
La voix du bazar
Publié: 2024-04-24Cet article sur la modernisation des systèmes existants accompagne une conférence que j'ai récemment présentée lors de l'AWS Data Summit pour les éditeurs de logiciels sur la génération de valeur à partir des données en tirant parti de nos meilleures pratiques pour garantir le succès des projets d'apprentissage automatique. Vous pouvez aller jusqu'en bas ici pour le regarder si vous préférez.
Soyons réalistes : un logiciel est plus facile à écrire qu'à maintenir. C'est pourquoi nous, en tant qu'ingénieurs logiciels, préférons simplement « l'arracher et recommencer » au lieu d'essayer de comprendre ce que pensait un autre développeur (ou notre ancien moi). Nous semblons avoir collectivement oublié que « les programmes doivent être écrits pour que les gens puissent les lire, et seulement accessoirement pour que les machines les exécutent ».
Vous savez que c'est vrai - nous avons tous dû parcourir minutieusement une casserole de code spaghetti et de fines abstractions de style ancien, creusant la viande du programme pour ne trouver rien d'autre qu'un désordre au fond de nos assiettes.
Il est facile de crier « WTF » et de blâmer le développeur précédent, mais la vérité est souvent plus compliquée. Nous ne pouvons pas voir l'avenir, il est donc impossible de comprendre comment les exigences, la technologie ou les objectifs commerciaux évolueront lorsque nous concevrons un nouveau système. En conséquence, les systèmes peuvent devenir illisibles à mesure que leur portée augmente et que l'entreprise en dépend. C’est un peu un paradoxe : les systèmes plus anciens et plus difficiles à entretenir offrent souvent le plus de valeur. Il est difficile de travailler dessus parce qu'ils ont grandi avec l'entreprise, et c'est effrayant de travailler dessus parce que les briser pourrait être une catastrophe.
C'est ici que je vous appelle : si vous aimez les problèmes difficiles et enrichissants… essayez-le. Prenez le système le plus ancien dont vous disposez et rendez-le maintenable. Vous savez de celui dont je parle – celui que personne ne « possédera ». Celui-là dont dépendent les autres départements mais que les ingénieurs détestent. Celui sur lequel vous avez dû patcher Log4Shell en premier . Fais-le. Je te défie.
J'ai récemment eu l'occasion de mettre à jour un système d'apprentissage automatique vieux de dix ans chez Bazaarvoice. En apparence, cela n'avait pas l'air excitant : cette chose n'avait même pas de réseaux de neurones ! Qui s'en soucie! Eh bien… c'était important. Ce système traite presque tous les avis de produits générés par les utilisateurs et reçus par Bazaarvoice (près de 9 millions par mois) et le fait avec 90 millions d'appels d'inférence à des modèles d'apprentissage automatique. Ouais, 90 millions d'inférences ! C'est une échelle énorme et j'avais hâte de m'y plonger.
Dans cet article, je vais expliquer comment la modernisation de cet ancien système grâce à une réarchitecture, au lieu d'une réécriture, nous a permis de le rendre évolutif et rentable sans avoir à supprimer tout le code et à recommencer. Le système résultant est sans serveur, conteneurisé et maintenable tout en réduisant nos coûts d'hébergement de près de 80 %.
Qu’est-ce qu’un système existant ?
Un système existant fait référence à un logiciel et/ou à du matériel informatique vieillissant qui reste opérationnel. Bien qu’il puisse encore remplir son objectif initial, il manque d’évolutivité pour une croissance future.
Anciens systèmes hérités
Tout d’abord, jetons un coup d’œil à ce à quoi nous avons affaire ici. L'ancien système que mon équipe mettait à jour modère le contenu généré par les utilisateurs pour l'ensemble de Bazaarvoice. Plus précisément, il détermine si chaque élément de contenu est approprié pour les sites Web de nos clients.

Cela semble simple – éliminer les infractions évidentes telles que les discours de haine, les propos grossiers ou les sollicitations – mais en pratique, c'est beaucoup plus nuancé. Chaque client a des exigences uniques quant à ce qu’il considère approprié. Les marques de bière, par exemple, s'attendraient à des discussions sur l'alcool, mais pas une marque pour enfants. Nous capturons ces options spécifiques aux clients lorsque nous intégrons de nouveaux clients, et notre équipe du service client les encode dans une base de données de gestion.
Pour une complexité supplémentaire, nous échantillonnons également un sous-ensemble de notre contenu pour qu'il soit modéré par des modérateurs humains. Cela nous permet de mesurer en permanence les performances de nos modèles et de découvrir des opportunités pour créer davantage de modèles.
L'architecture complète de notre ancien système est présentée ci-dessous :
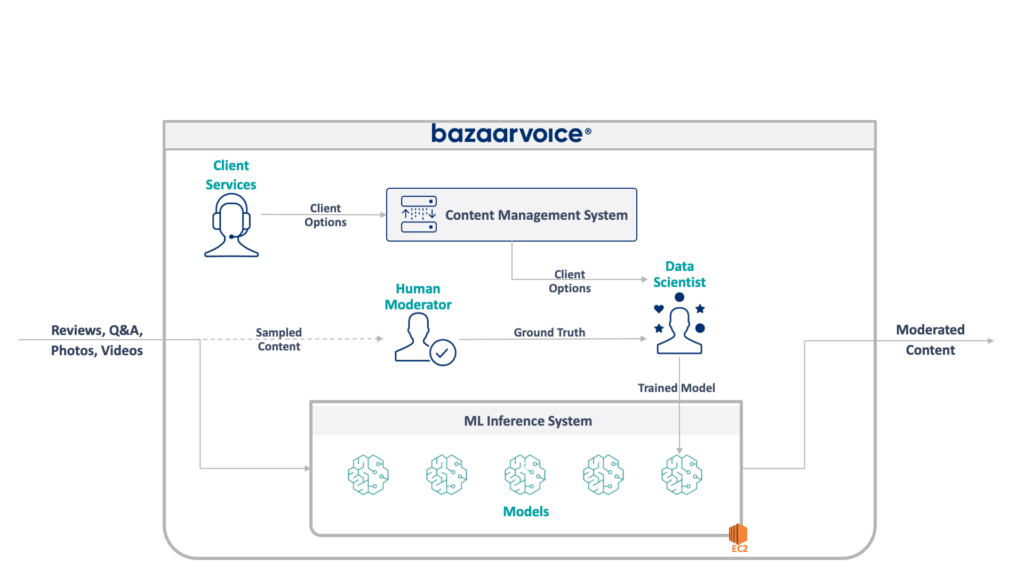
Ce système présente de sérieux inconvénients. Plus précisément, tous les modèles sont hébergés sur une seule instance EC2. Cela n'était pas dû à une mauvaise ingénierie, mais simplement à l'incapacité des programmeurs d'origine à prévoir l'échelle souhaitée par l'entreprise. Personne ne pensait qu’il grandirait autant.
De plus, le système a souffert du rejet des développeurs : il était écrit en Scala, ce que peu d'ingénieurs comprenaient. Ainsi, il était souvent négligé pour être amélioré puisque personne ne voulait y toucher.
En conséquence, le système a continué à se développer tout en gardant les lumières allumées. Une fois que nous avons commencé à le restructurer, il fonctionnait sur une seule instance x1e.8xlarge. Cette chose avait près d'un téraoctet de RAM et coûtait environ 5 000 $/mois (sans réserve) pour fonctionner. Ne vous inquiétez pas, nous venons d'en lancer un deuxième pour la redondance et un troisième pour l'assurance qualité.
Ce système était coûteux à exploiter et présentait un risque élevé d'échec (un seul mauvais modèle peut faire échouer l'ensemble du service). De plus, la base de code n'avait pas été activement développée et était donc nettement obsolète par rapport aux packages modernes de science des données et ne suivait pas nos pratiques standard pour les services écrits en Scala.
Un nouveau système
Lors de la refonte de ce système, nous avions un objectif clair : le rendre évolutif. La réduction des coûts d'exploitation était un objectif secondaire, tout comme la simplification de la gestion des modèles et des codes.
Le nouveau design que nous avons imaginé est illustré ci-dessous :

Notre approche pour résoudre tout cela consistait à placer chaque modèle d'apprentissage automatique sur un point de terminaison SageMaker Serverless isolé. À l'instar des fonctions AWS Lambda, les points de terminaison sans serveur s'éteignent lorsqu'ils ne sont pas utilisés, ce qui nous permet d'économiser des coûts d'exécution pour les modèles rarement utilisés. Ils peuvent également évoluer rapidement en réponse à l’augmentation du trafic.

De plus, nous avons exposé les options client à un microservice unique qui achemine le contenu vers les modèles appropriés. Il s’agissait de l’essentiel du nouveau code que nous devions écrire : une petite API facile à maintenir et permettant à nos data scientists de mettre à jour et de déployer plus facilement de nouveaux modèles.
Cette approche présente les avantages suivants :
- Diminution du temps de valorisation de plus de 6x. Plus précisément, l'acheminement du trafic vers les modèles existants est instantané et le déploiement de nouveaux modèles peut être effectué en moins de 5 minutes au lieu de 30.
- Évoluez sans limite : nous disposons actuellement de 400 modèles, mais nous prévoyons d'en étendre la portée à des milliers pour continuer à augmenter la quantité de contenu que nous pouvons modérer automatiquement.
- Nous avons constaté une réduction des coûts de 82 % en abandonnant EC2, car les fonctions se désactivent lorsqu'elles ne sont pas utilisées, et nous ne payons pas pour des machines haut de gamme sous-utilisées.
Cependant, la simple conception d'une architecture idéale ne constitue pas la partie la plus difficile et la plus intéressante de la reconstruction d'un système existant : vous devez migrer vers celui-ci.
Notre premier défi en matière de migration a été de déterminer comment diable migrer un modèle Java WEKA pour l'exécuter sur SageMaker, sans parler de SageMaker Serverless.
Heureusement, SageMaker déploie des modèles dans des conteneurs Docker, nous pouvons donc au moins geler les versions Java et les dépendances pour qu'elles correspondent à notre ancien code. Cela permettrait de garantir que les modèles hébergés dans le nouveau système renvoient les mêmes résultats que l'ancien système.

Pour rendre le conteneur compatible avec SageMaker, il vous suffit d'implémenter quelques points de terminaison HTTP spécifiques :
-
POST /invocation– accepte les entrées, effectue des inférences et renvoie les résultats. -
GET /ping- renvoie 200 si le serveur JVM est sain
(Nous avons choisi d'ignorer toutes les embrouilles autour des conteneurs multimodèles BYO et de la boîte à outils d'inférence SageMaker.)
Quelques abstractions rapides autour de com.sun.net.httpserver.HttpServer et nous étions prêts à partir.
Et tu sais quoi? C'était en fait plutôt amusant. Jouer avec les conteneurs Docker et forcer quelque chose de 10 ans dans SageMaker Serverless avait une ambiance un peu bricolée. C'était assez excitant quand nous l'avons fait fonctionner, surtout lorsque nous avons obtenu le code système existant pour le construire dans notre nouvelle pile sbt au lieu de maven.
La nouvelle pile sbt a facilité le travail et la conteneurisation a permis d'obtenir un comportement approprié lors de l'exécution dans l'environnement SageMaker.
Migration vers un nouveau système
Nous avons donc les modèles dans des conteneurs et pouvons les déployer sur SageMaker – presque terminé, n'est-ce pas ? Pas assez.
La dure leçon de la migration vers une nouvelle architecture est que vous devez construire trois fois votre système actuel juste pour prendre en charge la migration. En plus du nouveau système, nous avons dû construire :
- Un pipeline de capture de données dans l'ancien système pour enregistrer les entrées et les sorties du modèle. Nous les avons utilisés pour confirmer que le nouveau système renverrait les mêmes résultats
- Un pipeline de traitement des données dans le nouveau système pour calculer les résultats et les comparer aux données de l'ancien système. Cela impliquait une grande quantité de mesures avec Datadog et devait offrir la possibilité de relire les données lorsque nous trouvions des écarts.
- Un système de déploiement complet des modèles pour éviter d'impacter les utilisateurs de l'ancien système (qui téléchargerait simplement les modèles sur S3). Nous savions que nous souhaitions éventuellement les migrer vers une API, mais pour la version initiale, nous devions le faire de manière transparente.
Tout cela était du code jetable que nous savions pouvoir lancer une fois la migration de tous les utilisateurs terminée, mais nous devions quand même le construire et nous assurer que les résultats du nouveau système correspondaient à l'ancien.
Attendez-vous à cela dès le départ.
Même si la création des outils et des systèmes de migration a certainement pris plus de 60 % de notre temps d'ingénierie sur ce projet, ce fut également une expérience amusante. Les tests unitaires ressemblent davantage à des expériences de science des données : nous avons écrit des suites entières pour nous assurer que nos résultats correspondent exactement . C’était une façon différente de penser qui rendait le travail encore plus amusant. Un pas hors de nos sentiers battus, si vous voulez.
Moderniser les systèmes existants grâce à une réarchitecture
La prochaine fois que vous serez tenté de reconstruire un système à partir du code, je voudrais vous encourager à essayer de migrer l'architecture plutôt que le code. Vous découvrirez des défis techniques intéressants et enrichissants et vous apprécierez probablement bien plus cela que le débogage de cas extrêmes inattendus de votre nouveau code.
Vous voulez en savoir plus ? Regardez ci-dessous la conférence que j'ai donnée lors de l'AWS Data Summit, qui approfondit le côté MLOps.