
Meilleures pratiques et cas d'utilisation pour récupérer les données d'un site Web
Publié: 2023-12-28Lors de la récupération de données d’un site Web, il est essentiel de respecter les réglementations et le cadre du site cible. Le respect des meilleures pratiques n’est pas seulement une question d’éthique, mais permet également d’éviter les complications juridiques et de garantir la fiabilité de l’extraction des données. Voici les principales considérations :
- Adhérez au fichier robots.txt : vérifiez toujours ce fichier en premier pour comprendre ce que le propriétaire du site a défini comme limites de grattage.
- Utiliser les API : si disponible, utilisez l'API officielle du site, qui est une méthode plus stable et approuvée pour accéder aux données.
- Soyez attentif aux taux de requêtes : une récupération excessive des données peut surcharger les serveurs de sites Web, alors rythmez vos requêtes de manière réfléchie.
- Identifiez-vous : grâce à la chaîne de votre agent utilisateur, soyez transparent sur votre identité et votre objectif lors du scraping.
- Gérez les données de manière responsable : stockez et utilisez les données récupérées conformément aux lois sur la confidentialité et aux réglementations sur la protection des données.
Le respect de ces pratiques garantit un scraping éthique, le maintien de l’intégrité et de la disponibilité du contenu en ligne.
Comprendre le cadre juridique
Lors de la récupération de données sur un site Web, il est crucial de naviguer dans les restrictions juridiques entrelacées. Les principaux textes législatifs comprennent :
- The Computer Fraud and Abuse Act (CFAA) : Législation aux États-Unis rend illégal l’accès à un ordinateur sans autorisation appropriée.
- Le Règlement général sur la protection des données (RGPD) de l'Union européenne : exige le consentement pour l'utilisation des données personnelles et accorde aux individus le contrôle de leurs données.
- Le Digital Millennium Copyright Act (DMCA) : protège contre la distribution de contenu protégé par le droit d'auteur sans autorisation.
Les scrapers doivent également respecter les « conditions d’utilisation » des sites Web, qui limitent souvent l’extraction de données. Garantir le respect de ces lois et politiques est essentiel pour supprimer les données des sites Web de manière éthique et légale.
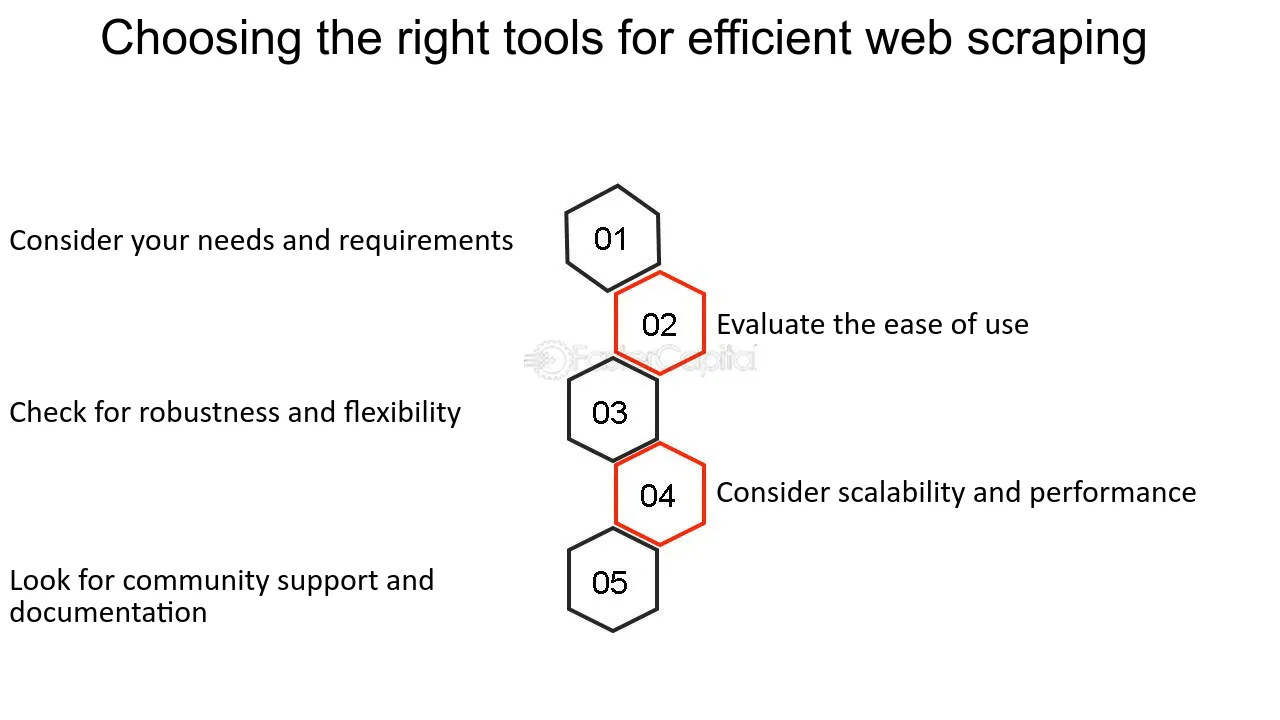
Choisir les bons outils pour le grattage
Choisir les bons outils est crucial lors du lancement d’un projet de web scraping. Les facteurs à considérer comprennent :
- Complexité du site Web : Les sites dynamiques peuvent nécessiter des outils comme Selenium pouvant interagir avec JavaScript.
- Quantité de données : pour le scraping à grande échelle, des outils dotés de capacités de scraping distribuées comme Scrapy sont conseillés.
- Légalité et éthique : sélectionnez des outils dotés de fonctionnalités permettant de respecter le fichier robots.txt et de définir les chaînes de l'agent utilisateur.
- Facilité d'utilisation : les novices pourraient préférer les interfaces conviviales trouvées dans des logiciels comme Octoparse.
- Connaissances en programmation : les non-codeurs pourraient se tourner vers des logiciels avec une interface graphique, tandis que les programmeurs pourraient opter pour des bibliothèques comme BeautifulSoup.
Source de l'image : https://fastercapital.com/
Meilleures pratiques pour récupérer efficacement les données d'un site Web
Pour récupérer les données d'un site Web de manière efficace et responsable, suivez ces directives :
- Respectez les fichiers robots.txt et les conditions du site Web pour éviter les problèmes juridiques.
- Utilisez des en-têtes et faites pivoter les agents utilisateurs pour imiter le comportement humain.
- Implémentez un délai entre les requêtes pour réduire la charge du serveur.
- Utilisez des proxys pour empêcher les interdictions IP.
- Grattez pendant les heures creuses pour minimiser les perturbations du site Web.
- Stockez toujours les données de manière efficace, en évitant les entrées en double.
- Garantissez l’exactitude des données récupérées grâce à des contrôles réguliers.
- Soyez conscient des lois sur la confidentialité des données lors du stockage et de l’utilisation des données.
- Gardez vos outils de scraping à jour pour gérer les modifications du site Web.
- Soyez toujours prêt à adapter les stratégies de scraping si les sites Web mettent à jour leur structure.
Cas d'utilisation du grattage de données dans tous les secteurs
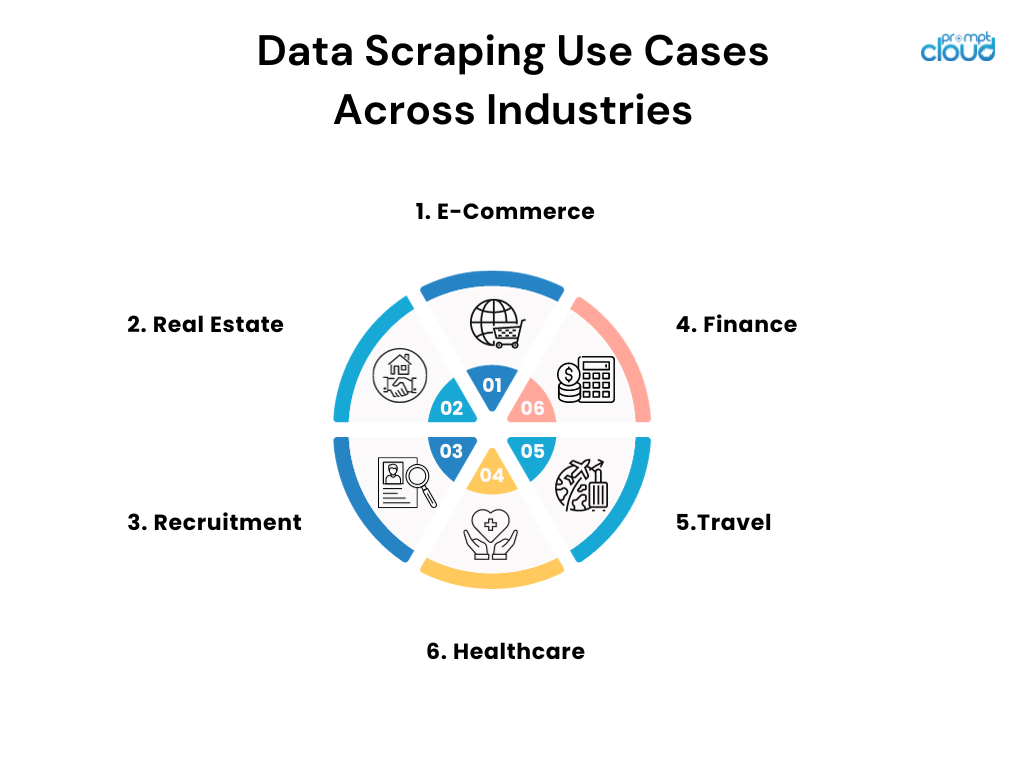
- Commerce électronique : les détaillants en ligne déploient le scraping pour surveiller les prix des concurrents et ajuster leurs stratégies de tarification en conséquence.
- Immobilier : les agents et les entreprises récupèrent les listes pour regrouper les informations sur les propriétés, les tendances et les données sur les prix provenant de diverses sources.
- Recrutement : les entreprises parcourent les sites d'emploi et les réseaux sociaux pour trouver des candidats potentiels et analyser les tendances du marché du travail.
- Finance : les analystes fouillent les archives publiques et les documents financiers pour éclairer les stratégies d'investissement et suivre les sentiments du marché.
- Voyages : les agences réduisent les prix des compagnies aériennes et des hôtels pour offrir aux clients les meilleures offres et forfaits possibles.
- Santé : les chercheurs fouillent les bases de données et les revues médicales pour se tenir au courant des dernières découvertes et essais cliniques.
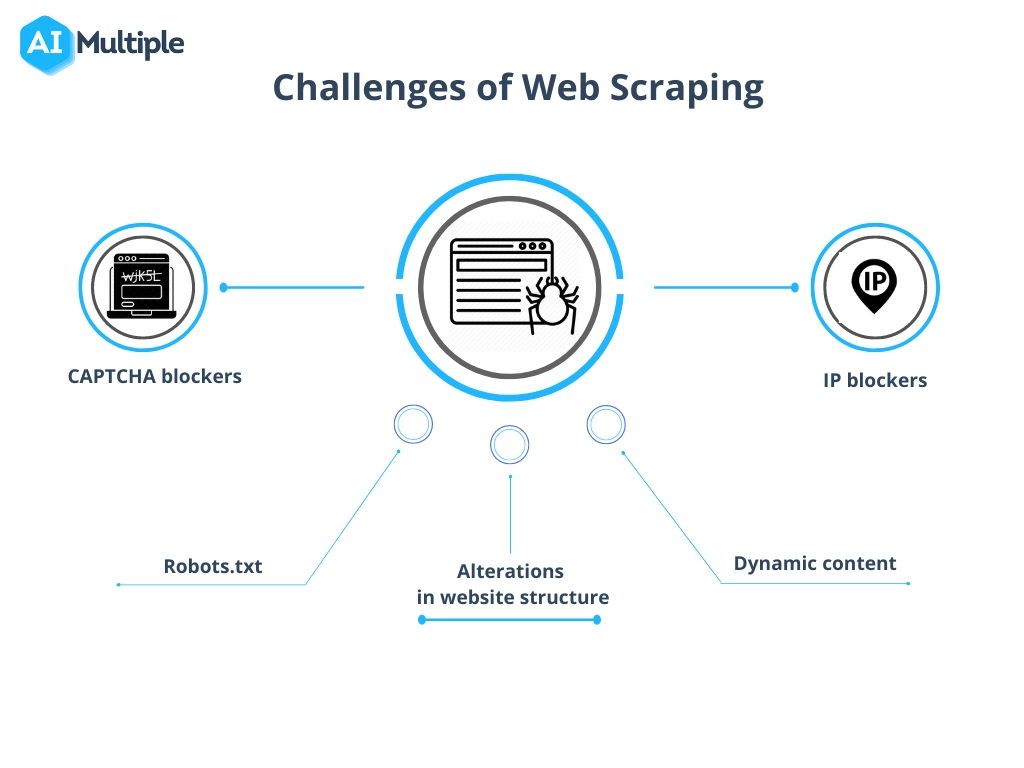
Relever les défis courants liés au grattage de données
Le processus de récupération des données d'un site Web, bien que extrêmement précieux, implique souvent de surmonter des obstacles tels que des modifications de la structure du site Web, des mesures anti-grattage et des préoccupations concernant la qualité des données.

Source de l'image : https://research.aimultiple.com/
Pour les parcourir efficacement :
- Restez adaptatif : mettez régulièrement à jour les scripts de scraping pour correspondre aux mises à jour du site Web. L’utilisation de l’apprentissage automatique peut aider à s’adapter de manière dynamique aux changements structurels.
- Respecter les limites légales : Comprendre et respecter les légalités du scraping pour éviter les litiges. Assurez-vous de consulter le fichier robots.txt et les conditions d'utilisation sur un site Web.
- Haut du formulaire
- Mimic Human Interaction : les sites Web peuvent bloquer les scrapers qui envoient des requêtes trop rapidement. Implémentez des délais et des intervalles aléatoires entre les requêtes pour paraître moins robotiques.
- Gérer les CAPTCHA : des outils et des services sont disponibles pour résoudre ou contourner les CAPTCHA, bien que leur utilisation doive être considérée au regard des implications éthiques et juridiques.
- Maintenir l'intégrité des données : garantir l'exactitude des données extraites. Validez régulièrement les données et nettoyez-les pour maintenir leur qualité et leur utilité.
Ces stratégies aident à surmonter les obstacles courants au scraping et facilitent l’extraction de données précieuses.
Conclusion
L'extraction efficace de données à partir de sites Web est une méthode précieuse avec diverses applications, allant des études de marché à l'analyse concurrentielle. Il est essentiel d'adhérer aux meilleures pratiques, de garantir la légalité, de respecter les directives robots.txt et de contrôler soigneusement la fréquence de scraping pour éviter la surcharge du serveur.
L’application responsable de ces méthodes ouvre la porte à de riches sources de données qui peuvent fournir des informations exploitables et favoriser une prise de décision éclairée pour les entreprises et les particuliers. Une mise en œuvre appropriée, associée à des considérations éthiques, garantit que le grattage de données reste un outil puissant dans le paysage numérique.
Prêt à dynamiser vos connaissances en récupérant les données d'un site Web ? Cherchez pas plus loin! PromptCloud propose des services de web scraping éthiques et fiables adaptés à vos besoins. Connectez-vous à nous à sales@promptcloud.com pour transformer les données brutes en informations exploitables. Améliorons ensemble votre prise de décision !
Questions fréquemment posées
Est-il acceptable de récupérer des données sur des sites Web ?
Absolument, le grattage de données est acceptable, mais vous devez respecter les règles. Avant de vous lancer dans des aventures de scraping, jetez un œil attentif aux conditions d’utilisation et au fichier robots.txt du site Web en question. Faire preuve d'un certain respect pour la présentation du site Web, respecter les limites de fréquence et respecter l'éthique sont autant d'éléments essentiels à des pratiques responsables de collecte de données.
Comment puis-je extraire les données utilisateur d'un site Web via le scraping ?
L’extraction des données utilisateur via le scraping nécessite une approche méticuleuse conforme aux normes juridiques et éthiques. Dans la mesure du possible, il est recommandé d'exploiter les API accessibles au public fournies par le site Web pour la récupération des données. En l'absence d'API, il est impératif de s'assurer que les méthodes de scraping utilisées respectent les lois sur la confidentialité, les conditions d'utilisation et les politiques énoncées par le site Web afin d'atténuer les ramifications juridiques potentielles.
La récupération des données d’un site Web est-elle considérée comme illégale ?
La légalité du web scraping dépend de plusieurs facteurs, notamment l'objectif, la méthodologie et le respect des lois pertinentes. Bien que le web scraping lui-même ne soit pas intrinsèquement illégal, un accès non autorisé, une violation des conditions de service d'un site Web ou un non-respect des lois sur la confidentialité peuvent entraîner des conséquences juridiques. Une conduite responsable et éthique dans les activités de web scraping est primordiale, impliquant une conscience aiguë des limites juridiques et des considérations éthiques.
Les sites Web peuvent-ils détecter les cas de web scraping ?
Les sites Web ont mis en œuvre des mécanismes pour détecter et empêcher les activités de web scraping, en surveillant des éléments tels que les chaînes d'agent utilisateur, les adresses IP et les modèles de requêtes. Pour atténuer la détection, les meilleures pratiques incluent l'emploi de techniques telles que la rotation des agents utilisateurs, l'utilisation de proxys et la mise en œuvre de délais aléatoires entre les requêtes. Cependant, il est essentiel de noter que les tentatives visant à contourner les mesures de détection peuvent enfreindre les conditions de service d'un site Web et potentiellement entraîner des conséquences juridiques. Les pratiques responsables et éthiques de web scraping donnent la priorité à la transparence et au respect des normes juridiques et éthiques.