
¿Qué es el etiquetado de datos en el aprendizaje automático y cómo funciona?
Publicado: 2022-04-29Los datos son la nueva riqueza para las empresas de hoy. Con tecnologías como la inteligencia artificial asumiendo progresivamente la mayor parte de nuestras actividades diarias, el uso correcto de cualquier dato ha estado influyendo positivamente en la sociedad. Al segregar y etiquetar los datos de manera eficiente, los algoritmos de ML pueden descubrir los problemas y brindar soluciones prácticas y relevantes.
Con la ayuda del etiquetado de datos, le enseñamos a la máquina varias técnicas e ingresamos la información en varios formatos para que se comporten de manera "inteligente". La ciencia detrás del etiquetado de datos implica una gran cantidad de tarea en forma de anotar o etiquetar los conjuntos de datos con múltiples variaciones de la misma información. Aunque el resultado final sorprende y facilita nuestro día a día, el trabajo que hay detrás es inmenso y la dedicación encomiable.
¿Qué es el etiquetado de datos?
En el aprendizaje automático, la calidad y el tipo de datos de entrada determinan la calidad y el tipo de salida. La calidad de los datos utilizados para entrenar la máquina aumenta la precisión de su modelo de IA.
En otras palabras, el etiquetado de datos es un proceso para entrenar una máquina para encontrar las diferencias y similitudes entre los conjuntos de datos estructurados o no estructurados al etiquetarlos o anotarlos.
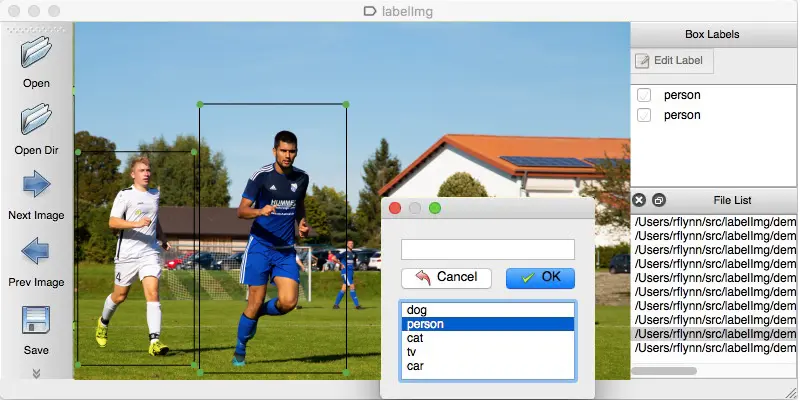
Entendamos esto con un ejemplo. Para enseñarle a la máquina que la luz roja es la señal para detenerse, debe marcar todas las luces rojas en varias imágenes para que la máquina entienda la señal. En base a esto, AI crea un algoritmo que leerá la luz roja como una señal de alto en cada escenario dado. Otro ejemplo es que los géneros musicales se pueden segregar con múltiples conjuntos de datos bajo las etiquetas jazz, pop, rock, clásica y más.
Desafíos en el etiquetado de datos
Cualquier nuevo cambio/avance en tecnología o estructura trae consigo sus beneficios y desafíos. No es diferente para el etiquetado de datos. Si bien el etiquetado de datos puede reducir drásticamente el tiempo para escalar un negocio , tiene un costo. Detengámonos en algunos de los desafíos que trae consigo el etiquetado de datos.
Costo en términos de tiempo y esfuerzo
Es una tarea desafiante en sí misma obtener los datos específicos del nicho en grandes cantidades. La adición manual de etiquetas para cada elemento solo se suma a la tarea que ya consume mucho tiempo. Si el proyecto se maneja internamente, la mayor parte del tiempo del proyecto se dedica a tareas relacionadas con los datos, como la recopilación, preparación y etiquetado de datos.
Para administrar estas tareas de manera efectiva, de modo que pueda hacer bien el trabajo a la primera, necesitará etiquetadores expertos con esta experiencia específica. Esta es también una empresa costosa, lo que la hace costosa, no solo en términos de tiempo sino también en dinero.
Inconsecuencia
Los anotadores con diferente experiencia pueden tener diferentes criterios de etiquetado. En consecuencia, existe una alta posibilidad de etiquetado inconsistente. Dicho esto, cuando varias personas etiquetan el mismo conjunto de datos, las tasas de precisión de los datos serán mucho más altas.
Experiencia en el campo
Para industrias específicas, sentirá la necesidad de contratar etiquetadores con experiencia en un dominio específico. Por ejemplo, para crear una aplicación ML para la industria de la salud , a los anotadores sin experiencia en el dominio relevante les resultará muy difícil etiquetar los elementos correctamente.
Imperfecciones
Cualquier trabajo repetitivo realizado por humanos es propenso a errores. Cualquiera que sea el nivel de experiencia que pueda tener el etiquetador humano, el etiquetado manual siempre tendrá el alcance de la imperfección. Garantizar cero errores es casi imposible ya que los anotadores tienen que lidiar con grandes conjuntos de datos sin procesar para el etiquetado.
Enfoques para el etiquetado de datos
Como se mencionó anteriormente, el etiquetado de datos es una tarea que requiere mucho tiempo y atención a los detalles. Según la declaración del problema, la cantidad de datos que se van a etiquetar, la complejidad de los datos y el estilo, la estrategia aplicada para anotar los datos variará.
Revisemos varios enfoques por los que su empresa puede optar en función de los recursos financieros y el tiempo disponible.
Etiquetado de datos interno
Según el tipo de industria, el tiempo disponible para completar el proyecto de IA dado y la disponibilidad de los recursos necesarios, las organizaciones pueden realizar internamente el proceso de etiquetado de datos.
Ventajas:
- Alta precisión
- Alta calidad
- Seguimiento simplificado
Contras:
- Consume mucho tiempo/lento
- Requiere amplios recursos
Colaboración colectiva
Los conjuntos de datos de abastecimiento que están etiquetados por autónomos están disponibles en varias plataformas de crowdsourcing. Este método se puede utilizar para anotar datos generalizados como imágenes.
El ejemplo más famoso de etiquetado de datos a través de crowdsourcing es Recaptcha. Se le pide al usuario que identifique tipos específicos de imágenes para probar que son humanos. Estos se verifican en función de las entradas proporcionadas por otros usuarios. Esto actúa como una base de datos de etiquetas para una matriz de imágenes.
Ventajas:
- Rapido y Facil
- Económico
Contras:
- No se puede usar para datos que requieren experiencia en el dominio
- La calidad no está garantizada.
Subcontratación
La subcontratación puede actuar como un punto medio entre el etiquetado interno de datos y el crowdsourcing. La contratación de organizaciones de terceros o personas con experiencia en el dominio puede ayudar a las organizaciones con todos los proyectos a corto y largo plazo.
Ventajas:
- Óptimo para proyectos temporales de alto nivel
- Las empresas de subcontratación de terceros proporcionan personal examinado
- Proporciona herramientas de etiquetado de datos preconstruidas y personalizadas según las necesidades de su negocio
- Puede obtener la opción de expertos en etiquetado de datos específicos de nicho
Contras:
- La gestión del tercero puede llevar mucho tiempo
Basado en máquina
Una de las últimas formas de etiquetado y anotación de datos que es ampliamente utilizada y aceptada por las industrias es la anotación basada en máquinas. La automatización del proceso de etiquetado de datos con la ayuda del software de etiquetado de datos reduce la intervención humana y aumenta la velocidad a la que se puede realizar el etiquetado. Con la técnica llamada aprendizaje activo, los datos se pueden etiquetar en función de los cuales las etiquetas se pueden agregar a los conjuntos de datos de entrenamiento automáticamente.
Ventajas:
- Procesamiento y etiquetado de datos más rápido
- Implica una menor intervención humana.
Contras:
- Aunque de mejor calidad pero no a la par con el etiquetado humano
- En caso de errores, aún se requiere la intervención humana.

¿Cómo funciona el etiquetado de datos?
En función de las necesidades de su negocio, puede elegir el enfoque que mejor se adapte a sus requisitos. Sin embargo, el proceso de etiquetado de datos funciona en el siguiente orden cronológico.
Recopilación de datos
La base de cualquier proyecto de aprendizaje automático son los datos. La recopilación de la cantidad correcta de datos sin procesar en varios formatos comprende el primer paso del etiquetado de datos. La recopilación de datos puede ser de dos formas: una que la empresa ha estado recopilando internamente y la otra, que se recopila de fuentes externas que están disponibles públicamente.
Al estar en forma sin procesar, estos datos requieren limpieza y procesamiento antes de crear las etiquetas para los conjuntos de datos. Estos datos limpios y preprocesados luego se alimentan al modelo para su entrenamiento. Cuanto más grandes y diversificados sean los datos, más precisos serán los resultados.
anotación de datos
Una vez que se limpian los datos, los expertos del dominio revisan los datos y agregan etiquetas siguiendo varios enfoques de etiquetado de datos. El contexto significativo se adjunta al modelo que se puede usar como verdad básica . Estas son las variables de destino, como las imágenes, que desea que el modelo prediga.

Seguro de calidad
El éxito del entrenamiento del modelo ML depende en gran medida de la calidad de los datos que deben ser confiables, precisos y consistentes. Para garantizar estas etiquetas de datos precisas y precisas, debe haber controles de calidad regulares. Con el uso de algoritmos de control de calidad como el Consenso y la prueba alfa de Cronbach, se puede determinar la precisión de estas anotaciones. Los controles regulares de control de calidad contribuyen en gran medida a la precisión de los resultados.
Entrenamiento y prueba de modelos
Realizar todos los pasos anteriores solo tiene sentido si se prueba la precisión de los datos. Ingresar el conjunto de datos no estructurados para ver si ofrece los resultados esperados pondrá a prueba el proceso.
Casos de uso de la industria para el etiquetado de datos
Ahora que estamos familiarizados con lo que es el etiquetado de datos y cómo funciona, revisemos los casos de uso más destacados.
Visión artificial (CV)
Este es un subconjunto de IA que permite a las máquinas derivar una interpretación significativa de las entradas proporcionadas en forma de imágenes y videos (imágenes fijas extraídas para el etiquetado).
La anotación de visión por computadora se puede utilizar en varias industrias para implementar los beneficios prácticos de la IA.
- En la industria automotriz, el etiquetado de imágenes y videos para segmentar carreteras, edificios, peatones y otros objetos ayudará a los vehículos autónomos a distinguir entre estas entidades para evitar el contacto en la vida real.
- En la industria de la salud, los síntomas de la enfermedad se pueden segmentar en una radiografía, una resonancia magnética y una tomografía computarizada. Con la ayuda de imágenes microscópicas, la mayoría de las enfermedades críticas se pueden diagnosticar en una etapa temprana.
- Los códigos QR, códigos de barras de etiquetas, etc. se pueden usar como etiquetas en la industria del transporte y la logística para rastrear mercancías.
Procesamiento del lenguaje natural (PNL)
Este es un subconjunto que permite que las máquinas de IA interpreten el lenguaje humano y las estadísticas. Derivando el significado del texto y el habla, el algoritmo puede analizar varios aspectos lingüísticos.
La PNL se utiliza cada vez más en muchas soluciones empresariales .
- Se usa comúnmente en todas las industrias como asistente de correo electrónico, función de autocompletar, corrector ortográfico, segregación de correos electrónicos no deseados y no deseados, y mucho más.
- En forma de chatbots , las consultas básicas planteadas por los clientes se interpretan y responden sin intervención humana en tiempo real. Se prevé que el 70% de las interacciones con los clientes serán gestionadas por chatbots y aplicaciones de mensajería móvil para el año 2023.
- La comprensión de la polaridad negativa y positiva del texto para capturar el sentimiento del cliente se realiza mediante el etiquetado de datos en el comercio electrónico.
Appinventiv ha creado con éxito una aplicación de redes sociales para Vyrb que permite a los usuarios enviar y recibir mensajes de audio optimizados para dispositivos portátiles Bluetooth.

Descripción general del mercado de etiquetado de datos de IA
El etiquetado de datos es una industria floreciente que nace de la tecnología de IA . Dado que el etiquetado de datos depende en gran medida de que los datos precisos se introduzcan en el aprendizaje automático, está destinado a crecer en los próximos años.
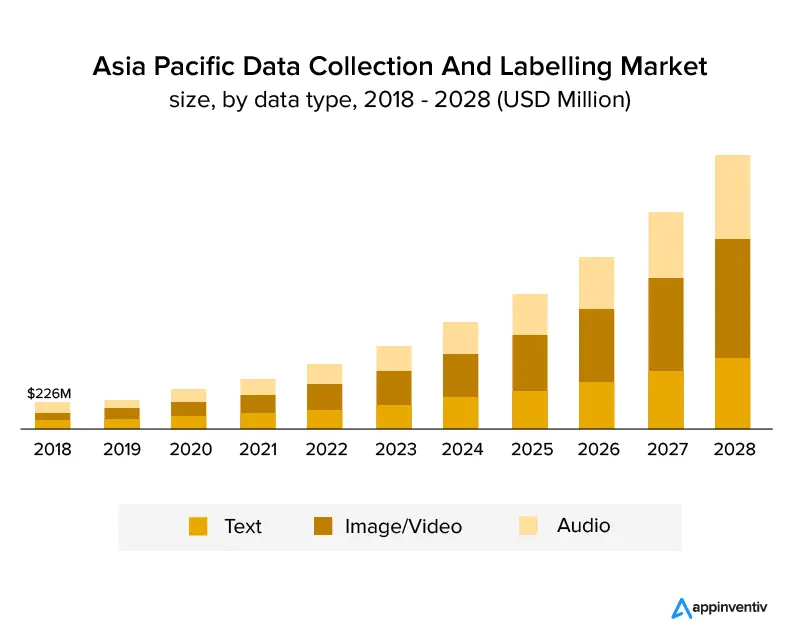
El siguiente gráfico muestra claramente que la industria ha crecido y seguirá creciendo en los próximos años. Se espera que crezca a un crecimiento anual compuesto del 25,6 % y alcance un tamaño de mercado de USD 8220 millones para 2028. El siguiente gráfico muestra el crecimiento por tipo de datos.
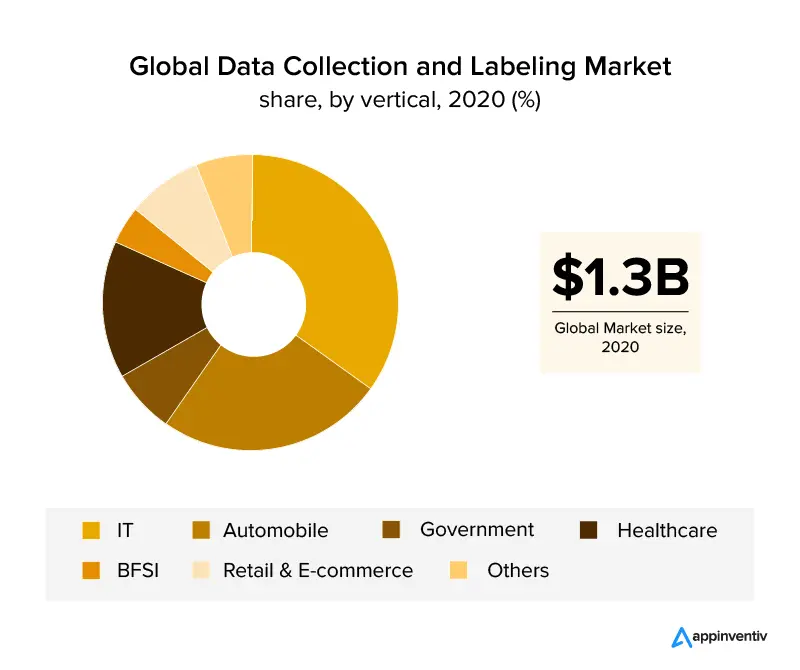
Una descripción general de las verticales comerciales que han explotado el etiquetado de datos son los sectores de TI y automotriz, que cubren más del 30% de los ingresos globales. Con el crecimiento de la industria de la salud , se espera que el etiquetado de datos crezca debido a los requisitos de datos precisos para aplicaciones eficientes basadas en IA en el sector. Con la ayuda del etiquetado de imágenes, las industrias minorista y de comercio electrónico también han asegurado una participación de mercado significativa en la industria del etiquetado de datos.
Etiquetado de datos con Appinventiv
Estratégicamente, las empresas han subcontratado la recopilación de datos y los servicios de etiquetado para crear modelos sólidos de aprendizaje automático.
Appinventiv es una empresa de desarrollo de IA y ML que ha estado ayudando a las organizaciones a desbloquear oportunidades con soluciones impulsadas por IA durante muchos años . Con casi una década de experiencia en la transformación de negocios, hemos entregado con éxito muchos proyectos complejos de IA para diferentes industrias.
Por ejemplo, Appinventiv ha automatizado con éxito el proceso bancario de un banco líder en Europa. El proceso de automatización ayudó al banco a mejorar la precisión en un 50 % y los niveles de servicio de los cajeros automáticos en un 92 %.
Otro ejemplo en el que Appinventiv ayudó a YouCOMM a crear una solución revolucionaria para transformar la comunicación con los pacientes en el hospital al brindar acceso en tiempo real a la ayuda médica. Con un sistema de mensajes personalizable para el paciente, los pacientes pueden notificar fácilmente al personal sobre sus necesidades a través de comandos de voz y el uso de gestos con la cabeza.
Con nuestra experiencia y equipo centrado en el cliente, brindamos los servicios de etiquetado de datos que lo ayudarán a superar los desafíos brindándole servicios de etiquetado de datos holísticos en función de sus necesidades y requisitos específicos.
Al aprovechar la amplia gama de herramientas necesarias para el etiquetado y la anotación de datos, Appinventiv puede mejorar sus procesos de entrenamiento de datos para simplificar modelos complejos. Esto nos permite superarnos en términos de precisión de segmentación, clasificación y, posteriormente, el etiquetado de datos que será rápido y fácil.
¡Terminando!
“El poder de la inteligencia artificial es tan increíble que cambiará la sociedad de maneras muy profundas”. - Bill Gates
La inteligencia artificial tiene el potencial de facilitar la vida humana y, por lo tanto, hacer el bien a la sociedad. Su capacidad de clasificar grandes cantidades de datos en instrucciones significativas con la ayuda del etiquetado de datos ha ayudado a las industrias a avanzar y crecer a pasos agigantados.
Preguntas más frecuentes
P. ¿Cuáles son las mejores prácticas para perfeccionar el etiquetado de datos?
R. Según el enfoque que adopte para el etiquetado de datos, existen algunas prácticas recomendadas que puede seguir:
- Asegúrese de que los datos recopilados sean adecuados, se limpien y procesen correctamente.
- Según la industria, asigne el trabajo solo a etiquetadores de datos expertos en el dominio.
- Asegúrese de que el equipo siga un enfoque uniforme al proporcionarles los criterios de técnicas de anotación que deben seguir.
- Siga un proceso de verificador de creadores mediante la asignación de múltiples anotadores para el etiquetado cruzado.
P. ¿Cuáles son los beneficios del etiquetado de datos?
R. El etiquetado de datos ayuda a proporcionar una mayor claridad sobre el contexto, la calidad y la facilidad de uso para hacer una predicción precisa de los datos. Esto, a su vez, ayuda a mejorar la usabilidad de los datos de las variables en el modelo.
P. ¿Cuáles son los diversos elementos a tener en cuenta al preseleccionar empresas de etiquetado de datos?
R. Hay cinco parámetros a considerar al elegir los servicios de etiquetas de datos para el aprendizaje automático.
- Escalabilidad del proceso de etiquetado de datos
- Costo del servicio de etiquetado de datos
- Seguridad de datos
- Plataforma de etiquetado de datos