
Les gens recherchent également ou le font-ils toujours ? Comment Google pourrait utiliser un modèle génératif entraîné pour générer des variantes de requête pour des fonctionnalités de recherche telles que PASF, PAA et plus [Brevet]
Publié: 2023-06-27
Je vérifiais certains brevets de Google l'autre jour et j'en ai découvert un intéressant qui a été accordé et publié le 30 mai 2023. Il s'intitulait "Générer des variantes de requête à l'aide d'un modèle génératif formé" et cela a définitivement piqué ma curiosité. Il a été initialement déposé en 2018, mais a été accordé fin mai. Et comme je suis toujours intéressé par les fonctionnalités SERP importantes telles que People Also Ask (PAA) et People Also Search For (PASF), j'ai dû creuser.
De plus, c'est quelque chose dont j'aurais parlé au brillant Bill Slawski dans le passé. Malheureusement, Bill n'est plus avec nous. En parcourant le brevet, j'ai réalisé à quel point les messages de Bill sur les brevets me manquaient et de pouvoir lui poser des questions sur son analyse. Perdre Bill a définitivement été une perte massive pour notre industrie. Quoi qu'il en soit, sans Bill pour creuser comme il le ferait toujours, j'ai décidé de commencer à creuser moi-même. Et je suis content de l'avoir fait. C'était super intéressant.
Tirer parti des modèles génératifs à l'aide de réseaux de neurones pour les fonctionnalités SERP
Ci-dessous, j'expliquerai comment le brevet décrit l'utilisation d'un modèle génératif formé pour générer des variantes de requête pour les fonctionnalités SERP telles que "Les gens recherchent également", "Les gens demandent également", et peut-être plus. Le brevet mentionne "Les gens recherchent également", mais il n'est pas exagéré de croire que le processus pourrait également être utilisé pour le PAA. Je couvre cela dans mon analyse ci-dessous.
Il était fascinant d'en savoir plus sur ce que Google fait sur ce front (au moins sur la base du brevet). Comme pour tout brevet, nous ne savons pas si Google l'a déjà implémenté, ou s'il le fera, mais cela avait du sens d'après ce que je lisais.
De plus, et j'ai trouvé cela fascinant, le brevet expliquait comment Google pouvait même générer des variantes de requête pour de nouvelles requêtes (toutes nouvelles) et des requêtes à longue traîne pour lesquelles il n'y avait pas encore beaucoup de données disponibles. Et avec 15% de toutes les requêtes jamais vues par Google auparavant, il serait logique d'utiliser une approche comme pour générer des variantes de requête. Je couvrirai plus à ce sujet bientôt.
Points clés du brevet :
Je pense que la meilleure façon de couvrir le brevet est d'énumérer certains des faits saillants. Ci-dessous, je couvrirai plusieurs points clés du brevet, que j'espère que vous trouverez également intéressants.
Génération de variantes de requête à l'aide d'un modèle génératif formé
États-Unis 11663201 B2
Date d'octroi : 30 mai 2023
Date de dépôt : 27 avril 2018
Nom du cessionnaire : Google LLC
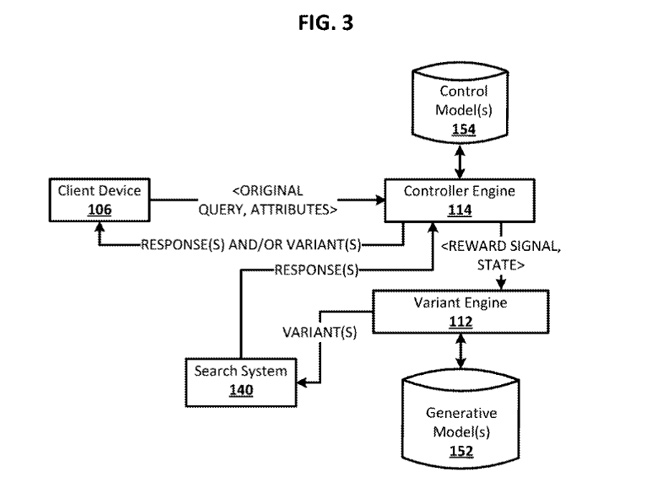
1. Des variantes de requête peuvent être générées au moment de l'exécution à l'aide d'un modèle génératif formé basé sur des jetons des requêtes d'origine et des fonctionnalités d'entrée supplémentaires. Je couvrirai plus sur les fonctionnalités d'entrée supplémentaires bientôt.
2. Le système peut générer des variantes de requête même lorsque le modèle n'est pas entraîné sur cette requête. Ainsi, il peut générer des variantes pour de nouvelles requêtes (toutes nouvelles) ou ce que Google appelle des requêtes "de queue" où il n'y a pas encore beaucoup de données. J'ai trouvé cela très intéressant, d'autant plus que Google affirme que 15 % des requêtes n'ont jamais été vues auparavant. Ainsi, le modèle génératif peut prédire quelles variantes de requête générer même pour les requêtes à seuil bas en utilisant un réseau de neurones (avec des couches de mémoire).

3. Le modèle génératif peut être formé sur la base des soumissions de requêtes précédentes par les utilisateurs. Mais le brevet explique également que les données d'apprentissage des variantes de requête peuvent également être basées sur des paires de requêtes qui ont des clics sur les mêmes documents. Cela a du sens et montre comment l'engagement des utilisateurs peut jouer un rôle dans ce qui est généré par le modèle.

4. Le brevet explique également que le modèle peut être formé comme un modèle multitâche pour permettre la génération de plusieurs types de variantes de requête. Il s'agit donc d'un système sophistiqué qui peut générer différents types de variantes de requête, notamment des requêtes de suivi, des requêtes de généralisation, des requêtes de canonisation, des requêtes de traduction de langue, des requêtes d'implication, etc.


5. Une fois les variantes de requête générées, elles sont notées par le modèle. Le système fournit des scores de réponse pour chaque variante. Et le système peut noter ces variantes en vérifiant les réponses à ces variantes de requête. Cela peut aider le système à détecter les variantes de requête « potentiellement fausses ». Très intéressant…

6. Le brevet poursuit en expliquant que le système peut renvoyer des réponses en plus des variantes de requête. Par exemple, le système peut renvoyer un résultat de recherche (PAA quelqu'un ?), une entité de graphe de connaissances, une réponse nulle (pas de réponse) ou même une invite de clarification (avec une entrée d'interface utilisateur clarifiante). Cela pourrait prendre la forme de puces d'homonymie que nous voyons lorsque Google recherche l'aide des utilisateurs pour essayer de comprendre ce que l'utilisateur recherche. Encore une fois, intéressant.

7. Le brevet poursuit en expliquant que le modèle peut prendre plus que de simples jetons de la requête, y compris des "caractéristiques d'entrée supplémentaires". Ces caractéristiques d'entrée peuvent inclure l'emplacement, une tâche qui intéresse ou exécute l'utilisateur (comme cuisiner, réparer une voiture, planifier un voyage, etc.). Il peut également prendre en compte la météo et plus encore. Et la tâche peut être basée sur des entrées de calendrier stockées pour l'utilisateur, des messages de chat ou d'autres communications, des requêtes passées soumises par l'utilisateur, etc. Ainsi, les variantes de requête peuvent être basées sur la personnalisation ou le contexte actuel.

8. Le modèle peut également générer des variantes d'une requête et des publicités ou d'autres contenus . Ainsi, le modèle peut non seulement générer des variantes de requête, mais il peut également générer (ou peut-être récupérer) des publicités ou d'autres contenus pouvant être affichés dans les SERP. Je pense que je dois revoir cette section, mais c'était intéressant… :)

9. Le brevet explique également qu'il peut y avoir un certain nombre de modèles génératifs basés sur différents attributs ou tâches. Il peut donc y avoir des modèles spécifiques pour diverses tâches comme faire du shopping, se rendre à un endroit, etc.

Résumé : La génération de variantes pour PASF et PAA peut être plus compliquée et nuancée que certains ne le pensent.
J'espère que la décomposition de ce brevet vous a un peu aidé à comprendre comment Google pourrait utiliser un modèle génératif formé pour générer des variantes de requête, ou d'autres contenus, qui peuvent être affichés dans diverses fonctionnalités SERP. Et cela peut se produire pour les nouvelles requêtes (nouvelles) et les requêtes à longue traîne où il n'y a pas encore beaucoup de données. De plus, il pourrait y avoir plusieurs modèles utilisés qui se concentrent sur une discipline spécifique. Et les résultats peuvent également être personnalisés (basés sur des fonctionnalités d'entrée supplémentaires).
Ainsi, la prochaine fois que vous afficherez "Les gens recherchent également" ou "Les gens demandent également" dans les SERP, sachez qu'un modèle génératif a peut-être été utilisé pour fournir ces variantes de requête. Et si elles sont personnalisées, ces requêtes sont peut-être spécifiques à votre cas. Encore une fois, les systèmes de Google sont beaucoup plus sophistiqués que certains ne le pensent.
GG