
¿Qué es el data scraping? Técnicas, herramientas y casos de uso
Publicado: 2023-12-29En el vertiginoso mundo de la información, las empresas se están sumergiendo de lleno en el ámbito de la información basada en datos para dar forma a sus movimientos estratégicos. Exploremos el cautivador universo del data scraping, un proceso astuto que extrae información de sitios web y sienta las bases para la recopilación de datos esenciales.
Únase a nosotros mientras navegamos por las complejidades de la extracción de datos, revelando una variedad de herramientas, técnicas avanzadas y consideraciones éticas que añaden profundidad y significado a esta práctica revolucionaria.
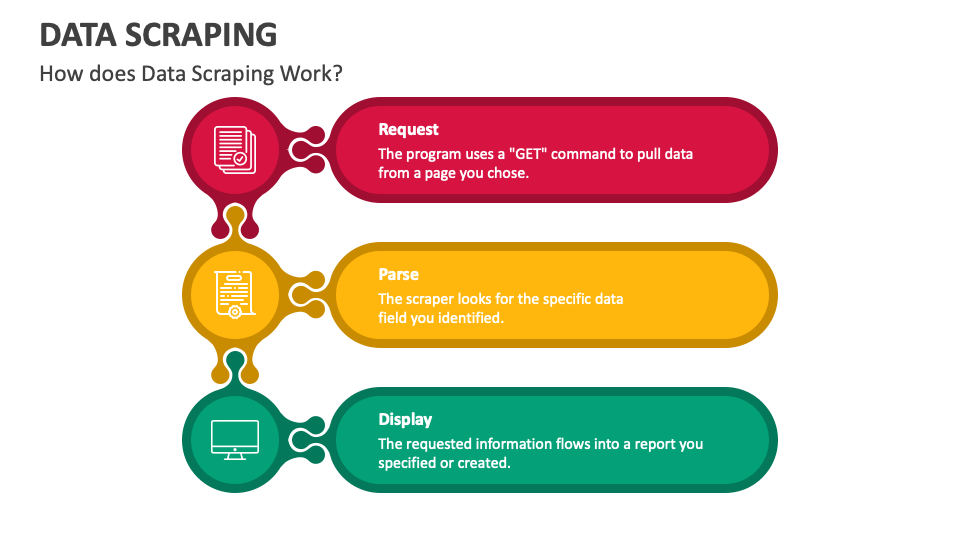
Fuente de la imagen: https://www.collidu.com/
Herramientas de extracción de datos
Embarcarse en una aventura de extracción de datos requiere familiarizarse con una variedad de herramientas, cada una con sus propias peculiaridades y aplicaciones:
- Software de raspado web: sumérjase en programas como Octoparse o Import.io, que ofrecen a los usuarios, independientemente de su experiencia técnica, el poder de extraer datos sin esfuerzo.
- Lenguajes de programación: el dúo dinámico de Python y R, junto con bibliotecas como Beautiful Soup o rvest, ocupa un lugar central para crear scripts de scraping personalizados.
- Extensiones del navegador: herramientas como Web Scraper o Data Miner brindan opciones ingeniosas en el navegador para esas tareas rápidas de scraping.
- API: algunos sitios web ofrecen generosamente API, lo que agiliza la recuperación de datos estructurados y reduce la dependencia de las técnicas tradicionales de scraping.
- Navegadores sin cabeza: conozca Puppeteer y Selenium, los maestros de la automatización que simulan la interacción del usuario para extraer contenido dinámico.
Cada herramienta cuenta con ventajas y curvas de aprendizaje únicas, lo que hace que el proceso de selección sea un baile estratégico que se alinea con los requisitos del proyecto y la destreza técnica del usuario.
Dominar las técnicas de extracción de datos
La extracción eficiente de datos es un arte que implica varias técnicas que garantizan un proceso de recopilación fluido de diversas fuentes. Estas técnicas incluyen:
- Web Scraping automatizado: libere bots o rastreadores web para recopilar información de los sitios web de forma elegante.
- API Scraping: aproveche el poder de las interfaces de programación de aplicaciones (API) para extraer datos en un formato estructurado.
- Análisis HTML: navegue por el panorama de la página web analizando el código HTML para extraer los datos necesarios.
- Extracción de puntos de datos: la precisión importa: identifique y extraiga puntos de datos específicos en función de parámetros y palabras clave predeterminados.
- Resolución de captcha: conquiste los captchas de seguridad con tecnología para superar las barreras establecidas para proteger los sitios web del scraping automatizado.
- Servidores proxy: utilice diferentes direcciones IP para evitar prohibiciones de IP y limitaciones de velocidad mientras recopila grandes cantidades de datos.
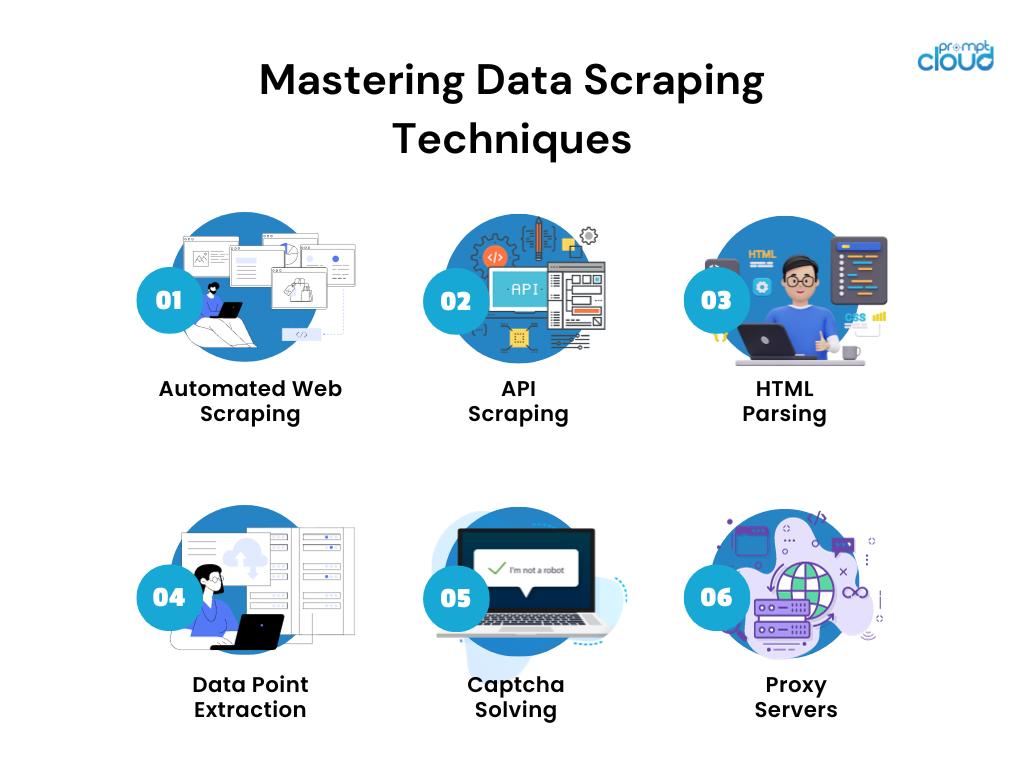
Estas técnicas garantizan la extracción de datos sensibles y específicos, respetando el delicado equilibrio entre la eficiencia y los límites legales del web scraping.
Mejores prácticas para obtener resultados de calidad
Para lograr resultados de primer nivel en la extracción de datos, siga estas mejores prácticas:
- Respete Robots.txt: siga las reglas descritas en el archivo robots.txt de los sitios web: acceda únicamente a los datos permitidos.
- Cadena de agente de usuario: presente una cadena de agente de usuario legítima para evitar confundir a los servidores web sobre la identidad de su raspador.
- Limitación de solicitudes: implemente pausas entre solicitudes para aligerar la carga del servidor, evitando el temido bloqueo de IP.
- Evitar problemas legales: navegue con delicadeza por el panorama de las normas legales, las leyes de privacidad de datos y los términos de uso de los sitios web.
- Manejo de errores: diseñe un manejo de errores sólido para navegar por cambios inesperados en la estructura del sitio web o problemas con el servidor.
- Comprobaciones de calidad de los datos: revise y limpie periódicamente los datos extraídos para garantizar su precisión e integridad.
- Codificación eficiente: emplee prácticas de codificación eficientes para crear raspadores escalables y mantenibles.
- Diversas fuentes de datos: mejore la riqueza y confiabilidad de su conjunto de datos recopilando datos de múltiples fuentes.
Consideraciones éticas en el mundo del data scraping
Si bien la extracción de datos revela conocimientos invaluables, debe abordarse con diligencia ética:

- Respeto por la privacidad: trate los datos personales con las máximas consideraciones de privacidad, alineándose con regulaciones como el GDPR.
- Transparencia: Mantener informados a los usuarios si se están recabando sus datos y con qué finalidad.
- Integridad: evite cualquier tentación de manipular los datos extraídos de manera engañosa o dañina.
- Utilización de datos: utilice los datos de manera responsable, garantizando que beneficien a los usuarios y evitando prácticas discriminatorias.
- Cumplimiento legal: respete las leyes que rigen las actividades de extracción de datos para evitar posibles repercusiones legales.

Fuente de la imagen: https://dataforest.ai/
Casos de uso de extracción de datos
Explore las aplicaciones versátiles de la extracción de datos en diversas industrias:
- Finanzas: descubra las tendencias del mercado consultando foros financieros y sitios de noticias. Esté atento a los precios de la competencia para detectar oportunidades de inversión.
- Hotel: agregue opiniones de clientes de diferentes plataformas para analizar la satisfacción de los huéspedes. Esté atento a los precios de la competencia para obtener estrategias de precios óptimas.
- Aerolínea: recopile y compare datos de precios de vuelos para realizar análisis competitivos. Realice un seguimiento de la disponibilidad de asientos para informar los modelos de precios dinámicos.
- Comercio electrónico: obtenga detalles de productos, reseñas y precios de diferentes proveedores para compararlos en el mercado. Supervise los niveles de existencias en todas las plataformas para una gestión eficaz de la cadena de suministro.
Conclusión: lograr un equilibrio armonioso en la extracción de datos
A medida que nos aventuramos en el vasto mundo del data scraping, encontrar ese punto óptimo es clave. Con las herramientas adecuadas, técnicas inteligentes y dedicación para hacer las cosas bien, tanto las empresas como los individuos pueden aprovechar el verdadero poder de la extracción de datos.
Cuando manejamos esta práctica innovadora con responsabilidad y apertura, no solo genera innovación, sino que también desempeña un papel en la configuración de un ecosistema de datos reflexivo y floreciente para todos los involucrados.
Preguntas frecuentes:
¿Qué es el trabajo de extracción de datos?
El trabajo de extracción de datos implica la extracción de información de sitios web, lo que permite a personas o empresas recopilar datos valiosos para diversos fines, como investigaciones de mercado, análisis competitivos o seguimiento de tendencias. Es como tener un detective que examina el contenido web para descubrir joyas de información ocultas.
¿Es legal extraer datos?
La legalidad de la extracción de datos depende de cómo se hace y de si se respetan los términos de uso y las normas de privacidad de los sitios web de destino. En general, extraer datos públicos para uso personal puede ser legal, pero extraer datos privados o protegidos por derechos de autor sin permiso probablemente sea ilegal. Es fundamental conocer y respetar los límites legales para evitar posibles consecuencias.
¿Qué es la técnica de raspado de datos?
Las técnicas de extracción de datos abarcan una variedad de métodos, desde la extracción web automatizada mediante bots o rastreadores hasta el aprovechamiento de API para la extracción de datos estructurados. El análisis de HTML, la extracción de puntos de datos, la resolución de captcha y los servidores proxy se encuentran entre las diversas técnicas empleadas para recopilar datos de manera eficiente de diversas fuentes. La elección de la técnica depende de los requisitos específicos del proyecto de raspado.
¿Es fácil la extracción de datos?
Que la extracción de datos sea fácil depende de la complejidad de la tarea y de las herramientas o técnicas involucradas. Para aquellos sin experiencia técnica, un software de web scraping fácil de usar o la subcontratación a proveedores de servicios de web scraping pueden simplificar el proceso. La elección de subcontratar permite a las personas o empresas aprovechar la experiencia de los profesionales, garantizando una extracción de datos precisa y eficiente sin profundizar en las complejidades técnicas del proceso de extracción.