
Extraction de données à partir de sites Web dynamiques : défis et solutions
Publié: 2023-11-23Internet héberge un réservoir de données étendu et en constante expansion, offrant une valeur considérable aux entreprises, aux chercheurs et aux particuliers à la recherche d'informations, de prises de décisions éclairées ou de solutions innovantes. Cependant, une partie substantielle de ces informations inestimables réside sur des sites Web dynamiques.
Contrairement aux sites Web statiques conventionnels, les sites Web dynamiques génèrent dynamiquement du contenu en réponse aux interactions des utilisateurs ou à des événements externes. Ces sites exploitent des technologies telles que JavaScript pour manipuler le contenu des pages Web, ce qui pose un formidable défi aux techniques traditionnelles de web scraping pour extraire efficacement les données.
Dans cet article, nous approfondirons le domaine du scraping dynamique de pages Web. Nous examinerons les défis typiques liés à ce processus et présenterons des stratégies efficaces et les meilleures pratiques pour surmonter ces obstacles.
Comprendre les sites Web dynamiques
Avant d’aborder les subtilités du scraping dynamique de pages Web, il est essentiel de bien comprendre ce qui caractérise un site Web dynamique. Contrairement à leurs homologues statiques qui fournissent un contenu uniforme universellement, les sites Web dynamiques génèrent dynamiquement du contenu en fonction de divers paramètres tels que les préférences de l'utilisateur, les requêtes de recherche ou les données en temps réel.
Les sites Web dynamiques exploitent souvent des frameworks JavaScript sophistiqués pour modifier et mettre à jour dynamiquement le contenu de la page Web côté client. Bien que cette approche améliore considérablement l'interactivité des utilisateurs, elle présente des défis lors de la tentative d'extraction de données par programmation.
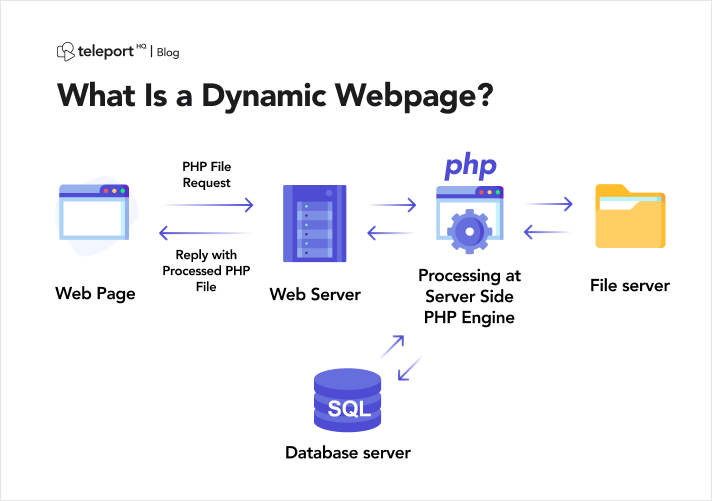
Source de l'image : https://teleporthq.io/
Défis courants liés au scraping dynamique de pages Web
Le scraping dynamique de pages Web pose plusieurs défis en raison de la nature dynamique du contenu. Certains des défis les plus courants comprennent :
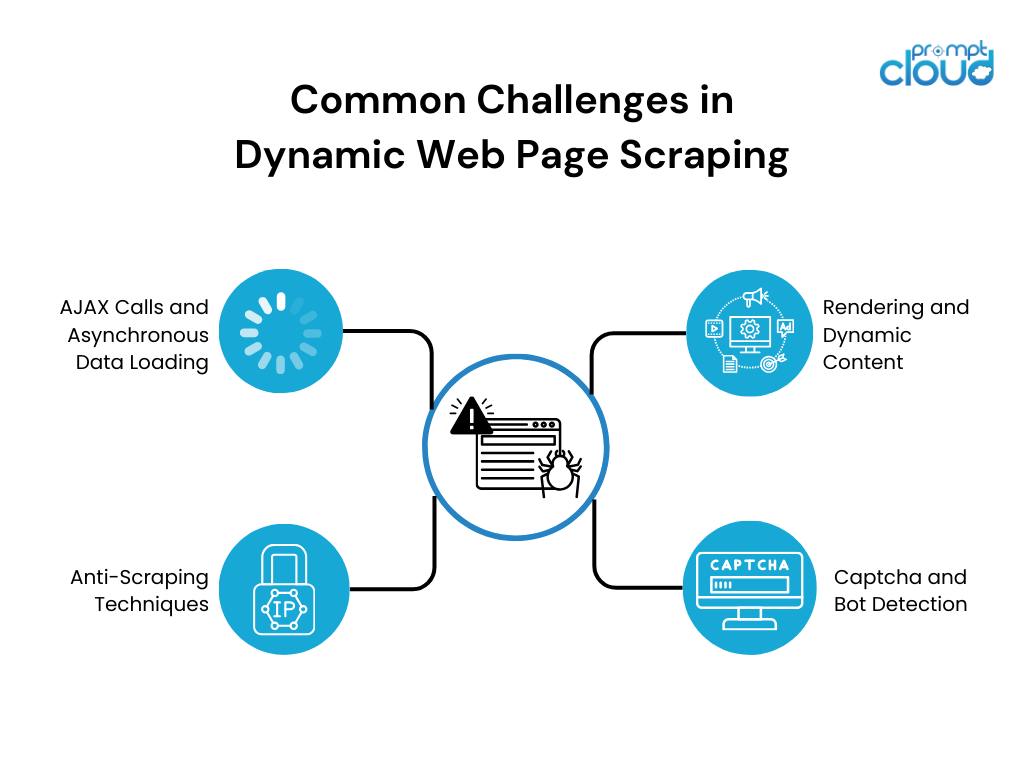
- Rendu et contenu dynamique : les sites Web dynamiques s'appuient fortement sur JavaScript pour restituer le contenu de manière dynamique. Les outils de web scraping traditionnels ont du mal à interagir avec le contenu JavaScript, ce qui entraîne une extraction de données incomplète ou incorrecte.
- Appels AJAX et chargement de données asynchrones : de nombreux sites Web dynamiques utilisent des appels JavaScript et XML asynchrones (AJAX) pour récupérer des données à partir de serveurs Web sans recharger la page entière. Ce chargement de données asynchrone peut rendre difficile la récupération de l'ensemble de données complet, car il peut être chargé progressivement ou déclenché par les interactions de l'utilisateur.
- Captcha et détection de robots : pour empêcher le grattage et protéger les données, les sites Web utilisent diverses contre-mesures telles que des captchas et des mécanismes de détection de robots. Ces mesures de sécurité entravent les efforts de scraping et nécessitent des stratégies supplémentaires pour les surmonter.
- Techniques anti-scraping : les sites Web utilisent diverses techniques anti-scraping telles que le blocage IP, la limitation du débit ou les structures HTML obscurcies pour dissuader les scrapers. Ces techniques nécessitent des stratégies de scraping adaptatives pour échapper à la détection et récupérer avec succès les données souhaitées.
Stratégies pour un scraping dynamique réussi de pages Web
Malgré les défis, il existe plusieurs stratégies et techniques qui peuvent être utilisées pour surmonter les obstacles rencontrés lors du scraping de pages Web dynamiques. Ces stratégies comprennent :
- Utilisation de navigateurs sans tête : les navigateurs sans tête comme Puppeteer ou Selenium permettent l'exécution de JavaScript et le rendu de contenu dynamique, permettant l'extraction précise de données de sites Web dynamiques.
- Inspection du trafic réseau : l'analyse du trafic réseau peut fournir des informations sur le flux de données au sein d'un site Web dynamique. Ces connaissances peuvent être utilisées pour identifier les appels AJAX, intercepter les réponses et extraire les données requises.
- Analyse du contenu dynamique : l'analyse du DOM HTML une fois le contenu dynamique rendu par JavaScript peut aider à extraire les données souhaitées. Des outils comme Beautiful Soup ou Cheerio peuvent être utilisés pour analyser et extraire des données du DOM mis à jour.
- Rotation IP et proxys : la rotation des adresses IP et l'utilisation de proxys peuvent aider à surmonter les problèmes de blocage IP et de limitation de débit. Il permet un scraping distribué et empêche les sites Web d'identifier le scraper comme une source unique.
- Gérer les captchas et les techniques anti-scraping : face aux captchas, le recours à des services de résolution de captcha ou la mise en œuvre d'une émulation humaine peuvent aider à contourner ces mesures. De plus, les structures HTML obscurcies peuvent faire l'objet d'une ingénierie inverse à l'aide de techniques telles que la traversée du DOM ou la reconnaissance de formes.
Meilleures pratiques pour le scraping dynamique du Web
Lors du scraping de pages Web dynamiques, il est important de suivre certaines bonnes pratiques pour garantir un processus de scraping réussi et éthique. Certaines bonnes pratiques incluent :

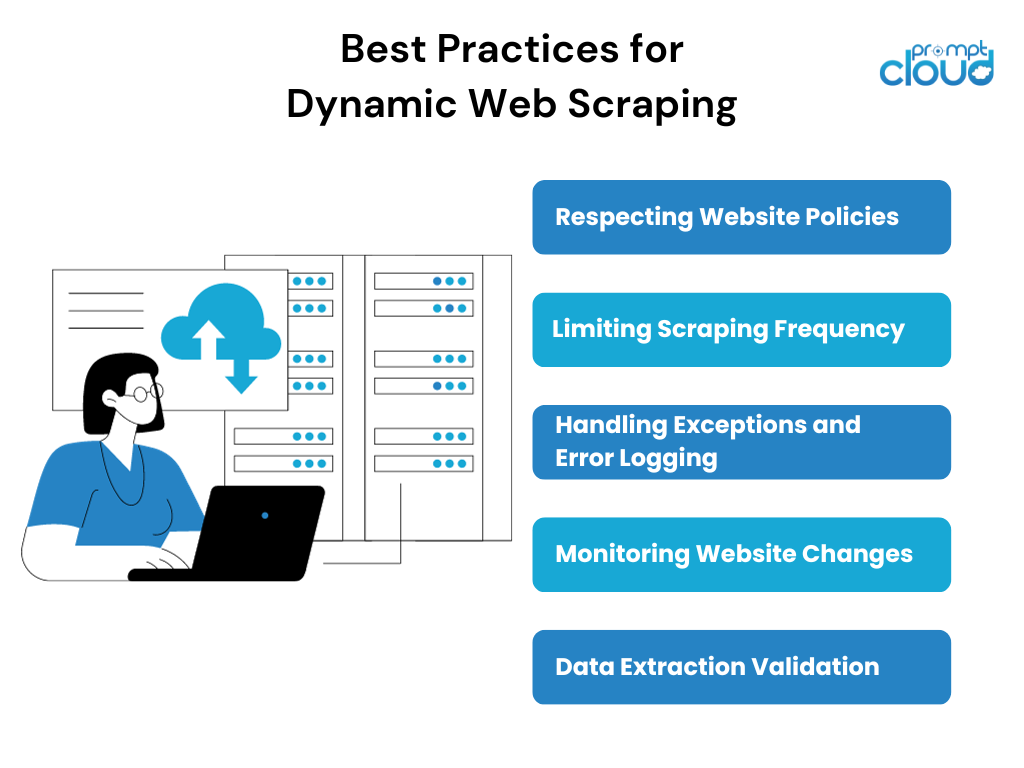
- Respect des politiques du site Web : avant de supprimer un site Web, il est essentiel d'examiner et de respecter les conditions d'utilisation du site Web, le fichier robots.txt et toutes les directives de grattage spécifiques mentionnées.
- Limitation de la fréquence de scraping : un scraping excessif peut mettre à rude épreuve à la fois les ressources du scraper et le site Web scrapé. La mise en œuvre de limites de fréquence de scraping raisonnables et le respect des limites de taux fixées par le site Web peuvent aider à maintenir un processus de scraping harmonieux.
- Gestion des exceptions et journalisation des erreurs : le web scraping dynamique implique de gérer des scénarios imprévisibles tels que des erreurs réseau, des demandes captcha ou des modifications dans la structure du site Web. La mise en œuvre de mécanismes appropriés de gestion des exceptions et de journalisation des erreurs aidera à identifier et à résoudre ces problèmes.
- Surveillance des modifications du site Web : les sites Web dynamiques subissent fréquemment des mises à jour ou des refontes, ce qui peut briser les scripts de scraping existants. Une surveillance régulière du site Web cible pour détecter tout changement et un ajustement rapide de la stratégie de scraping peuvent garantir une extraction ininterrompue des données.
- Validation de l'extraction des données : la validation et le croisement des données extraites avec l'interface utilisateur du site Web peuvent aider à garantir l'exactitude et l'exhaustivité des informations récupérées. Cette étape de validation est particulièrement cruciale lors du scraping de pages Web dynamiques au contenu évolutif.
Conclusion
La puissance du scraping dynamique de pages Web ouvre un monde d'opportunités pour accéder à des données précieuses cachées dans des sites Web dynamiques. Relever les défis associés au scraping de sites Web dynamiques nécessite une combinaison d'expertise technique et le respect de pratiques éthiques de scraping.
En comprenant les subtilités du scraping dynamique de pages Web et en mettant en œuvre les stratégies et les meilleures pratiques décrites dans cet article, les entreprises et les particuliers peuvent libérer tout le potentiel des données Web et acquérir un avantage concurrentiel dans divers domaines.
Un autre défi rencontré dans le scraping dynamique de pages Web est le volume de données qui doivent être extraites. Les pages Web dynamiques contiennent souvent une grande quantité d’informations, ce qui rend difficile l’extraction et l’extraction efficace des données pertinentes.
Pour surmonter cet obstacle, les entreprises peuvent tirer parti de l’expertise des fournisseurs de services de web scraping. La puissante infrastructure de scraping et les techniques avancées d'extraction de données de PromptCloud permettent aux entreprises de gérer facilement des projets de scraping à grande échelle.
Avec l'aide de PromptCloud, les organisations peuvent extraire des informations précieuses à partir de pages Web dynamiques et les transformer en informations exploitables. Découvrez la puissance du scraping dynamique de pages Web en vous associant dès aujourd'hui à PromptCloud. Contactez-nous à sales@promptcloud.com.