
¿Qué es la extracción de datos: una guía para principiantes?
Publicado: 2023-11-07En una era en la que los datos son tan valiosos como la moneda, la capacidad de extraerlos de manera eficiente puede diferenciar a su empresa de la competencia. La extracción de datos no es sólo un proceso técnico; es estratégico y, cuando se hace correctamente, puede revelar conocimientos que conduzcan a decisiones empresariales más inteligentes y a un crecimiento sólido. Esta publicación de blog profundiza en el qué, el por qué y el cómo de la extracción de datos, brindándole el conocimiento para aprovechar todo su potencial.
¿Qué es la extracción de datos?
La extracción de datos es el proceso de recuperar datos estructurados o no estructurados de diversas fuentes, como bases de datos, sitios web, documentos, imágenes, etc. Luego, estos datos se convierten a un formato más manejable y utilizable, como una hoja de cálculo o una base de datos. El objetivo es recopilar esta información de una manera que preserve su significado y al mismo tiempo la haga accesible para el análisis y la inteligencia empresarial.
Fuente: https://papersoft-dms.com/
¿Por qué es crucial la extracción de datos?
- Toma de decisiones informada: los datos extraídos proporcionan la base para análisis que pueden descubrir tendencias, predecir resultados y guiar decisiones estratégicas.
- Eficiencia: Automatizar los procesos de extracción de datos ahorra tiempo y recursos, eliminando errores manuales y redundancias.
- Integración: permite fusionar datos de fuentes dispares, proporcionando una visión holística de las operaciones.
- Ventaja competitiva: el acceso rápido a datos relevantes puede ser la ventaja que una empresa necesita para superar a la competencia.
Tipos de extracción de datos
En el mundo en el que vivimos, repleto de información, la capacidad de extraer datos de manera eficiente de una variedad de fuentes es invaluable. Los procesos de extracción de datos difieren no sólo en su metodología sino también en su aplicación. Comprender los tipos de extracción de datos le ayudará a seleccionar la técnica adecuada para sus necesidades de datos.
1. Extracción manual de datos
La extracción manual de datos es la forma más básica, que implica la participación humana para recopilar datos de fuentes físicas o digitales. Este método suele ser lento y propenso a errores, pero puede resultar útil cuando se trata de información compleja que requiere juicio humano.
2. Extracción de datos automatizada
Este tipo utiliza software y herramientas para recopilar y procesar datos automáticamente, lo que acelera significativamente el proceso y reduce la probabilidad de errores.
3. Extracción de datos web (Web Scraping)
El web scraping es una técnica utilizada para extraer datos de sitios web. Esto se hace mediante un software que imita la navegación web humana para recopilar información específica de fuentes en línea.
4. Extracción de datos estructurados
Este tipo se refiere a la recuperación de datos que están organizados en un formato estructurado, como bases de datos u hojas de cálculo, donde los datos son consistentes y siguen un esquema específico.
5. Extracción de datos no estructurados
La extracción de datos no estructurados se ocupa de datos que no siguen un formato o estructura específica, como correos electrónicos, archivos PDF o multimedia.
6. Extracción de datos semiestructurados
La extracción de datos semiestructurados es para datos que no residen en una base de datos relacional pero que tienen algunas propiedades organizativas, lo que hace que sea más fácil de analizar que los datos no estructurados.
7. Extracción de datos basada en consultas
Este método implica el uso de consultas para recuperar datos de bases de datos. Es una forma muy eficiente de extracción de datos estructurados y puede proporcionar recuperación de información programada o en tiempo real.
Técnicas de extracción de datos
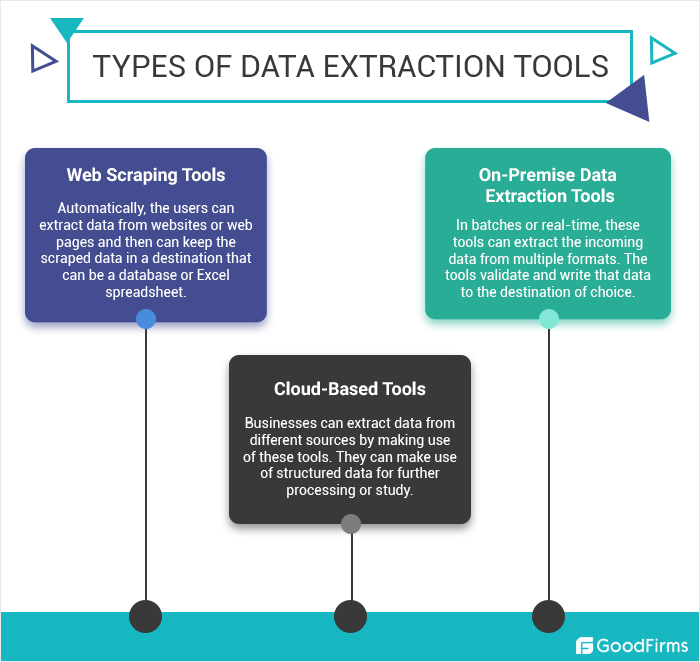
- Captura de datos automatizada: herramientas que detectan y extraen automáticamente información relevante de documentos o páginas web.
- Web Scraping: uso de software para simular la exploración humana de la web para recopilar datos específicos.
- Análisis de texto: empleo del procesamiento del lenguaje natural para extraer información de texto no estructurado.
- Procesos ETL: que significan extraer, transformar y cargar, son sistemas integrados que extraen datos de diversas fuentes, los convierten a un formato útil y los almacenan en un almacén de datos.
Mejores prácticas para una extracción de datos eficaz
- Defina objetivos claros: sepa qué necesita de sus esfuerzos de extracción de datos para elegir las herramientas y métodos adecuados.
- Garantice la calidad de los datos: valide y limpie sus datos como parte del proceso de extracción para mantener la integridad.
- Cumpla con las normas: tenga en cuenta las leyes y regulaciones de privacidad de datos para garantizar que sus métodos de extracción de datos sean legales.
- Escalabilidad: elija soluciones que puedan crecer con sus necesidades de datos para evitar futuras revisiones.
Desafíos en la extracción de datos
La extracción de datos, si bien es invaluable, presenta una serie de desafíos que pueden complicar el proceso tanto para empresas como para individuos. Estos desafíos pueden afectar la calidad, la velocidad y la eficiencia de las iniciativas basadas en datos. A continuación, profundizamos en algunos de los obstáculos comunes que se encuentran en el proceso de extracción de datos.

- Problemas de calidad de datos:
- Datos inconsistentes: extraer datos de diversas fuentes a menudo significa lidiar con inconsistencias en el formato, la estructura y la calidad, lo que puede generar conjuntos de datos inexactos.
- Datos incompletos: los valores faltantes o los registros incompletos durante la extracción pueden distorsionar los resultados analíticos.
- Duplicados: pueden producirse datos redundantes durante la extracción, lo que genera ineficiencias y resultados de análisis sesgados.
- Preocupaciones sobre la escalabilidad:
- Volumen: a medida que crecen los volúmenes de datos, resulta cada vez más difícil extraer información de manera oportuna y eficiente sin comprometer el rendimiento del sistema.
- Datos en evolución: la evolución continua de los datos requiere un proceso de extracción escalable que pueda adaptarse a los cambios sin necesidad de una reconfiguración extensa.
- Fuentes de datos complejas y diversas:
- Variedad: extraer datos de una amplia gama de fuentes con diferentes formatos (PDF, páginas web, bases de datos, etc.) requiere herramientas de extracción versátiles y sofisticadas.
- Accesibilidad: Los datos bloqueados en sistemas heredados o mediante formatos propietarios pueden ser particularmente difíciles de acceder y extraer.
- Limitaciones técnicas:
- Dificultades de integración: la integración de datos extraídos en sistemas existentes puede plantear desafíos técnicos, especialmente cuando se trata de diferentes tecnologías o infraestructura obsoleta.
- Falta de experiencia: a menudo existe una curva de aprendizaje pronunciada asociada con las herramientas y técnicas necesarias para una extracción de datos eficiente, que requiere conocimientos especializados.
- Cuestiones legales y de cumplimiento:
- Regulaciones de privacidad: Cumplir con estrictas leyes de privacidad de datos, como GDPR o HIPAA, puede complicar el proceso de extracción, ya que ciertos datos pueden requerir protocolos de manejo adicionales.
- Propiedad intelectual: al extraer datos de fuentes externas, existe el riesgo de infringir derechos de propiedad intelectual, lo que puede generar complicaciones legales.
- Extracción de datos en tiempo real:
- Latencia: existe una necesidad creciente de extracción de datos en tiempo real en ciertos sectores, como las finanzas o la seguridad, donde la latencia puede afectar significativamente la toma de decisiones.
- Infraestructura: la extracción de datos en tiempo real requiere una infraestructura sólida que pueda manejar flujos de datos continuos sin cuellos de botella.
- Transformación de datos:
- Conversión de formato: los datos extraídos a menudo deben transformarse a un formato diferente para su análisis, lo que puede ser un proceso complejo y propenso a errores.
- Mantener el contexto: Garantizar que los datos conserven su significado después de su extracción y transformación es fundamental pero desafiante, especialmente cuando se trata de datos no estructurados.
- Preocupaciones de seguridad:
- Violaciones de datos: siempre existe el riesgo de que se produzcan violaciones de datos al extraer información sensible o confidencial, lo que requiere estrictas medidas de seguridad.
- Corrupción de datos: los datos pueden dañarse durante la extracción debido a errores de software, problemas de compatibilidad o fallas de hardware.
Conclusión
Como elemento vital del proceso de análisis de datos, la extracción de datos puede parecer desalentadora, pero con el enfoque correcto, se convierte en un catalizador de conocimientos y oportunidades. Al comprender sus principios y aprovechar las tecnologías actuales, cualquier organización puede desbloquear todo el potencial de sus datos.