
Analyse factorielle exploratoire en R
Publié: 2017-02-16Qu'est-ce que l'analyse factorielle exploratoire dans R ?
L'analyse factorielle exploratoire (EFA) ou plus ou moins connue sous le nom d'analyse factorielle dans R est une technique statistique utilisée pour identifier la structure relationnelle latente parmi un ensemble de variables et la réduire à un plus petit nombre de variables. Cela signifie essentiellement que la variance d'un grand nombre de variables peut être décrite par quelques variables sommaires, c'est-à-dire des facteurs. Voici un aperçu de l'analyse factorielle exploratoire dans R.
Comme son nom l'indique, l'EFA est de nature exploratoire - nous ne connaissons pas vraiment les variables latentes, et les étapes sont répétées jusqu'à ce que nous arrivions à un nombre inférieur de facteurs. Dans ce didacticiel, nous examinerons EFA à l'aide de R. Maintenant, voyons d'abord l'idée de base de l'ensemble de données.
1. Les données
Cet ensemble de données contient 90 réponses pour 14 variables différentes que les clients prennent en compte lors de l'achat d'une voiture. Les questions du sondage ont été formulées à l'aide d'une échelle de Likert à 5 points, 1 étant très faible et 5 étant très élevé. Les variables étaient les suivantes :
- Prix
- Sécurité
- Aspect extérieur
- Espace et confort
- Technologie
- Service après-vente
- Valeur de revente
- Type de carburant
- La consommation de carburant
- Couleur
- Entretien
- Essai routier
- Avis sur les produits
- Témoignages
Cliquez ici pour télécharger le jeu de données codé.
2. Importation de données Web
Nous allons maintenant lire le jeu de données présent au format CSV dans R et le stocker en tant que variable.
[code language=”r”] data <- read.csv(file.choose( ),en-tête=VRAI) [/code]
Cela ouvrira une fenêtre pour choisir le fichier CSV et l'option `header` s'assurera que la première ligne du fichier est considérée comme l'en-tête. Entrez ce qui suit pour voir les premières lignes du bloc de données et confirmer que les données ont été stockées correctement.
[code language="r"] tête(données) [/code]
3. Installation du paquet
Nous allons maintenant installer les packages requis pour effectuer une analyse plus approfondie. Ces packages sont `psych` et `GPRotation`. Dans le code ci-dessous, nous appelons `install.packages()` pour l'installation.
[code language=”r”] install.packages('psych') install.packages('GPRotation') [/code]
4. Nombre de facteurs
Ensuite, nous découvrirons le nombre de facteurs que nous sélectionnerons pour l'analyse factorielle. Ceci est évalué via des méthodes telles que "l'analyse parallèle" et la "valeur propre", etc.
Analyse parallèle
Nous utiliserons la fonction `fa.parallel` du package `Psych` pour exécuter l'analyse parallèle. Ici, nous spécifions le cadre de données et la méthode factorielle ("minres" dans notre cas). Exécutez la commande suivante pour trouver un nombre acceptable de facteurs et générer le "scree plot" :
[code language=”r”] parallèle <- fa.parallel(data, fm = 'minres', fa = 'fa') [/code]
La console afficherait le nombre maximum de facteurs que nous pouvons prendre en compte. Voici à quoi cela ressemblerait.
"L'analyse parallèle suggère que le nombre de facteurs = 5 et le nombre de composants = NA"
Donné ci-dessous dans le `scree plot` généré à partir du code ci-dessus :
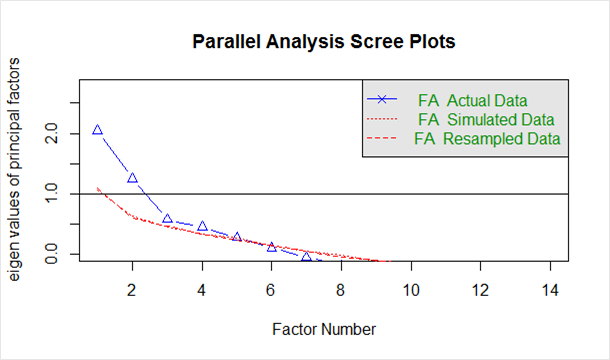
La ligne bleue montre les valeurs propres des données réelles et les deux lignes rouges (placées l'une au-dessus de l'autre) montrent les données simulées et rééchantillonnées. Ici, nous examinons les fortes baisses des données réelles et repérons le point où elles se stabilisent vers la droite. En outre, nous localisons le point d'inflexion - le point où l'écart entre les données simulées et les données réelles tend à être minimum.

En regardant ce graphique et cette analyse parallèle, n'importe où entre 2 et 5 facteurs serait un bon choix.
Analyse factorielle
Maintenant que nous sommes arrivés à un nombre probable de facteurs, commençons par 3 comme nombre de facteurs. Afin d'effectuer une analyse factorielle, nous utiliserons la fonction `psych` packages`fa(). Ci-dessous sont les arguments que nous fournirons :
- r – Données brutes ou matrice de corrélation ou de covariance
- nfactors – Nombre de facteurs à extraire
- rotation - Bien qu'il existe différents types de rotations, `Varimax` et `Oblimin` sont les plus populaires
- fm - L'une des techniques d'extraction de facteurs comme `Minimum Residual (OLS)`, `Maximum Liklihood`, `Principal Axis` etc.
Dans ce cas, nous choisirons la rotation oblique (rotate = « oblimin ») car nous pensons qu'il existe une corrélation entre les facteurs. Notez que la rotation Varimax est utilisée sous l'hypothèse que les facteurs sont complètement non corrélés. Nous utiliserons la factorisation `Ordinary Least Squared/Minres` (fm = "minres"), car elle est connue pour fournir des résultats similaires à `Maximum Likelihood` sans supposer une distribution normale multivariée et dérive des solutions par décomposition itérative propre comme un axe principal.
Exécutez ce qui suit pour démarrer l'analyse.
[code language=”r”] threefactor <- fa(data,nfactors = 3, rotation = "oblimin", fm = "minres") impression (trois facteurs) [/code]
Voici la sortie montrant les facteurs et les chargements :
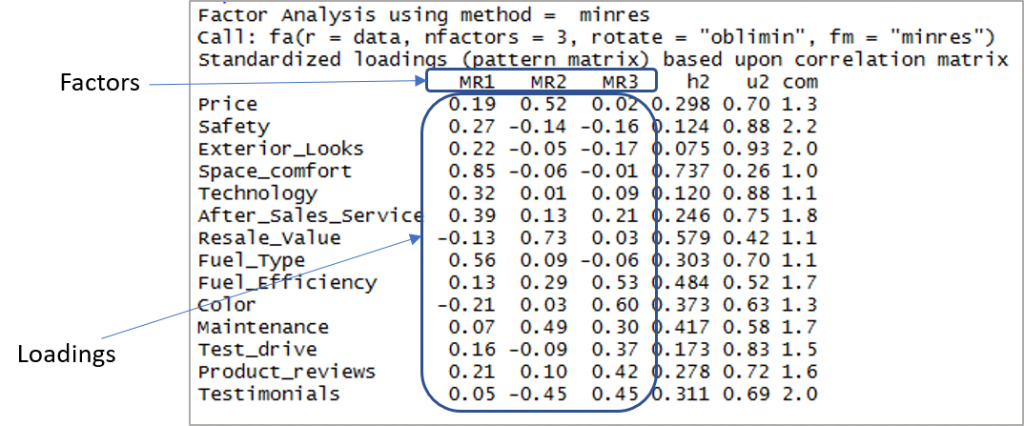
Maintenant, nous devons considérer les chargements de plus de 0,3 et ne pas charger sur plus d'un facteur. Notez que les valeurs négatives sont acceptables ici. Alors commençons par établir le cut-off pour améliorer la visibilité.
[code language="r"] print(threefactor$loadings,cutoff = 0.3) [/code]
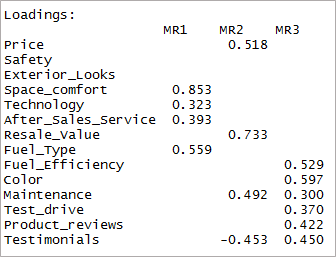
Comme vous pouvez le voir, deux variables sont devenues insignifiantes et deux autres ont un double chargement. Ensuite, nous examinerons les '4' facteurs.
[code language=”r”] fourfactor <- fa(data,nfactors = 4, rotate = "oblimin",fm="minres") print(fourfactor$loadings,cutoff = 0.3) [/code]
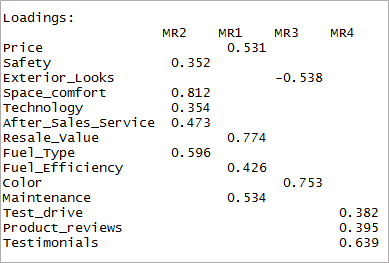
Nous pouvons voir qu'il en résulte un seul chargement. C'est ce qu'on appelle la structure simple.
Appuyez sur ce qui suit pour consulter la cartographie des facteurs.
[code language="r"] fa.diagram(fourfactor) [/code]
Test d'adéquation
Maintenant que nous avons atteint une structure simple, il est temps pour nous de valider notre modèle. Examinons la sortie de l'analyse factorielle pour continuer.

La racine signifie que le carré des résidus (RMSR) est de 0,05. Ceci est acceptable car cette valeur doit être plus proche de 0. Ensuite, nous devons vérifier l'indice RMSEA (erreur quadratique moyenne d'approximation). Sa valeur, 0,001, montre un bon ajustement du modèle car elle est inférieure à 0,05. Enfin, l'indice Tucker-Lewis (TLI) est de 0,93 - une valeur acceptable étant donné qu'il est supérieur à 0,9.
Nommer les facteurs

Après avoir établi l'adéquation des facteurs, il est temps pour nous de nommer les facteurs. C'est le côté théorique de l'analyse où l'on forme les facteurs en fonction des chargements variables. Dans ce cas, voici comment les facteurs peuvent être créés.
Conclusion
Dans ce didacticiel pour l'analyse dans r, nous avons discuté de l'idée de base de l'EFA (analyse factorielle exploratoire dans R), couvert l'analyse parallèle et l'interprétation des diagrammes d'éboulis. Ensuite, nous sommes passés à l'analyse factorielle dans R pour obtenir une structure simple et la valider pour garantir l'adéquation du modèle. Enfin arrivé aux noms des facteurs à partir des variables. Maintenant, allez-y, essayez-le et publiez vos découvertes dans la section des commentaires.