. Sin embargo, es esencial reconocer la aparición de dilemas éticos resultantes de la relación sinérgica entre estas herramientas avanzadas.
Se debe trazar con cuidado una línea muy fina respecto del equilibrio crucial entre maximizar el valor de los datos y preservar los derechos de privacidad de las personas, garantizando que ninguno de los aspectos eclipse al otro.
Beneficios del web data scraping para proyectos de big data
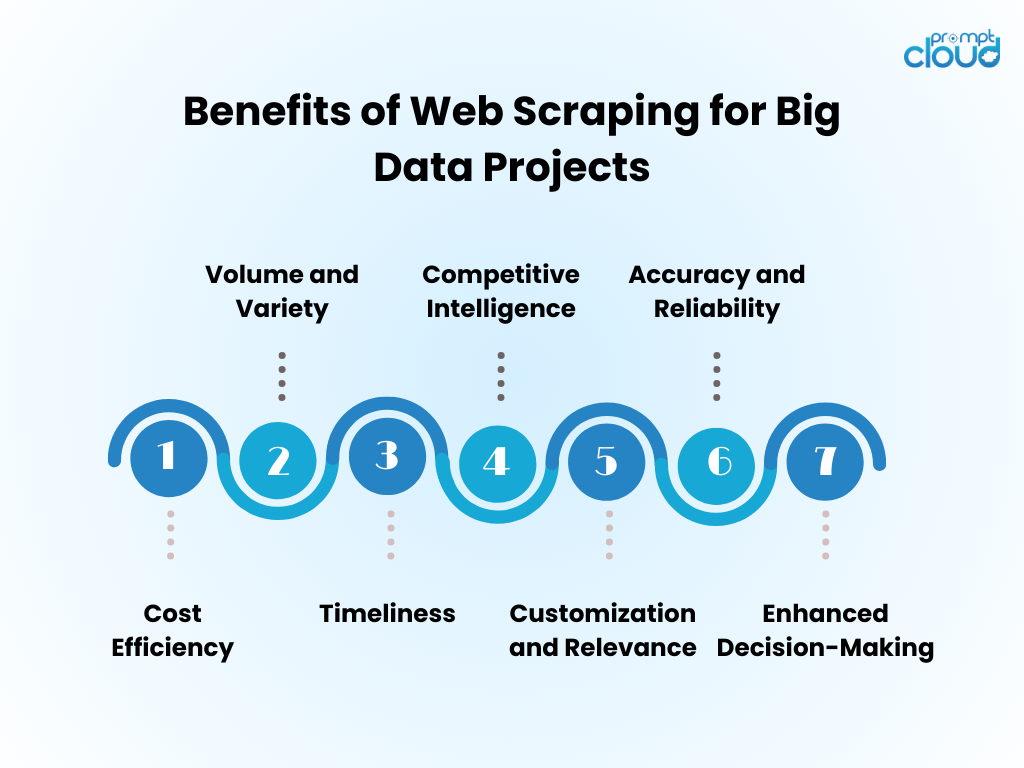
- Eficiencia de costos : la automatización de la recopilación de datos mediante web scraping reduce significativamente los costos de mano de obra humana y acelera el tiempo de obtención de información.
- Volumen y variedad : permite la captura de grandes cantidades de datos de diversas fuentes, fundamentales para alimentar el análisis de big data.
- Puntualidad : el web scraping proporciona datos en tiempo real o casi en tiempo real, lo que permite respuestas más ágiles a las tendencias del mercado.
- Inteligencia competitiva : otorga a las organizaciones la capacidad de monitorear de cerca a los competidores y los cambios de la industria.
- Personalización y relevancia : los datos se pueden adaptar a necesidades específicas, asegurando que el análisis sea relevante y enfocado.
- Precisión y confiabilidad : el scraping automatizado minimiza el error humano, lo que genera conjuntos de datos más precisos.
- Toma de decisiones mejorada : el acceso a datos relevantes y oportunos respalda la toma de decisiones informada y la planificación estratégica.
Técnicas de web scraping: de básico a avanzado

Fuente de la imagen: inicio de sesión
El raspado de datos web ha evolucionado con la tecnología, comenzando con técnicas básicas que avanzan a medida que crece la complejidad de los datos.
- Técnicas básicas : inicialmente, los raspadores recuperan datos mediante solicitudes HTTP simples para obtener páginas HTML, analizando el contenido a través de bibliotecas como Beautiful Soup en Python. Estas herramientas pueden manejar adecuadamente sitios web sencillos.
- Técnicas intermedias : para contenido dinámico, las técnicas evolucionan para incluir herramientas de automatización como Selenium, que pueden interactuar con JavaScript e imitar el comportamiento del navegador.
- Técnicas avanzadas : avanzando hacia el scraping avanzado, los métodos incorporan navegadores sin cabeza y servidores proxy para navegar por las medidas anti-scraping. La extracción de datos se vuelve sofisticada con algoritmos de aprendizaje automático, que procesan lenguaje natural e imágenes para recuperar información.
- Consideraciones éticas : Independientemente de la complejidad de la técnica, persisten dilemas éticos que requieren un equilibrio entre el acceso a los datos y el respeto a la privacidad y la propiedad.
Incorporación de datos extraídos de la web en análisis de big data
Los datos extraídos de la web, cuando se integran en análisis de big data, pueden revelar conocimientos completos del mercado y tendencias de los consumidores. Los analistas combinan información extraída de la web con conjuntos de datos existentes, mejorando la profundidad y amplitud de los resultados analíticos. Esta fusión genera modelos predictivos mejorados, estrategias de marketing personalizadas y perfiles de consumidores refinados.

- Limpieza de datos: los datos extraídos requieren una limpieza meticulosa para garantizar la precisión de los análisis.
- Integración de datos: la combinación de datos extraídos con otras fuentes requiere técnicas avanzadas de integración de datos.
- Mejora del análisis: con datos adicionales, los algoritmos de aprendizaje automático pueden revelar patrones más matizados.
- Consideración ética: los analistas deben garantizar que el uso de datos web cumpla con los estándares legales y éticos.
El conjunto de datos aumentado impulsa la innovación, pero exige una metodología rigurosa y una supervisión ética.
Mejores prácticas para un web scraping eficiente
- Respetar los protocolos robots.txt; No elimines sitios que no lo permitan a través de su archivo robots.
- Programe actividades de scraping durante las horas de menor actividad para minimizar el impacto en el rendimiento del servidor de destino.
- Utilice el almacenamiento en caché para evitar volver a extraer el mismo contenido, respetando los datos del sitio web y ahorrando ancho de banda.
- Implemente un manejo de errores adecuado para evitar que su raspador falle y evitar enviar demasiadas solicitudes en caso de errores.
- Gire los agentes de usuario y las direcciones IP para evitar que se bloqueen, simulando un comportamiento de navegación más natural.
- Manténgase informado sobre las prácticas legales y éticas de web scraping, asegurándose de que sus actividades de scraping no violen los derechos de autor ni las leyes de privacidad.
- Optimice el código para que sea eficiente y reduzca la carga tanto en el sistema de scraping como en los sitios web de destino.
- Actualice periódicamente el código de raspado para adaptarlo a cualquier cambio en el diseño o la tecnología del sitio web, manteniendo la eficacia y precisión de la recuperación de datos.
- Almacene los datos recopilados de forma segura y adminístrelos de conformidad con todas las normas de protección de datos pertinentes.
El futuro del web scraping en la era del big data
A medida que Big Data continúa expandiéndose, la extracción de datos web está a punto de convertirse en una parte aún más integral del análisis de datos y la inteligencia empresarial. El futuro probablemente verá:
- Modelos de aprendizaje automático mejorados entrenados con vastos conjuntos de datos obtenidos mediante scraping, lo que mejora la precisión y la información.
- Mayor demanda de extracción de datos en tiempo real, lo que permite a las empresas tomar decisiones más rápidas basadas en datos.
- Desarrollo de herramientas de scraping más sofisticadas para navegar por tecnologías anti-scraping y mantener prácticas éticas de recopilación de datos.
- Regulaciones y leyes de privacidad más estrictas que dan forma a las metodologías de extracción de datos web, garantizando que los datos se recopilen de manera responsable y con consentimiento.
- La aparición de plataformas de scraping como servicio, que ofrecen extracción de datos personalizada para empresas de todos los tamaños.
Con estos avances, el web scraping seguirá siendo una herramienta fundamental en el conjunto de herramientas de Big Data.
Si el web scraping manual resulta desalentador o si se necesita ayuda para desenredar desafíos complejos relacionados con la obtención de datos valiosos, ¡tenga la seguridad de que PromptCloud está listo para ayudar!
Nos especializamos en ofrecer soluciones integrales de web scraping diseñadas explícitamente para iniciativas de big data, lo que garantiza una extracción de datos confiable y a gran escala.
Confíe en nosotros para abordar los aspectos exigentes, permitiéndole concentrarse en generar decisiones bien informadas utilizando conjuntos de datos sólidos y significativos. Póngase en contacto con nosotros en sales@promptcloud.com para descubrir cómo nuestra experiencia puede impulsar su plan de juego de big data.