
Scraping dynamique de pages Web avec Python – Guide pratique
Publié: 2024-06-08Le scraping dynamique du Web consiste à récupérer des données sur des sites Web qui génèrent du contenu en temps réel via JavaScript ou Python. Contrairement aux pages Web statiques, le contenu dynamique se charge de manière asynchrone, ce qui rend les techniques de scraping traditionnelles inefficaces.
Le web scraping dynamique utilise :
- Sites Web basés sur AJAX
- Applications d'une seule page (SPA)
- Sites avec éléments de chargement retardés
Outils et technologies clés :
- Selenium – Automatise les interactions du navigateur.
- BeautifulSoup – Analyse le contenu HTML.
- Requêtes – Récupère le contenu de la page Web.
- lxml – Analyse XML et HTML.
Python de scraping Web dynamique nécessite une compréhension plus approfondie des technologies Web pour collecter efficacement des données en temps réel.
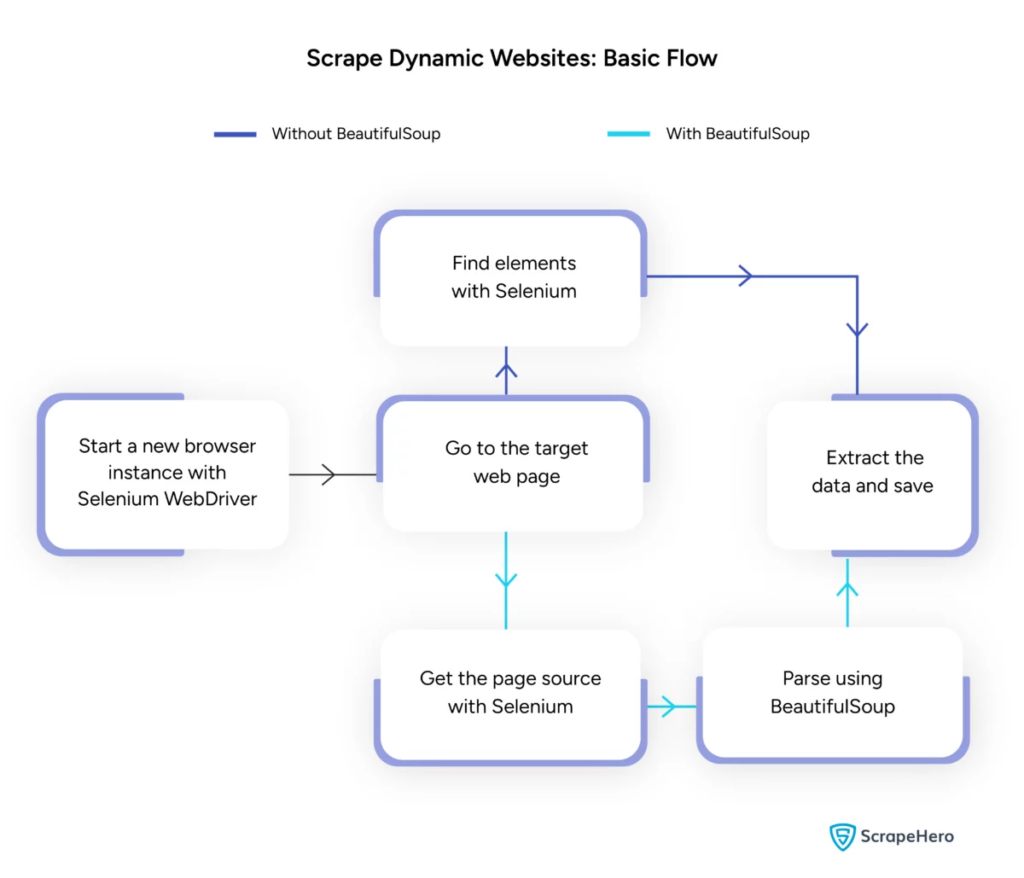
Source de l'image : https://www.scrapehero.com/scrape-a-dynamic-website/
Configuration de l'environnement Python
Pour commencer le web scraping dynamique Python, il est essentiel de configurer correctement l'environnement. Suivez ces étapes:
- Installer Python : assurez-vous que Python est installé sur la machine. La dernière version peut être téléchargée sur le site officiel de Python.
- Créer un environnement virtuel :

Activez l'environnement virtuel :

- Installer les bibliothèques requises :

- Configurer un éditeur de code : utilisez un IDE comme PyCharm, VSCode ou Jupyter Notebook pour écrire et exécuter des scripts.
- Familiarisez-vous avec HTML/CSS : Comprendre la structure des pages Web aide à naviguer et à extraire efficacement les données.
Ces étapes établissent une base solide pour les projets Python de scraping Web dynamique.
Comprendre les bases des requêtes HTTP
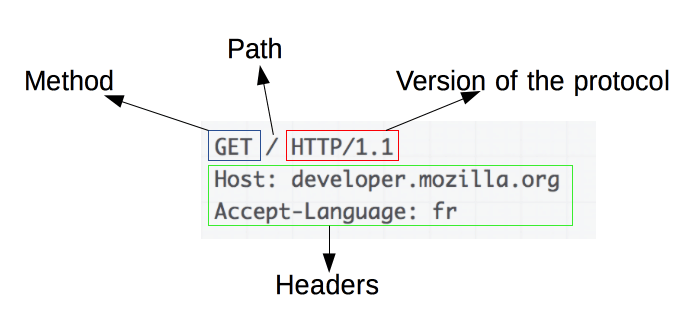
Source de l'image : https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
Les requêtes HTTP sont à la base du web scraping. Lorsqu'un client, comme un navigateur Web ou un grattoir Web, souhaite récupérer des informations sur un serveur, il envoie une requête HTTP. Ces demandes suivent une structure spécifique :
- Méthode : L'action à effectuer, telle que GET ou POST.
- URL : L'adresse de la ressource sur le serveur.
- En-têtes : métadonnées sur la demande, comme le type de contenu et l'agent utilisateur.
- Corps : données facultatives envoyées avec la requête, généralement utilisées avec POST.
Comprendre comment interpréter et construire ces composants est essentiel pour un web scraping efficace. Les bibliothèques Python comme les requêtes simplifient ce processus, permettant un contrôle précis sur les requêtes.
Installation des bibliothèques Python
Source de l'image : https://ajaytech.co/what-are-python-libraries/
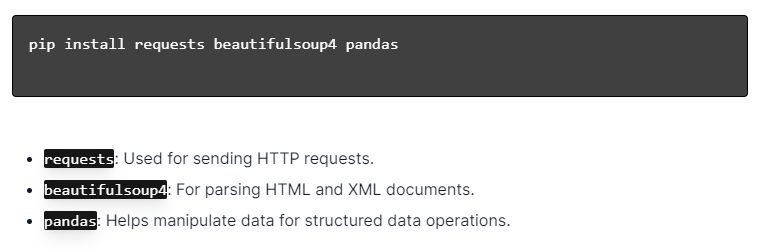
Pour le web scraping dynamique avec Python, assurez-vous que Python est installé. Ouvrez le terminal ou l'invite de commande et installez les bibliothèques nécessaires à l'aide de pip :
Ensuite, importez ces bibliothèques dans votre script :

Ce faisant, chaque bibliothèque sera mise à disposition pour des tâches de web scraping, telles que l'envoi de requêtes, l'analyse HTML et la gestion efficace des données.
Création d'un script de scraping Web simple
Pour créer un script de base de scraping Web dynamique en Python, il faut d'abord installer les bibliothèques nécessaires. La bibliothèque « request » gère les requêtes HTTP, tandis que « BeautifulSoup » analyse le contenu HTML.
Étapes à suivre:
- Installer les dépendances :

- Importer des bibliothèques :

- Obtenez du contenu HTML :
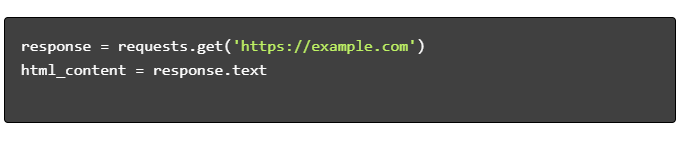
- Analyser le HTML :

- Extraire les données :

Gestion du Web Scraping dynamique avec Python
Les sites Web dynamiques génèrent du contenu à la volée, nécessitant souvent des techniques plus sophistiquées.

Considérez les étapes suivantes :
- Identifier les éléments cibles : inspectez la page Web pour localiser le contenu dynamique.
- Choisissez un framework Python : utilisez des bibliothèques comme Selenium ou Playwright.
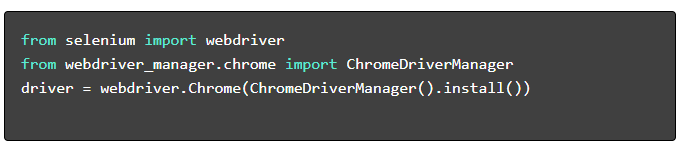
- Installer les packages requis :
- Configurer WebDriver :

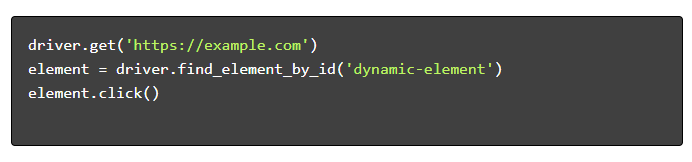
- Naviguez et interagissez :
Meilleures pratiques de scraping Web
Il est recommandé de suivre les meilleures pratiques de Web scraping pour garantir l’efficacité et la légalité. Vous trouverez ci-dessous les principales directives et stratégies de gestion des erreurs :
- Respectez Robots.txt : Vérifiez toujours le fichier robots.txt du site cible.
- Limitation : implémentez des délais pour éviter la surcharge du serveur.
- User-Agent : utilisez une chaîne User-Agent personnalisée pour éviter les blocages potentiels.
- Logique de nouvelle tentative : utilisez des blocs try-sauf et configurez une logique de nouvelle tentative pour gérer les délais d'attente du serveur.
- Journalisation : conservez des journaux complets pour le débogage.
- Gestion des exceptions : détectez spécifiquement les erreurs réseau, les erreurs HTTP et les erreurs d'analyse.
- Détection des Captcha : intégrez des stratégies pour détecter et résoudre ou contourner les CAPTCHA.
Défis courants du scraping dynamique du Web
Captchas
De nombreux sites Web utilisent des CAPTCHA pour empêcher les robots automatisés. Pour contourner cela :
- Utilisez des services de résolution de CAPTCHA comme 2Captcha.
- Mettez en œuvre une intervention humaine pour la résolution de CAPTCHA.
- Utilisez des proxys pour limiter les taux de demandes.
Blocage IP
Les sites peuvent bloquer les IP faisant trop de requêtes. Contrez cela en :
- Utilisation de proxys rotatifs.
- Implémentation de la limitation des requêtes.
- Utiliser des stratégies de rotation utilisateur-agent.
Rendu JavaScript
Certains sites chargent du contenu via JavaScript. Relevez ce défi en :
- Utilisation de Selenium ou Puppeteer pour l'automatisation du navigateur.
- Utilisation de Scrapy-splash pour le rendu du contenu dynamique.
- Explorer les navigateurs sans tête pour interagir avec JavaScript.
Probleme juridique
Le web scraping peut parfois enfreindre les conditions d’utilisation. Assurer la conformité en :
- Consultation de conseils juridiques.
- Récupération de données accessibles au public.
- Respect des directives robots.txt.
Analyse des données
La gestion de structures de données incohérentes peut s'avérer difficile. Les solutions incluent :
- Utiliser des bibliothèques comme BeautifulSoup pour l'analyse HTML.
- Utilisation d'expressions régulières pour l'extraction de texte.
- Utilisation des analyseurs JSON et XML pour les données structurées.
Stockage et analyse des données récupérées
Le stockage et l’analyse des données récupérées sont des étapes cruciales du web scraping. Le choix de l'emplacement de stockage des données dépend du volume et du format. Les options de stockage courantes incluent :
- Fichiers CSV : Facile pour les petits ensembles de données et les analyses simples.
- Bases de données : bases de données SQL pour données structurées ; NoSQL pour non structuré.
Une fois stockées, l'analyse des données peut être effectuée à l'aide des bibliothèques Python :
- Pandas : Idéal pour la manipulation et le nettoyage des données.
- NumPy : Efficace pour les opérations numériques.
- Matplotlib et Seaborn : Convient à la visualisation de données.
- Scikit-learn : Fournit des outils pour l'apprentissage automatique.
Un stockage et une analyse appropriés des données améliorent l’accessibilité et les informations sur les données.
Conclusion et prochaines étapes
Après avoir parcouru un Python de web scraping dynamique, il est impératif d'affiner la compréhension des outils et bibliothèques mis en avant.
- Réviser le code : consultez le script final et modularisez-le si possible pour améliorer la réutilisabilité.
- Bibliothèques supplémentaires : explorez des bibliothèques avancées comme Scrapy ou Splash pour des besoins plus complexes.
- Stockage des données : envisagez des options de stockage robustes : bases de données SQL ou stockage cloud pour gérer de grands ensembles de données.
- Considérations juridiques et éthiques : restez à jour sur les directives juridiques concernant le web scraping pour éviter les infractions potentielles.
- Projets suivants : s'attaquer à de nouveaux projets de web scraping avec des complexités différentes renforcera davantage ces compétences.
Vous cherchez à intégrer le web scraping dynamique professionnel avec Python dans votre projet ? Pour les équipes qui ont besoin d'une extraction de données à grande échelle sans la complexité de leur gestion en interne, PromptCloud propose des solutions sur mesure. Explorez les services de PromptCloud pour une solution robuste et fiable. Contactez-nous dès aujourd'hui !