
Évaluation des outils de Web Scraping : ce que les entreprises doivent savoir
Publié: 2024-05-15Le web scraping via des outils de web scraping automatisés est essentiel pour les organisations qui cherchent à exploiter le big data. Il permet la récupération automatisée d'informations pertinentes à partir de diverses sources Web, ce qui est essentiel pour l'analyse basée sur les données.
En extrayant les tendances actuelles du marché, les préférences des consommateurs et les informations sur la concurrence, les entreprises peuvent :
- Faire des choix stratégiques éclairés
- Adaptez les produits aux besoins des clients
- Optimiser les prix pour la compétitivité du marché
- Augmenter l’efficacité opérationnelle
De plus, lorsqu’elles sont fusionnées avec des outils d’analyse, les données récupérées sous-tendent les modèles prédictifs, enrichissant les processus de prise de décision. Cette veille concurrentielle pousse les entreprises à anticiper les évolutions du marché et à agir de manière proactive, tout en conservant un avantage critique dans leurs secteurs respectifs.
11 fonctionnalités clés des outils de web scraping automatisés que les entreprises devraient rechercher
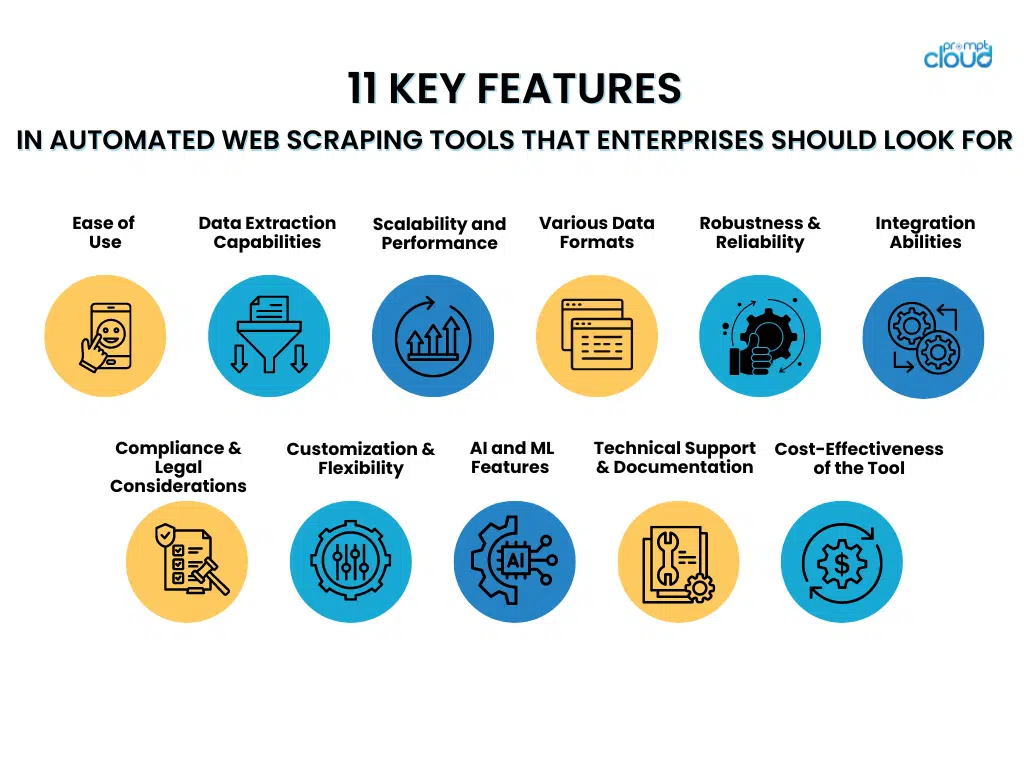
- Facilité d'utilisation
Lorsqu'elles choisissent des outils de scraping Web automatisés, les entreprises doivent privilégier ceux dotés d'interfaces faciles à utiliser et d'étapes de configuration sans effort. Les outils dotés d'interfaces intuitives permettent au personnel de les utiliser efficacement sans formation approfondie, ce qui permet de se concentrer davantage sur la récupération de données plutôt que sur la maîtrise de systèmes complexes.
D'un autre côté, des méthodes de configuration simples facilitent le déploiement rapide de ces outils, minimisant les retards et accélérant le parcours vers des informations précieuses. Les fonctionnalités qui contribuent à la facilité d'utilisation incluent :
- Menus de navigation clairs et simples
- Fonctionnalités glisser-déposer pour la conception de flux de travail
- Modèles prédéfinis pour les tâches de scraping courantes
- Assistants étape par étape guidant la configuration initiale
- Documentation complète et tutoriels pour faciliter l’apprentissage
Un outil convivial maximise l’efficacité des employés et aide à maintenir des niveaux élevés de productivité.
- Capacités d'extraction de données
Source de l'image : Qu'est-ce que l'extraction de données ? Voici ce que vous devez savoir
Lors de l’évaluation des outils automatisés de web scraping, les entreprises doivent donner la priorité aux fonctionnalités avancées d’analyse et de transformation des données telles que :
- Analyse de données personnalisée : possibilité de personnaliser les analyseurs pour interpréter avec précision des structures de données complexes, y compris du contenu imbriqué et dynamique.
- Conversion de type de données : outils qui convertissent automatiquement les données extraites en formats utilisables (par exemple, dates, nombres, chaînes) pour un traitement des données plus efficace.
- Prise en charge des expressions régulières : inclusion de fonctionnalités d'expression régulière pour une correspondance de modèles sophistiquée, permettant une extraction précise des données.
- Transformation conditionnelle : capacité à appliquer une logique conditionnelle aux données extraites, permettant une transformation basée sur des critères ou des modèles de données spécifiques.
- Nettoyage des données : Fonctions qui nettoient et standardisent les données dans la phase post-extraction pour garantir la qualité et la cohérence des données.
- Intégration API : installations pour une intégration transparente avec les API pour traiter et analyser davantage les données extraites, améliorant ainsi les capacités de prise de décision.
Chaque fonctionnalité contribue à un processus d'extraction de données plus robuste et plus précis, essentiel pour les efforts de web scraping au niveau de l'entreprise.
- Évolutivité et performances
Lors de l’évaluation des outils automatisés de web scraping, les entreprises doivent donner la priorité aux attributs d’évolutivité et de performances qui prennent en charge le traitement efficace de vastes ensembles de données.
Un outil idéal peut gérer efficacement une augmentation significative de la charge de travail sans compromettre la vitesse ou la précision. Les entreprises doivent rechercher des fonctionnalités telles que :
- Capacités multithread permettant le traitement simultané des données
- Gestion efficace de la mémoire pour gérer les tâches de scraping à grande échelle
- Allocation dynamique des ressources basée sur les demandes en temps réel
- Infrastructure robuste pouvant évoluer horizontalement ou verticalement
- Mécanismes de mise en cache avancés pour accélérer la récupération des données
La capacité de l'outil à maintenir les performances sous charge garantit une extraction de données fiable, même pendant les heures de pointe ou lors de l'augmentation des opérations.
- Prise en charge de divers formats de données
Source de l'image : Qu'est-ce que le grattage de données ? Définition et comment l'utiliser
Un outil de scraping Web automatisé doit gérer efficacement divers formats de données. Les entreprises travaillent souvent avec différents types de données, et la flexibilité de l'extraction des données est essentielle :
- JSON : format d'échange de données léger, facile à lire et à écrire pour les humains, et facile à analyser et à générer pour les machines.
- CSV : le format de valeurs séparées par des virgules est un format de fichier simple et courant utilisé pour les données tabulaires. La plupart des outils de scraping devraient fournir une option d'exportation CSV.
- XML : Extensible Markup Language, un format plus complexe qui inclut des métadonnées et peut être utilisé dans un large éventail d'industries.
La possibilité d'extraire et d'exporter des données dans ces formats garantit la compatibilité avec différents outils et systèmes d'analyse de données, offrant ainsi une solution polyvalente pour les besoins de l'entreprise.
- Robustesse et fiabilité
Lorsque les entreprises choisissent des outils automatisés de web scraping, elles doivent donner la priorité à la robustesse et à la fiabilité. Les principales caractéristiques à prendre en compte incluent :
- Gestion complète des erreurs : un outil supérieur doit avoir la capacité de détecter et de rectifier automatiquement les erreurs. Il doit enregistrer les problèmes et, si possible, réessayer les demandes ayant échoué sans intervention manuelle.
- Stratégies de minimisation des temps d'arrêt : l'outil doit inclure des mécanismes de basculement, tels que des serveurs de sauvegarde ou des sources de données alternatives, pour maintenir les opérations en cas de panne des sources principales.
- Systèmes de surveillance continue : la surveillance en temps réel garantit que tout temps d'arrêt est immédiatement identifié et résolu, minimisant ainsi les lacunes dans les données.
- Maintenance prédictive : l'utilisation de l'apprentissage automatique pour prédire les points de défaillance potentiels peut prévenir de manière préventive les temps d'arrêt, rendant ainsi le système plus fiable.
Investir dans des outils qui mettent l’accent sur ces aspects de robustesse et de fiabilité peut réduire considérablement les risques opérationnels associés au web scraping.

- Capacités d'intégration
Lors de l’évaluation des outils automatisés de web scraping, les entreprises doivent garantir leur capacité à s’intégrer de manière fluide aux pipelines de données actuels. Ceci est essentiel pour maintenir la continuité des flux de données et optimiser le processus. L'outil doit :
- Proposez des API ou des connecteurs compatibles avec les bases de données et plateformes d'analyse existantes.
- Prend en charge divers formats de données pour une importation/exportation transparente garantissant une perturbation minimale.
- Fournissez des fonctionnalités d'automatisation qui peuvent être déclenchées par des événements au sein du pipeline de données.
- Facilitez une mise à l’échelle facile sans reconfiguration approfondie à mesure que les besoins en données évoluent.
- Considérations de conformité et juridiques
Lors de l’intégration d’un outil automatisé de web scraping dans les opérations de l’entreprise, il est crucial de s’assurer que l’outil respecte les cadres juridiques. Les fonctionnalités à prendre en compte incluent :
- Respect de Robots.txt : l'outil doit automatiquement reconnaître et se conformer au fichier robots.txt du site Web, qui décrit les autorisations de scraping.
- Limitation de débit : Pour éviter une charge perturbatrice sur les serveurs hôtes, les outils doivent inclure une limitation de débit réglable pour contrôler la fréquence des requêtes.
- Conformité à la confidentialité des données : l'outil doit être conçu conformément aux réglementations mondiales en matière de protection des données telles que le RGPD ou le CCPA, garantissant que les données personnelles sont traitées de manière licite.
- Sensibilisation à la propriété intellectuelle : l'outil doit disposer de mécanismes permettant d'éviter la violation des droits d'auteur lors de la suppression de contenu protégé par le droit d'auteur.
- Transparence de l'agent utilisateur : capacité de l'outil de scraping à s'identifier de manière précise et transparente auprès des sites Web cibles, réduisant ainsi le risque de pratiques trompeuses.
L’inclusion de ces fonctionnalités peut contribuer à atténuer les risques juridiques et faciliter une stratégie de scraping responsable qui respecte à la fois le contenu exclusif et la vie privée des utilisateurs.
- Personnalisation et flexibilité
Pour répondre efficacement à leurs besoins uniques en matière de collecte de données, les entreprises doivent considérer les capacités de personnalisation et la flexibilité d'un outil automatisé de web scraping comme des facteurs cruciaux lors de l'évaluation. Un outil supérieur devrait :
- Offrez une interface conviviale aux utilisateurs non techniques pour personnaliser les paramètres d’extraction de données.
- Fournissez des options avancées aux développeurs pour écrire des scripts personnalisés ou utiliser des API.
- Permet une intégration facile avec les systèmes et flux de travail existants au sein de l’entreprise.
- Activez la planification des activités de scraping à exécuter pendant les heures creuses, réduisant ainsi la charge sur les serveurs et évitant une limitation potentielle du site Web.
- Adaptez-vous aux différentes structures de sites Web et types de données, garantissant qu'un large éventail de cas d'utilisation peut être traité.
La personnalisation et la flexibilité garantissent que l'outil peut évoluer avec les besoins changeants de l'entreprise, maximisant ainsi la valeur et l'efficacité des efforts de web scraping.
- Fonctionnalités avancées d'IA et d'apprentissage automatique
Lors de la sélection d’un outil de web scraping automatisé, les entreprises doivent envisager l’intégration de l’IA avancée et de l’apprentissage automatique pour améliorer la précision des données. Ces fonctionnalités incluent :
- Compréhension contextuelle : l'application du traitement du langage naturel (NLP) permet à l'outil de discerner le contexte, réduisant ainsi les erreurs dans le contenu récupéré.
- Reconnaissance de modèles : les algorithmes d'apprentissage automatique identifient les modèles de données, facilitant ainsi l'extraction précise des informations.
- Apprentissage adaptatif : l'outil apprend des tâches de scraping précédentes pour optimiser les processus de collecte de données pour les tâches futures.
- Détection des anomalies : les systèmes d'IA peuvent détecter et corriger les valeurs aberrantes ou les anomalies dans les données récupérées, garantissant ainsi la fiabilité.
- Validation des données : l'utilisation de l'IA pour vérifier de manière croisée les données récupérées avec plusieurs sources améliore la validité des informations.
En exploitant ces capacités, les entreprises peuvent réduire considérablement les inexactitudes dans leurs ensembles de données, conduisant ainsi à une prise de décision plus éclairée.
- Support technique et documentation
Il est conseillé aux entreprises de privilégier les outils de web scraping automatisés, accompagnés d'une assistance technique étendue et d'une documentation complète. Ceci est crucial pour :
- Minimiser les temps d'arrêt : une assistance rapide et professionnelle garantit que tous les problèmes sont résolus rapidement.
- Facilité d'utilisation : Une documentation bien organisée facilite la formation des utilisateurs et la maîtrise des outils.
- Dépannage : des guides et des ressources accessibles permettent aux utilisateurs de résoudre les problèmes courants de manière indépendante.
- Mises à jour et mises à niveau : une assistance cohérente et une documentation claire sont essentielles pour naviguer efficacement dans les mises à jour du système et les nouvelles fonctionnalités.
Choisir un outil doté d’un support technique robuste et d’une documentation claire est essentiel pour un fonctionnement fluide et une résolution efficace des problèmes.
- Évaluation de la rentabilité de l'outil
Les entreprises doivent prendre en compte à la fois les dépenses initiales et le retour sur investissement possible lors de l'évaluation d'un logiciel d'automatisation pour le web scraping. Les principaux facteurs de tarification comprennent :
- Frais de licence ou frais d’abonnement
- Frais de maintenance et de support
- Économies potentielles grâce à l’automatisation
- Évolutivité et adaptabilité aux besoins futurs
Une évaluation approfondie du retour sur investissement (ROI) d'un outil doit prendre en compte son potentiel à réduire le travail manuel, à améliorer la précision des données et à accélérer le processus d'obtention d'informations. De plus, les entreprises doivent évaluer les avantages durables tels que l’amélioration de la compétitivité résultant de choix basés sur les données. La comparaison de ces mesures avec les dépenses de l'outil offrira une vision distincte de sa rentabilité.
Conclusion
Lorsqu'elles choisissent un outil de web scraping automatisé, les entreprises doivent examiner méticuleusement chaque fonctionnalité par rapport à leurs besoins spécifiques. Il est essentiel de mettre l’accent sur des aspects tels que l’évolutivité, la précision des données, la rapidité, la légalité et la rentabilité. L'outil idéal soutiendra les objectifs de l'entreprise et s'intégrera en douceur aux systèmes actuels. Au final, un choix éclairé découle d’un examen approfondi des fonctionnalités de l’outil et d’une solide compréhension des futurs besoins en données de l’entreprise.