
Techniques d'exploration Web efficaces pour les applications Big Data
Publié: 2024-06-06À l’ère du Big Data, l’exploration de sites Web est devenue un processus indispensable pour les entreprises souhaitant exploiter la vaste richesse d’informations disponibles en ligne. En collectant, traitant et analysant efficacement les données Web à grande échelle, les entreprises peuvent obtenir des informations précieuses et acquérir un avantage concurrentiel dans divers secteurs.
Les données Web recèlent un immense potentiel, offrant des informations approfondies sur les tendances du marché, le comportement des consommateurs et le paysage concurrentiel. La capacité de collecter et d’analyser efficacement ces données peut transformer les informations brutes en informations exploitables, favorisant ainsi la prise de décision stratégique et la croissance de l’entreprise.
Source : scrapehero
Cependant, la transition du web scraping à petite échelle vers l’exploration du web à grande échelle présente des défis techniques importants. Une mise à l’échelle efficace nécessite un examen attentif de divers facteurs, notamment l’infrastructure, la gestion des données et l’efficacité du traitement. Cet article examine les techniques et stratégies avancées nécessaires pour surmonter ces défis, garantissant ainsi que vos opérations d'exploration Web peuvent se développer pour répondre aux demandes des applications Big Data.
Défis de l'exploration de sites Web pour les applications Big Data
L'exploration de sites Web à la recherche d'applications Big Data présente plusieurs défis importants que les entreprises doivent relever pour exploiter efficacement la puissance des vastes informations en ligne. Comprendre et surmonter ces défis est crucial pour créer une infrastructure d'exploration Web robuste et évolutive.
L’un des principaux défis réside dans le volume et la variété des données présentes sur le Web, qui continuent de croître de façon exponentielle. De plus, la diversité des types de données, du texte et des images aux vidéos et contenus dynamiques, ajoute de la complexité au processus d'exploration des sites Web. Les sites Web modernes utilisent souvent du contenu dynamique généré par JavaScript et AJAX, ce qui rend difficile la tâche.
les robots d'exploration traditionnels pour capturer toutes les informations pertinentes. De plus, les sites Web peuvent imposer des limites de débit ou bloquer les adresses IP pour empêcher une exploration excessive, ce qui peut perturber les efforts de collecte de données.
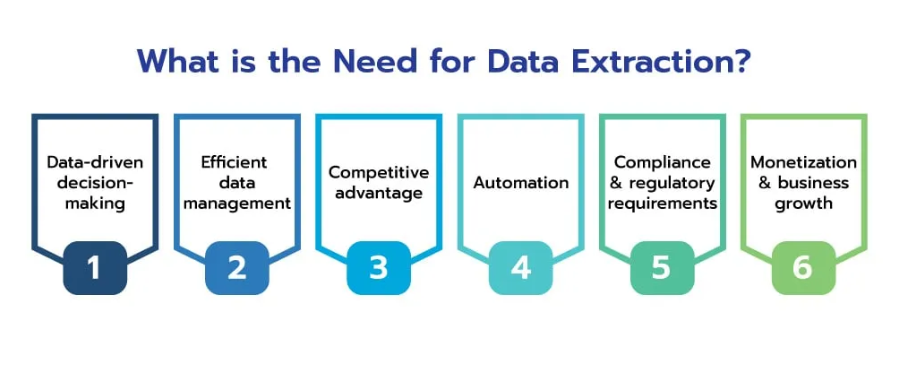
Garantir l'exactitude et la cohérence des données collectées à partir de diverses sources peut être difficile, en particulier lorsqu'il s'agit de grands ensembles de données. Faire évoluer les opérations d’exploration du Web pour gérer des charges de données croissantes sans compromettre les performances constitue un défi technique majeur. De plus, le respect des directives juridiques et éthiques concernant l’exploration de sites Web est crucial pour éviter d’éventuels problèmes juridiques et maintenir une bonne réputation. La gestion efficace des ressources informatiques pour équilibrer vitesse d’exploration et rentabilité est également essentielle.
Techniques pour une extraction efficace des données
La mise en œuvre de techniques avancées d’extraction de données garantit que les données collectées sont pertinentes, précises et prêtes à être analysées. Voici quelques techniques clés pour améliorer l’efficacité de l’extraction de données :
- Traitement parallèle : utilisez le traitement parallèle pour répartir les tâches d'extraction de données sur plusieurs threads ou machines, augmentant ainsi la vitesse d'extraction des données en traitant plusieurs requêtes simultanément et réduisant le temps global requis pour collecter les données.
- Analyse incrémentielle : implémentez une analyse incrémentielle pour mettre à jour uniquement les parties de l'ensemble de données qui ont changé depuis la dernière analyse, réduisant ainsi la quantité de données traitées et la charge sur les serveurs Web, rendant le processus d'analyse plus efficace et moins gourmand en ressources.
- Navigateurs sans tête : utilisez des navigateurs sans tête comme Puppeteer ou Selenium pour restituer et interagir avec du contenu Web dynamique, permettant une extraction précise des données de sites Web qui s'appuient fortement sur JavaScript et AJAX, garantissant ainsi une collecte complète de données.
- Hiérarchisation du contenu : hiérarchisez le contenu en fonction de sa pertinence et de son importance, en vous concentrant d'abord sur les données de grande valeur, en veillant à ce que les données les plus critiques soient collectées rapidement et en optimisant l'utilisation des ressources et la pertinence des données.
- Politiques de planification d'URL et de politesse : mettez en œuvre des politiques intelligentes de planification d'URL et de politesse pour gérer la fréquence des requêtes vers un seul serveur, évitant ainsi la surcharge des serveurs Web et réduisant le risque de blocage IP, garantissant un accès durable aux sources de données.
- Déduplication des données : utilisez des techniques de déduplication des données pour éliminer les entrées en double pendant le processus d'extraction, améliorant ainsi la qualité des données et réduisant les besoins de stockage en garantissant que seules les données uniques sont stockées et traitées.
Solutions d'exploration Web en temps réel
Source : Moyen

Dans le paysage numérique actuel, en évolution rapide, la capacité d'extraire et de traiter des données en temps réel est
crucial pour les entreprises qui cherchent à conserver un avantage concurrentiel. Les solutions d'exploration Web en temps réel permettent une collecte de données continue et instantanée, permettant une analyse et une action immédiate. La mise en œuvre d'une architecture basée sur les événements peut améliorer considérablement les capacités en temps réel, dans lesquelles les robots d'exploration sont déclenchés par des événements ou des modifications spécifiques sur le Web, garantissant ainsi que les données sont collectées dès qu'elles deviennent disponibles.
Évolutivité dans l'exploration Web multilingue
La nature mondiale d'Internet nécessite la capacité d'explorer et de traiter des données dans plusieurs langues, ce qui présente des défis uniques qui nécessitent des solutions spécialisées. Les opérations d'exploration de sites Web pour gérer le contenu multilingue impliquent la mise en œuvre d'algorithmes de détection de langue pour identifier automatiquement la langue des pages Web et garantir que les techniques de traitement spécifiques à la langue sont appliquées. L'utilisation de bibliothèques d'analyse et de frameworks prenant en charge plusieurs langages, tels que BeautifulSoup, fournit des outils robustes pour extraire le contenu de diverses pages Web. L'intégration de services de traduction évolutifs tels que Google Cloud Translation dans le pipeline de traitement des données permet une traduction du contenu en temps réel, permettant une analyse transparente dans différentes langues.
Conclusion
Source : groupebwt
À mesure que nous avançons dans l’ère numérique, l’importance de l’exploration de sites Web pour les applications Big Data continue de croître. L'avenir de l'exploration du Web réside dans sa capacité à évoluer efficacement, à s'adapter aux environnements Web dynamiques et à fournir des informations en temps réel. Les progrès de l’intelligence artificielle et de l’apprentissage automatique joueront un rôle central dans l’amélioration des capacités des robots d’exploration Web, les rendant plus intelligents et plus efficaces dans le traitement de grandes quantités de données.
L'intégration de systèmes distribués et d'infrastructures basées sur le cloud améliorera encore l'évolutivité, permettant aux entreprises de gérer facilement des ensembles de données de plus en plus volumineux. À mesure que les technologies d’exploration du Web continuent d’évoluer, elles amélioreront non seulement les processus de collecte de données, mais permettront également aux entreprises de conserver un avantage concurrentiel dans un paysage numérique en constante évolution.
Adopter ces avancées n’est pas seulement une option mais une nécessité pour les organisations qui souhaitent exploiter efficacement le Big Data. L’avenir de l’exploration du Web promet d’être une force de transformation, stimulant l’innovation et fournissant les outils nécessaires pour libérer tout le potentiel du vaste écosystème de données Web.
Faites passer vos applications Big Data au niveau supérieur avec les services de web scraping personnalisables de PromptCloud avec une intégration et une évolutivité transparentes. Contactez-nous dès aujourd'hui pour exploiter la puissance de l'exploration Web avancée pour votre entreprise.