
Qué es Robots.txt en SEO: cómo crearlo y optimizarlo
Publicado: 2022-04-22El tema de hoy no está directamente relacionado con la monetización del tráfico. Pero robots.txt puede afectar el SEO de su sitio web y, eventualmente, la cantidad de tráfico que recibe. Muchos administradores web han arruinado las clasificaciones de sus sitios web debido a entradas de robots.txt fallidas. Esta guía le ayudará a evitar todos esos escollos. ¡Asegúrate de leer hasta el final!
- ¿Qué es un archivo robots.txt?
- ¿Cómo se ve un archivo robots.txt?
- Cómo encontrar su archivo robots.txt
- ¿Cómo funciona un archivo Robots.txt?
- Sintaxis de robots.txt
- Directivas admitidas
- Agente de usuario*
- Permitir
- Rechazar
- mapa del sitio
- Directivas no admitidas
- Demora de rastreo
- Sin índice
- No seguir
- ¿Necesita un archivo robots.txt?
- Creación de un archivo robots.txt
- Archivo Robots.txt: mejores prácticas de SEO
- Use una nueva línea para cada directiva
- Use comodines para simplificar las instrucciones
- Use el signo de dólar "$" para especificar el final de una URL
- Use cada agente de usuario solo una vez
- Use instrucciones específicas para evitar errores no intencionales
- Ingrese comentarios en el archivo robots.txt con un hash
- Use diferentes archivos robots.txt para cada subdominio
- No bloquees buen contenido
- No abuses del retardo de rastreo
- Preste atención a la distinción entre mayúsculas y minúsculas
- Otras mejores prácticas:
- Uso de robots.txt para evitar la indexación de contenido
- Uso de robots.txt para proteger contenido privado
- Uso de robots.txt para ocultar contenido duplicado malicioso
- Acceso total para todos los bots
- Sin acceso para todos los bots
- Bloquear un subdirectorio para todos los bots
- Bloquee un subdirectorio para todos los bots (con un archivo permitido)
- Bloquear un archivo para todos los bots
- Bloquee un tipo de archivo (PDF) para todos los bots
- Bloquear todas las URL parametrizadas solo para Googlebot
- Cómo probar su archivo robots.txt en busca de errores
- URL enviada bloqueada por robots.txt
- Bloqueado por robots.txt
- Indexado, aunque bloqueado por robots.txt
- Robots.txt vs meta robots vs x-robots
- Otras lecturas
- Terminando
¿Qué es un archivo robots.txt?
El robots.txt, o protocolo de exclusión de robots, es un conjunto de estándares web que controla cómo los robots de los motores de búsqueda rastrean cada página web, hasta las marcas de esquema en esa página. Es un archivo de texto estándar que incluso puede evitar que los rastreadores web obtengan acceso a todo su sitio web o partes de él.
Mientras ajusta el SEO y resuelve problemas técnicos, puede comenzar a obtener ingresos pasivos de los anuncios. ¡Una sola línea de código en su sitio web devuelve pagos regulares!
A Contenidos ↑¿Cómo se ve un archivo robots.txt?
La sintaxis es simple: le das reglas a los bots especificando su agente de usuario y sus directivas. El archivo tiene el siguiente formato básico:
Mapa del sitio: [Ubicación URL del mapa del sitio]
Agente de usuario: [identificador de bot]
[directiva 1]
[directiva 2]
[directiva…]
Agente de usuario: [otro identificador de bot]
[directiva 1]
[directiva 2]
[directiva…]
Cómo encontrar su archivo robots.txt
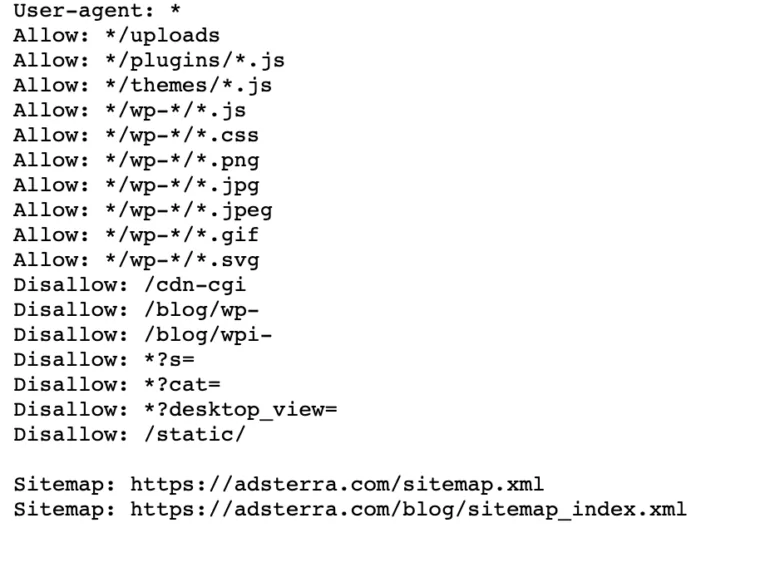
Si su sitio web ya tiene un archivo robot.txt, puede encontrarlo en esta URL: https://yourdomainname.com/robots.txt en su navegador. Por ejemplo, aquí está nuestro archivo
¿Cómo funciona un archivo Robots.txt?
Un archivo robots.txt es un archivo de texto sin formato que no contiene ningún código de marcado HTML (de ahí la extensión .txt). Este archivo, como todos los demás archivos del sitio web, se almacena en el servidor web. Es poco probable que los usuarios visiten esta página porque no está vinculada a ninguna de sus páginas, pero la mayoría de los bots rastreadores web la buscan antes de rastrear todo el sitio web.
Un archivo robots.txt puede dar instrucciones a los bots, pero no puede hacer cumplir esas instrucciones. Un buen bot, como un rastreador web o un bot de suministro de noticias, verificará el archivo y seguirá las instrucciones antes de visitar cualquier página de dominio. Pero los bots maliciosos ignorarán o procesarán el archivo para encontrar páginas web prohibidas.
En una situación en la que un archivo robots.txt contiene comandos en conflicto, el bot utilizará el conjunto de instrucciones más específico.
A Contenidos ↑Sintaxis de robots.txt
Un archivo robots.txt consta de varias secciones de "directivas", cada una de las cuales comienza con un agente de usuario. El agente de usuario especifica el bot de rastreo con el que se comunica el código. Puede dirigirse a todos los motores de búsqueda a la vez o administrar motores de búsqueda individuales.
Cada vez que un bot rastrea un sitio web, actúa en las partes del sitio que lo llaman.
Agente de usuario: *
No permitir: /
Agente de usuario: robot de Google
Rechazar:
Agente de usuario: Bingbot
No permitir: /no-para-bing/
Directivas admitidas
Las directivas son pautas que desea que sigan los agentes de usuario que declara. Actualmente, Google admite las siguientes directivas.
Agente de usuario*
Cuando un programa se conecta a un servidor web (un robot o un navegador web normal), envía un encabezado HTTP llamado "agente de usuario" que contiene información básica sobre su identidad. Cada motor de búsqueda tiene un agente de usuario. Los robots de Google se conocen como Googlebot, los de Yahoo como Slurp y los de Bing como BingBot. El agente de usuario inicia una secuencia de directivas, que pueden aplicarse a agentes de usuario específicos o a todos los agentes de usuario.
Permitir
La directiva allow le dice a los motores de búsqueda que rastreen una página o un subdirectorio, incluso un directorio restringido. Por ejemplo, si desea que los motores de búsqueda no puedan acceder a todas las publicaciones de su blog excepto a una, su archivo robots.txt podría verse así:
Agente de usuario: *
No permitir: /blog
Permitir: /blog/publicación permitida
Sin embargo, los motores de búsqueda pueden acceder a /blog/publicación permitida pero no pueden acceder a:
/blog/otro-post
/blog/otra-publicación-más
/blog/descarga-me.pd
Rechazar
La directiva disallow (que se agrega al archivo robots.txt de un sitio web) le dice a los motores de búsqueda que no rastreen una página específica. En la mayoría de los casos, esto también evitará que una página aparezca en los resultados de búsqueda.
Puede usar esta directiva para indicar a los motores de búsqueda que no rastreen archivos y páginas en una carpeta específica que está ocultando al público en general. Por ejemplo, contenido en el que aún está trabajando pero que se publicó por error. Su archivo robots.txt podría tener este aspecto si desea evitar que todos los motores de búsqueda accedan a su blog:
Agente de usuario: *
No permitir: /blog
Esto significa que tampoco se rastrearán todos los subdirectorios del directorio /blog. Esto también impediría que Google acceda a las URL que contengan /blog.
A Contenidos ↑mapa del sitio
Los sitemaps son una lista de páginas que desea que los motores de búsqueda rastreen e indexen. Si usa la directiva del mapa del sitio, los motores de búsqueda sabrán la ubicación de su mapa del sitio XML. La mejor opción es enviarlos a las herramientas para webmasters de los motores de búsqueda porque cada uno puede proporcionar información valiosa sobre su sitio web para los visitantes.
Es importante tener en cuenta que no es necesario repetir la directiva del mapa del sitio para cada agente de usuario y no se aplica a un agente de búsqueda. Agregue las directivas de su mapa del sitio al principio o al final de su archivo robots.txt.
Un ejemplo de una directiva de mapa de sitio en el archivo:
Mapa del sitio: https://www.domain.com/sitemap.xml
Agente de usuario: robot de Google
No permitir: /blog/
Permitir: /blog/título-de-la-publicación/
Agente de usuario: Bingbot
No permitir: /servicios/
A Contenidos ↑Directivas no admitidas
Las siguientes son directivas que Google ya no admite , algunas de las cuales técnicamente nunca fueron respaldadas.
Demora de rastreo
Yahoo, Bing y Yandex responden rápidamente a la indexación de sitios web y reaccionan a la directiva de demora de rastreo, que los mantiene bajo control por un tiempo.
Aplica esta línea a tu bloque:
Agente de usuario: Bingbot
Retardo de rastreo: 10
Significa que los motores de búsqueda pueden esperar diez segundos antes de rastrear el sitio web o diez segundos antes de volver a acceder al sitio web después del rastreo, que es lo mismo pero ligeramente diferente según el agente de usuario en uso.
Sin índice
La metaetiqueta noindex es una excelente manera de evitar que los motores de búsqueda indexen una de sus páginas. La etiqueta permite que los bots accedan a las páginas web, pero también les informa que no las indexen.
- Encabezado de respuesta HTTP con etiqueta noindex. Puede implementar esta etiqueta de dos maneras: un encabezado de respuesta HTTP con una etiqueta X-Robots o una etiqueta <meta> colocada dentro de la sección <head>. Así es como debería verse su etiqueta <meta>:
<meta nombre=”robots” content=”noindex”>
- Código de estado HTTP 404 y 410. Los códigos de estado 404 y 410 indican que una página ya no está disponible. Después de rastrear y procesar las páginas 404/410, las eliminan automáticamente del índice de Google. Para reducir el riesgo de páginas de error 404 y 410, rastree su sitio web regularmente y use redireccionamientos 301 para dirigir el tráfico a una página existente cuando sea necesario.
No seguir
Nofollow indica a los motores de búsqueda que no sigan enlaces en páginas y archivos en una ruta específica. Desde el 1 de marzo de 2020, Google ya no considera los atributos nofollow como directivas. En cambio, serán sugerencias, al igual que las etiquetas canónicas. Si desea un atributo "nofollow" para todos los enlaces en una página, use la metaetiqueta del robot, el encabezado x-robots o el atributo de enlace rel= "nofollow" .
Anteriormente, podía usar la siguiente directiva para evitar que Google siguiera todos los enlaces de su blog:
Agente de usuario: robot de Google
Nofollow: /blog/
¿Necesita un archivo robots.txt?
Muchos sitios web menos complejos no necesitan uno. Si bien Google no suele indexar las páginas web bloqueadas por robots.txt, no hay forma de garantizar que estas páginas no aparezcan en los resultados de búsqueda. Tener este archivo le brinda más control y seguridad del contenido de su sitio web sobre los motores de búsqueda.
Los archivos de robots también lo ayudan a lograr lo siguiente:
- Evite que se rastree el contenido duplicado.
- Mantener la privacidad de las diferentes secciones del sitio web.
- Restrinja el rastreo de resultados de búsqueda internos.
- Evite la sobrecarga del servidor.
- Evite el desperdicio del "presupuesto de rastreo".
- Mantenga imágenes, videos y archivos de recursos fuera de los resultados de búsqueda de Google.
Estas medidas afectan en última instancia a sus tácticas de SEO. Por ejemplo, el contenido duplicado confunde a los motores de búsqueda y los obliga a elegir cuál de las dos páginas posicionar primero. Independientemente de quién haya creado el contenido, es posible que Google no seleccione la página original para los mejores resultados de búsqueda.

En los casos en que Google detecte contenido duplicado destinado a engañar a los usuarios o manipular las clasificaciones, ajustará la indexación y la clasificación de su sitio web. Como resultado, la clasificación de su sitio puede sufrir o eliminarse por completo del índice de Google, desapareciendo de los resultados de búsqueda.
Mantener la privacidad de las diferentes secciones del sitio web también mejora la seguridad de su sitio web y lo protege de los piratas informáticos. A la larga, estas medidas harán que su sitio web sea más seguro, confiable y rentable.
¿Es usted propietario de un sitio web que quiere beneficiarse del tráfico? ¡Con Adsterra, obtendrá ingresos pasivos de cualquier sitio web!
A Contenidos ↑Creación de un archivo robots.txt
Necesitará un editor de texto como el Bloc de notas.
- Cree una nueva hoja, guarde la página en blanco como 'robots.txt' y comience a escribir directivas en el documento .txt en blanco.
- Inicie sesión en su cPanel, navegue hasta el directorio raíz del sitio, busque la carpeta public_html .
- Arrastre su archivo a esta carpeta y luego vuelva a verificar si el permiso del archivo está configurado correctamente.
Puede escribir, leer y editar el archivo como propietario, pero no se permiten terceros. Debería aparecer un código de permiso "0644" en el archivo. De lo contrario, haga clic derecho en el archivo y elija "permiso de archivo".
Archivo Robots.txt: mejores prácticas de SEO
Use una nueva línea para cada directiva
Debe declarar cada directiva en una línea separada. De lo contrario, los motores de búsqueda se confundirán.
Agente de usuario: *
No permitir: /directorio/
No permitir: /otro-directorio/
Use comodines para simplificar las instrucciones
Puede usar comodines (*) para todos los agentes de usuario y hacer coincidir los patrones de URL al declarar directivas. El comodín funciona bien para las URL que tienen un patrón uniforme. Por ejemplo, es posible que desee evitar que se rastreen todas las páginas de filtro con un signo de interrogación (?) en sus URL.
Agente de usuario: *
No permitir: /*?
Use el signo de dólar "$" para especificar el final de una URL
Los motores de búsqueda no pueden acceder a las URL que terminan en extensiones como .pdf. Eso significa que no podrán acceder a /file.pdf, pero podrán acceder a /file.pdf?id=68937586, que no termina en ".pdf". Por ejemplo, si desea evitar que los motores de búsqueda accedan a todos los archivos PDF de su sitio web, su archivo robots.txt podría verse así:
Agente de usuario: *
No permitir: /*.pdf$
Use cada agente de usuario solo una vez
En Google, no importa si usa el mismo agente de usuario más de una vez. Simplemente compilará todas las reglas de las diversas declaraciones en una sola directiva y la seguirá. Sin embargo, declarar cada agente de usuario solo una vez tiene sentido porque es menos confuso.
Mantener sus directivas ordenadas y simples reduce el riesgo de errores críticos. Por ejemplo, si su archivo robots.txt contenía los siguientes agentes de usuario y directivas.
Agente de usuario: robot de Google
No permitir: /a/
Agente de usuario: robot de Google
No permitir: /b/
Use instrucciones específicas para evitar errores no intencionales
Al establecer directivas, no proporcionar instrucciones específicas puede generar errores que pueden dañar su SEO. Suponga que tiene un sitio multilingüe y está trabajando en una versión en alemán para el subdirectorio /de/.
No desea que los motores de búsqueda puedan acceder a él porque aún no está listo. El siguiente archivo robots.txt evitará que los motores de búsqueda indexen esa subcarpeta y su contenido:
Agente de usuario: *
No permitir: /de
Sin embargo, impedirá que los motores de búsqueda rastreen cualquier página o archivo que comience con /de. En este caso, agregar una barra inclinada al final es la solución simple.
Agente de usuario: *
No permitir: /de/
A Contenidos ↑Ingrese comentarios en el archivo robots.txt con un hash
Los comentarios ayudan a los desarrolladores y posiblemente incluso a usted a comprender su archivo robots.txt. Comience la línea con un hash (#) para incluir un comentario. Los rastreadores ignoran las líneas que comienzan con un hash.
# Esto le indica al bot de Bing que no rastree nuestro sitio.
Agente de usuario: Bingbot
No permitir: /
Use diferentes archivos robots.txt para cada subdominio
Robots.txt solo afecta el rastreo en su dominio de host. Necesitará otro archivo para restringir el rastreo en un subdominio diferente. Por ejemplo, si aloja su sitio web principal en example.com y su blog en blog.example.com, necesitará dos archivos robots.txt. Coloque uno en el directorio raíz del dominio principal, mientras que el otro archivo debe estar en el directorio raíz del blog.
No bloquees buen contenido
No utilice un archivo robots.txt o una etiqueta noindex para bloquear cualquier contenido de calidad que desee hacer público para evitar efectos negativos en los resultados de SEO. Verifique minuciosamente las etiquetas noindex y las reglas de rechazo en sus páginas.
No abuses del retardo de rastreo
Hemos explicado el retraso del rastreo, pero no debe usarlo con frecuencia porque limita que los bots rastreen todas las páginas. Puede funcionar para algunos sitios web, pero puede estar perjudicando su clasificación y tráfico si tiene un sitio web grande.
Preste atención a la distinción entre mayúsculas y minúsculas
El archivo Robots.txt distingue entre mayúsculas y minúsculas, por lo que debe asegurarse de crear un archivo robots en el formato correcto. El archivo de robots debe llamarse 'robots.txt' con todas las letras en minúsculas. De lo contrario, no funcionará.
Otras mejores prácticas:
- Asegúrese de no bloquear el contenido o las secciones de su sitio web para que no se rastreen.
- No use robots.txt para mantener los datos confidenciales (información privada del usuario) fuera de los resultados SERP. Utilice un método diferente, como el cifrado de datos o la metadirectiva noindex , para restringir el acceso si otras páginas enlazan directamente con la página privada.
- Algunos motores de búsqueda tienen más de un agente de usuario. Google, por ejemplo, utiliza Googlebot para búsquedas orgánicas y Googlebot-Image para imágenes. No es necesario especificar directivas para los múltiples rastreadores de cada motor de búsqueda porque la mayoría de los agentes de usuario del mismo motor de búsqueda siguen las mismas reglas.
- Un motor de búsqueda almacena en caché los contenidos de robots.txt pero los actualiza diariamente. Si cambia el archivo y desea actualizarlo más rápido, puede enviar la URL del archivo a Google.
Uso de robots.txt para evitar la indexación de contenido
Deshabilitar una página es la forma más efectiva de evitar que los bots la rastreen directamente. Sin embargo, no funcionará en las siguientes situaciones:
- Si otra fuente tiene enlaces a la página, los bots aún la rastrearán e indexarán.
- Los bots ilegítimos seguirán rastreando e indexando el contenido.
Uso de robots.txt para proteger contenido privado
Algunos contenidos privados, como archivos PDF o páginas de agradecimiento, aún pueden indexarse incluso si bloquea los bots. Colocar todas sus páginas exclusivas detrás de un inicio de sesión es una de las mejores formas de fortalecer la directiva de rechazo. Su contenido permanecerá disponible, pero sus visitantes darán un paso más para acceder a él.
Uso de robots.txt para ocultar contenido duplicado malicioso
El contenido duplicado es idéntico o muy similar a otro contenido en el mismo idioma. Google intenta indexar y mostrar páginas con contenido único. Por ejemplo, si su sitio tiene versiones "normales" y "impresoras" de cada artículo y una etiqueta noindex no bloquea ninguno de los dos, enumerarán uno de ellos.
Ejemplos de archivos robots.txt
Los siguientes son algunos ejemplos de archivos robots.txt. Estos son principalmente para ideas, pero si uno de ellos satisface sus necesidades, cópielo y péguelo en un documento de texto, guárdelo como "robots.txt" y cárguelo en el directorio adecuado.
Acceso total para todos los bots
Hay varias formas de decirle a los motores de búsqueda que accedan a todos los archivos, incluso tener un archivo robots.txt vacío o ninguno.
Agente de usuario: *
Rechazar:
Sin acceso para todos los bots
El siguiente archivo robots.txt indica a todos los motores de búsqueda que eviten acceder a todo el sitio:
Agente de usuario: *
No permitir: /
Bloquear un subdirectorio para todos los bots
Agente de usuario: *
No permitir: /carpeta/
Bloquee un subdirectorio para todos los bots (con un archivo permitido)
Agente de usuario: *
No permitir: /carpeta/
Permitir: /carpeta/pagina.html
Bloquear un archivo para todos los bots
Agente de usuario: *
No permitir: /este-es-un-archivo.pdf
Bloquee un tipo de archivo (PDF) para todos los bots
Agente de usuario: *
No permitir: /*.pdf$
Bloquear todas las URL parametrizadas solo para Googlebot
Agente de usuario: robot de Google
No permitir: /*?
Cómo probar su archivo robots.txt en busca de errores
Los errores en Robots.txt pueden ser graves, por lo que es importante controlarlos. Consulte periódicamente el informe "Cobertura" en Search Console para detectar problemas relacionados con robot.txt. A continuación se enumeran algunos de los errores que puede encontrar, lo que significan y cómo solucionarlos.
URL enviada bloqueada por robots.txt
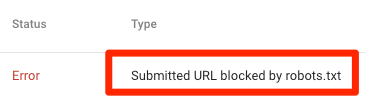
Indica que robots.txt ha bloqueado al menos una de las URL en su(s) mapa(s) del sitio. Si su mapa del sitio es correcto y no incluye páginas canonicalizadas, no indexadas o redirigidas, entonces robots.txt no debería bloquear ninguna página que envíe. Si es así, identifique las páginas afectadas y elimine el bloqueo de su archivo robots.txt.
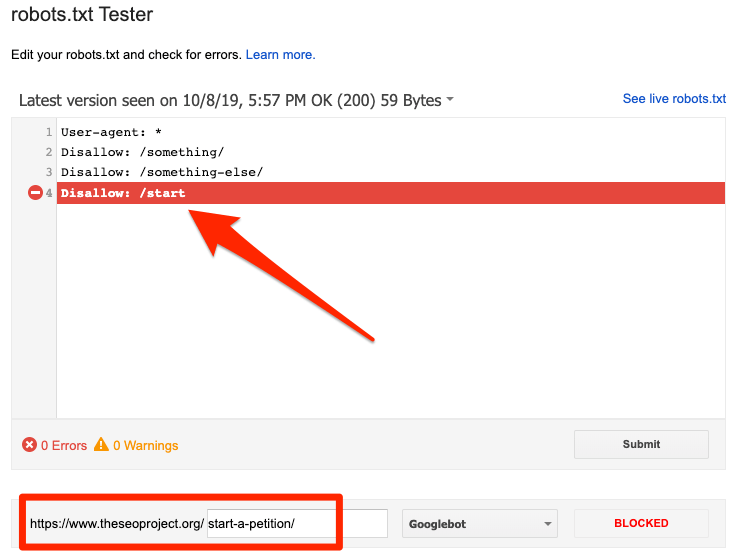
Puede utilizar el probador de robots.txt de Google para identificar la directiva de bloqueo. Tenga cuidado al editar su archivo robots.txt porque un error puede afectar a otras páginas o archivos.
Bloqueado por robots.txt
Este error indica que robots.txt ha bloqueado contenido que Google no puede indexar. Elimine el bloqueo de rastreo en robots.txt si este contenido es crucial y debe indexarse. (Además, verifique que el contenido no esté indexado).
Si desea excluir contenido del índice de Google, use una metaetiqueta de robot o un encabezado x-robots y elimine el bloqueo de rastreo. Esa es la única forma de mantener el contenido fuera del índice de Google.
Indexado, aunque bloqueado por robots.txt
Significa que Google todavía indexa parte del contenido bloqueado por robots.txt. Robots.txt no es la solución para evitar que su contenido se muestre en los resultados de búsqueda de Google.
Para evitar la indexación, elimine el bloque de rastreo y reemplácelo con una etiqueta meta robots o un encabezado HTTP x-robots-tag. Si accidentalmente bloqueó este contenido y desea que Google lo indexe, elimine el bloqueo de rastreo en robots.txt. Puede ayudar a mejorar la visibilidad del contenido en las búsquedas de Google.
Robots.txt vs meta robots vs x-robots
¿Qué diferencia a estos tres comandos de robot? Robots.txt es un archivo de texto simple, mientras que meta y x-robots son meta directivas. Más allá de sus roles fundamentales, los tres tienen funciones distintas. Robots.txt especifica el comportamiento de rastreo para todo el sitio web o directorio, mientras que los robots meta y x definen el comportamiento de indexación para páginas individuales (o elementos de página).
Otras lecturas
Recursos útiles
- Wikipedia: Protocolo de exclusión de robots
- Documentación de Google sobre Robots.txt
- Documentación de Bing (y Yahoo) sobre Robots.txt
- Directivas explicadas
- Documentación de Yandex en Robots.txt
Terminando
Esperamos que haya comprendido completamente la importancia del archivo robot.txt y sus contribuciones a su práctica general de SEO y la rentabilidad del sitio web. Si todavía tiene problemas para obtener ingresos de su sitio web, no necesitará programar para comenzar a ganar con los anuncios de Adsterra. ¡Ponga un código de anuncio en su sitio web HTML, WordPress o Blogger y comience a obtener ganancias hoy mismo!