
Techniques avancées pour améliorer le débit LLM
Publié: 2024-04-02Dans le monde technologique en évolution rapide, les grands modèles linguistiques (LLM) sont devenus des acteurs clés dans la façon dont nous interagissons avec l’information numérique. Ces outils puissants peuvent rédiger des articles, répondre à des questions et même tenir des conversations, mais ils ne sont pas sans défis. À mesure que nous exigeons davantage de ces modèles, nous nous heurtons à des obstacles, notamment lorsqu’il s’agit de les faire fonctionner plus rapidement et plus efficacement. Ce blog vise à s’attaquer de front à ces obstacles.
Nous nous penchons sur des stratégies intelligentes conçues pour augmenter la vitesse de fonctionnement de ces modèles, sans perdre la qualité de leur production. Imaginez essayer d'améliorer la vitesse d'une voiture de course tout en veillant à ce qu'elle puisse toujours naviguer parfaitement dans les virages serrés : c'est ce que nous visons avec les grands modèles linguistiques. Nous examinerons des méthodes telles que le traitement par lots continu, qui permet de traiter les informations plus facilement, et des approches innovantes telles que Paged et Flash Attention, qui rendent les LLM plus attentifs et plus rapides dans leur raisonnement numérique.
Donc, si vous souhaitez repousser les limites de ce que ces géants de l’IA peuvent faire, vous êtes au bon endroit. Explorons ensemble comment ces techniques avancées façonnent l'avenir des LLM, les rendant plus rapides et meilleurs que jamais.
Défis pour atteindre un débit plus élevé pour les LLM
Atteindre un débit plus élevé dans les grands modèles linguistiques (LLM) se heurte à plusieurs défis importants, chacun agissant comme un obstacle à la vitesse et à l'efficacité avec lesquelles ces modèles peuvent fonctionner. L’un des principaux obstacles réside dans les besoins en mémoire nécessaires au traitement et au stockage des grandes quantités de données avec lesquelles ces modèles fonctionnent. À mesure que les LLM gagnent en complexité et en taille, la demande en ressources informatiques s'intensifie, ce qui rend difficile le maintien, et encore moins l'amélioration, des vitesses de traitement.
Un autre défi majeur est la nature auto-régressive des LLM, en particulier dans les modèles utilisés pour générer du texte. Cela signifie que le résultat de chaque étape dépend des précédentes, créant une exigence de traitement séquentiel qui limite intrinsèquement la rapidité avec laquelle les tâches peuvent être exécutées. Cette dépendance séquentielle entraîne souvent un goulot d'étranglement, car chaque étape doit attendre que son prédécesseur soit terminé avant de pouvoir continuer, ce qui entrave les efforts visant à atteindre un débit plus élevé.
De plus, l’équilibre entre précision et vitesse est délicat. Améliorer le débit sans compromettre la qualité du résultat est un exercice sur la corde raide, qui nécessite des solutions innovantes capables de naviguer dans le paysage complexe de l'efficacité informatique et de l'efficacité des modèles.
Ces défis constituent la toile de fond dans laquelle les progrès en matière d'optimisation LLM sont réalisés, repoussant les limites de ce qui est possible dans le domaine du traitement du langage naturel et au-delà.
Mémoire nécessaire
La phase de décodage génère un seul jeton à chaque pas de temps, mais chaque jeton dépend des tenseurs de clé et de valeur de tous les jetons précédents (y compris les tenseurs KV des jetons d'entrée calculés au pré-remplissage et tout nouveau tenseur KV calculé jusqu'au pas de temps actuel) .
Ainsi, afin de minimiser les calculs redondants à chaque fois et d'éviter de recalculer tous ces tenseurs pour tous les tokens à chaque pas de temps, il est possible de les mettre en cache dans la mémoire GPU. À chaque itération, lorsque de nouveaux éléments sont calculés, ils sont simplement ajoutés au cache en cours d'exécution pour être utilisés lors de l'itération suivante. Ceci est essentiellement connu sous le nom de cache KV.
Cela réduit considérablement le calcul nécessaire, mais introduit une exigence de mémoire ainsi que des exigences de mémoire déjà plus élevées pour les grands modèles de langage, ce qui rend difficile l'exécution sur des GPU courants. Avec l'augmentation de la taille des paramètres du modèle (7B à 33B) et la précision plus élevée (fp16 à fp32), les besoins en mémoire augmentent également. Voyons un exemple de la capacité de mémoire requise,
Comme nous le savons, les deux principaux occupants de la mémoire sont
- Les poids du modèle sont en mémoire, cela ne vient pas. de paramètres comme 7B et le type de données de chaque paramètre, par exemple 7B en fp16 (2 octets) ~ = 14 Go en mémoire
- Cache KV : cache utilisé pour la valeur clé de l’étape d’auto-attention afin d’éviter les calculs redondants.
Taille du cache KV par jeton en octets = 2 * (num_layers) * (hidden_size) * précision_in_bytes
Le premier facteur 2 représente les matrices K et V. Ces Hidden_size et dim_head peuvent être obtenus à partir de la carte du modèle ou du fichier de configuration.
La formule ci-dessus est par jeton, donc pour une séquence d'entrée, ce sera seq_len * size_of_kv_per_token. La formule ci-dessus se transformera donc en :
Taille totale du cache KV en octets = (sequence_length) * 2 * (num_layers) * (hidden_size) * précision_in_bytes
Par exemple, avec LAMA 2 en fp16, la taille sera de (4096) * 2 * (32) * (4096) * 2, soit ~ 2 Go.
Ce qui précède concerne une seule entrée, avec plusieurs entrées, cela augmente rapidement, cette allocation et cette gestion de la mémoire en vol deviennent ainsi une étape cruciale pour obtenir des performances optimales, sinon cela entraîne des problèmes de mémoire insuffisante et de fragmentation.
Parfois, les besoins en mémoire sont supérieurs à la capacité de notre GPU, dans ces cas, nous devons examiner le parallélisme des modèles, le parallélisme tensoriel qui n'est pas couvert ici mais vous pouvez explorer dans cette direction.
Fonctionnement auto-régressif et lié à la mémoire
Comme nous pouvons le voir, la partie génération de sortie des grands modèles de langage est de nature auto-régressive. Le indique que pour tout nouveau jeton à générer, cela dépend de tous les jetons précédents et de ses états intermédiaires. Étant donné que dans l'étape de sortie, tous les jetons ne sont pas disponibles pour effectuer des calculs ultérieurs et qu'il n'y a qu'un seul vecteur (pour le jeton suivant) et le bloc de l'étape précédente, cela devient comme une opération matrice-vecteur qui sous-utilise la capacité de calcul du GPU lorsque par rapport à la phase de préremplissage. La vitesse à laquelle les données (poids, clés, valeurs, activations) sont transférées vers le GPU depuis la mémoire domine la latence, et non la vitesse réelle des calculs. En d’autres termes, il s’agit d’une opération liée à la mémoire .
Des solutions innovantes pour surmonter les défis de débit
Dosage continu
L'étape très simple pour réduire la nature liée à la mémoire de l'étape de décodage consiste à regrouper les entrées et à effectuer des calculs pour plusieurs entrées à la fois. Mais un simple traitement par lots constant a entraîné de mauvaises performances en raison de la nature des longueurs de séquence variables générées et ici, la latence d'un lot dépend de la séquence la plus longue générée dans un lot et également des besoins croissants en mémoire puisque plusieurs entrées sont maintenant traité en une seule fois.
Par conséquent, un simple traitement par lots statique est inefficace et vient le traitement par lots continu. Son essence réside dans l'agrégation dynamique des lots de demandes entrantes, en s'adaptant aux taux d'arrivée fluctuants et en exploitant les opportunités de traitement parallèle chaque fois que cela est possible. Cela optimise également l'utilisation de la mémoire en regroupant des séquences de longueurs similaires dans chaque lot, ce qui minimise la quantité de remplissage nécessaire pour les séquences plus courtes et évite de gaspiller des ressources de calcul avec un remplissage excessif.

Il ajuste de manière adaptative la taille du lot en fonction de facteurs tels que la capacité de mémoire actuelle, les ressources de calcul et la longueur des séquences d'entrée. Cela garantit que le modèle fonctionne de manière optimale dans diverses conditions sans dépasser les contraintes de mémoire. Ceci, en aide à l'attention paginée (expliquée ci-dessous), contribue à réduire la latence et à augmenter le débit.
Pour en savoir plus : Comment le traitement par lots continu permet un débit 23x dans l'inférence LLM tout en réduisant la latence p50
Attention paginée
Comme nous effectuons des traitements par lots pour améliorer le débit, cela se fait également au prix d'une augmentation des besoins en mémoire cache KV, puisque nous traitons désormais plusieurs entrées à la fois. Ces séquences peuvent dépasser la capacité mémoire des ressources informatiques disponibles, ce qui rend peu pratique leur traitement dans leur intégralité.
On observe également que l’allocation naïve de mémoire du cache KV entraîne une grande fragmentation de la mémoire, tout comme celle que nous observons dans les systèmes informatiques en raison d’une allocation inégale de la mémoire. vLLM a introduit Paged Attention, une technique de gestion de la mémoire inspirée des concepts du système d'exploitation de pagination et de mémoire virtuelle pour gérer efficacement les besoins croissants du cache KV.
Paged Attention résout les contraintes de mémoire en divisant le mécanisme d'attention en pages ou segments plus petits, chacun couvrant un sous-ensemble de la séquence d'entrée. Plutôt que de calculer simultanément les scores d’attention pour l’ensemble de la séquence d’entrée, le modèle se concentre sur une page à la fois, en la traitant de manière séquentielle.
Pendant l'inférence ou la formation, le modèle parcourt chaque page de la séquence d'entrée, calculant les scores d'attention et générant une sortie en conséquence. Une fois qu'une page est traitée, ses résultats sont stockés et le modèle passe à la page suivante.
En divisant le mécanisme d'attention en pages, Paged Attention permet au modèle de langage Large de gérer des séquences d'entrée de longueur arbitraire sans dépasser les contraintes de mémoire. Il réduit efficacement l'empreinte mémoire requise pour le traitement de longues séquences, ce qui permet de travailler avec des documents et des lots volumineux.
Pour en savoir plus : Service LLM rapide avec vLLM et PagedAttention
Attention éclair
Comme le mécanisme d'attention est crucial pour les modèles de transformateur sur lesquels sont basés les grands modèles de langage, il aide le modèle à se concentrer sur les parties pertinentes du texte d'entrée lors des prédictions. Cependant, à mesure que les modèles basés sur des transformateurs deviennent plus grands et plus complexes, le mécanisme d'auto-attention devient de plus en plus lent et gourmand en mémoire, conduisant à un problème de goulot d'étranglement de mémoire, comme mentionné précédemment. Flash Attention est une autre technique d'optimisation qui vise à atténuer ce problème en optimisant les opérations d'attention, permettant une formation et une inférence plus rapides.
Principales caractéristiques de Flash Attention :
Fusion du noyau : il est important non seulement de maximiser l'utilisation du calcul du GPU, mais également de la rendre aussi efficace que possible. Flash Attention combine plusieurs étapes de calcul en une seule opération, réduisant ainsi le besoin de transferts de données répétitifs. Cette approche rationalisée simplifie le processus de mise en œuvre et améliore l'efficacité des calculs.
Mosaïque : Flash Attention divise les données chargées en blocs plus petits, facilitant ainsi le traitement parallèle. Cette stratégie optimise l'utilisation de la mémoire, permettant des solutions évolutives pour les modèles avec des tailles d'entrée plus grandes.
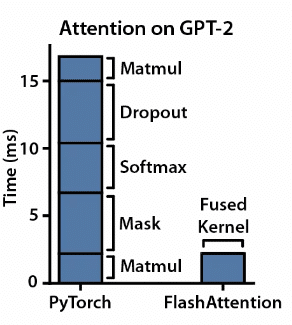
(Noyau CUDA fusionné illustrant comment le carrelage et la fusion réduisent le temps requis pour le calcul, Source de l'image : FlashAttention : Attention exacte rapide et économe en mémoire avec IO-Awareness)
Optimisation de la mémoire : Flash Attention charge les paramètres uniquement pour les derniers jetons, en réutilisant les activations des jetons récemment calculés. Cette approche de fenêtre glissante réduit le nombre de requêtes d'E/S pour charger les poids et maximise le débit de la mémoire flash.
Transferts de données réduits : Flash Attention minimise les transferts de données aller-retour entre les types de mémoire, tels que la mémoire à haute bande passante (HBM) et la SRAM (mémoire statique à accès aléatoire). En chargeant toutes les données (requêtes, clés et valeurs) une seule fois, cela réduit la surcharge liée aux transferts de données répétitifs.
Étude de cas – Optimiser l'inférence avec le décodage spéculatif
Une autre méthode utilisée pour accélérer la génération de texte dans un modèle de langage autorégressif est le décodage spéculatif. L'objectif principal du décodage spéculatif est d'accélérer la génération de texte tout en préservant la qualité du texte généré à un niveau comparable à celui de la distribution cible.
Le décodage spéculatif introduit un petit modèle/projet qui prédit les jetons suivants dans la séquence, qui sont ensuite acceptés/rejetés par le modèle principal sur la base de critères prédéfinis. L'intégration d'un modèle brouillon plus petit avec le modèle cible améliore considérablement la vitesse de génération de texte, cela est dû à la nature des besoins en mémoire. Étant donné que le projet de modèle est petit, il nécessite moins de nombre. des poids de neurones à charger et le nombre de poids. Le temps de calcul est également moindre par rapport au modèle principal, ce qui réduit la latence et accélère le processus de génération de sortie. Le modèle principal évalue ensuite les résultats générés et s'assure qu'ils correspondent à la distribution cible du prochain jeton probable.
Essentiellement, le décodage spéculatif rationalise le processus de génération de texte en exploitant un modèle de brouillon plus petit et plus rapide pour prédire les jetons suivants, accélérant ainsi la vitesse globale de génération de texte tout en maintenant la qualité du contenu généré proche de la distribution cible.
Il est très important que les jetons générés par des modèles plus petits ne soient pas toujours constamment rejetés, ce cas entraîne une diminution des performances au lieu d'une amélioration. Grâce aux expériences et à la nature des cas d'utilisation, nous pouvons sélectionner un modèle plus petit/introduire un décodage spéculatif dans le processus d'inférence.
Conclusion
Le parcours à travers les techniques avancées d'amélioration du débit du Large Language Model (LLM) éclaire la voie à suivre dans le domaine du traitement du langage naturel, présentant non seulement les défis mais aussi les solutions innovantes qui peuvent les relever de front. Ces techniques, du traitement par lots continu à l'attention paginée et flash, en passant par l'approche intrigante du décodage spéculatif, sont plus que de simples améliorations incrémentielles. Ils représentent des avancées significatives dans notre capacité à rendre les grands modèles de langage plus rapides, plus efficaces et, à terme, plus accessibles pour un large éventail d'applications.
L’importance de ces progrès ne peut être surestimée. En optimisant le débit LLM et en améliorant les performances, nous ne nous contentons pas de peaufiner les moteurs de ces modèles puissants ; nous redéfinissons ce qui est possible en termes de vitesse et d'efficacité de traitement. Cela ouvre à son tour de nouveaux horizons pour l’application de modèles linguistiques à grande échelle, depuis les services de traduction linguistique en temps réel pouvant fonctionner à la vitesse de la conversation jusqu’aux outils d’analyse avancés capables de traiter de vastes ensembles de données à une vitesse sans précédent.
De plus, ces techniques soulignent l’importance d’une approche équilibrée de l’optimisation des grands modèles de langage – une approche qui prend soigneusement en compte l’interaction entre la vitesse, la précision et les ressources informatiques. Alors que nous repoussons les limites des capacités LLM, le maintien de cet équilibre sera crucial pour garantir que ces modèles puissent continuer à servir d’outils polyvalents et fiables dans une myriade d’industries.
Les techniques avancées permettant d’améliorer le débit des modèles de langage à grande échelle sont bien plus que de simples réalisations techniques ; ce sont des jalons dans l’évolution continue de l’intelligence artificielle. Ils promettent de rendre les LLM plus adaptables, plus efficaces et plus puissants, ouvrant la voie à de futures innovations qui continueront de transformer notre paysage numérique.
En savoir plus sur l'architecture GPU pour l'optimisation de l'inférence de grands modèles de langage dans notre récent article de blog