
Comment fonctionne un robot d'exploration Web
Publié: 2023-12-05Les robots d'exploration Web jouent un rôle essentiel dans l'indexation et la structuration des nombreuses informations présentes sur Internet. Leur rôle consiste à parcourir des pages Web, à collecter des données et à les rendre consultables. Cet article explore les mécanismes d'un robot d'exploration Web, fournissant un aperçu de ses composants, de ses opérations et de ses diverses catégories. Plongeons dans le monde des robots d'exploration Web !
Qu'est-ce qu'un robot d'exploration Web
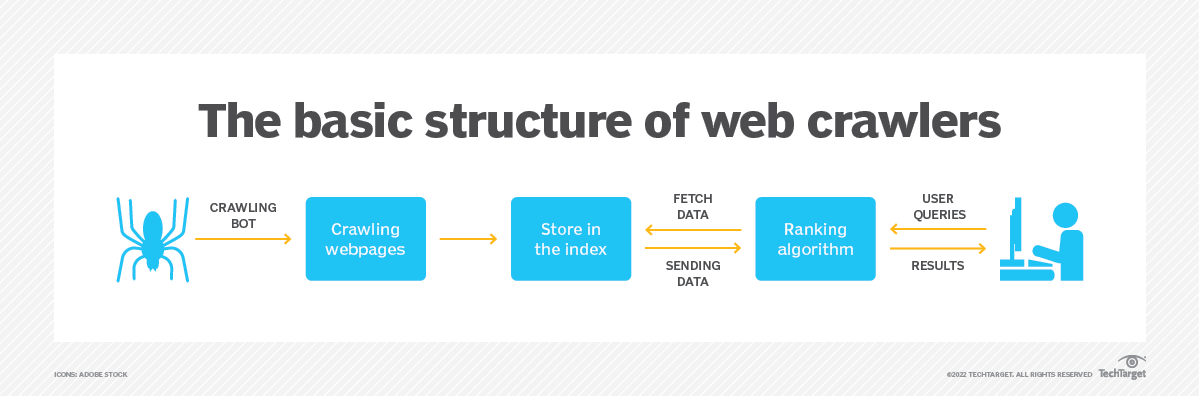
Un robot d'exploration Web, appelé araignée ou robot, est un script ou un programme automatisé conçu pour naviguer méthodiquement sur les sites Web Internet. Il commence par une URL de départ, puis suit des liens HTML pour visiter d'autres pages Web, formant ainsi un réseau de pages interconnectées qui peuvent être indexées et analysées.
Source de l'image : https://www.techtarget.com/
Le but d'un robot d'exploration Web
L'objectif principal d'un robot d'exploration Web est de collecter des informations à partir de pages Web et de générer un index consultable pour une récupération efficace. Les principaux moteurs de recherche tels que Google, Bing et Yahoo s'appuient fortement sur les robots d'exploration Web pour construire leurs bases de données de recherche. Grâce à l'examen systématique du contenu Web, les moteurs de recherche peuvent fournir aux utilisateurs des résultats de recherche pertinents et actuels.
Il est important de noter que l’application des robots d’exploration Web s’étend au-delà des moteurs de recherche. Ils sont également utilisés par diverses organisations pour des tâches telles que l'exploration de données, l'agrégation de contenu, la surveillance de sites Web et même la cybersécurité.
Les composants d'un robot d'exploration Web
Un robot d'exploration Web comprend plusieurs composants travaillant ensemble pour atteindre ses objectifs. Voici les composants clés d’un robot d’exploration Web :
- URL Frontier : ce composant gère la collection d'URL en attente d'exploration. Il hiérarchise les URL en fonction de facteurs tels que la pertinence, la fraîcheur ou l'importance du site Web.
- Téléchargeur : le téléchargeur récupère les pages Web en fonction des URL fournies par la frontière URL. Il envoie des requêtes HTTP aux serveurs Web, reçoit des réponses et enregistre le contenu Web récupéré pour un traitement ultérieur.
- Analyseur : l'analyseur traite les pages Web téléchargées et en extrait des informations utiles telles que des liens, du texte, des images et des métadonnées. Il analyse la structure de la page et extrait les URL des pages liées à ajouter à la frontière URL.
- Stockage des données : le composant de stockage de données stocke les données collectées, y compris les pages Web, les informations extraites et les données d'indexation. Ces données peuvent être stockées dans différents formats comme une base de données ou un système de fichiers distribué.
Comment fonctionne un robot d'exploration Web
Après avoir pris connaissance des éléments impliqués, examinons la procédure séquentielle qui explique le fonctionnement d'un robot d'exploration Web :
- URL de départ : le robot commence par une URL de départ, qui peut être n'importe quelle page Web ou une liste d'URL. Cette URL est ajoutée à la frontière de l'URL pour lancer le processus d'exploration.
- Récupération : le robot d'exploration sélectionne une URL dans la frontière d'URL et envoie une requête HTTP au serveur Web correspondant. Le serveur répond avec le contenu de la page Web, qui est ensuite récupéré par le composant de téléchargement.
- Analyse : l'analyseur traite la page Web récupérée, en extrayant les informations pertinentes telles que les liens, le texte et les métadonnées. Il identifie et ajoute également les nouvelles URL trouvées sur la page à la frontière des URL.
- Analyse des liens : le robot d'exploration hiérarchise et ajoute les URL extraites à la frontière des URL en fonction de certains critères tels que la pertinence, la fraîcheur ou l'importance. Cela permet de déterminer l'ordre dans lequel le robot visitera et explorera les pages.
- Répéter le processus : le robot poursuit le processus en sélectionnant les URL à partir de la frontière des URL, en récupérant leur contenu Web, en analysant les pages et en extrayant davantage d'URL. Ce processus est répété jusqu'à ce qu'il n'y ait plus d'URL à explorer ou qu'une limite prédéfinie soit atteinte.
- Stockage des données : tout au long du processus d'analyse, les données collectées sont stockées dans le composant de stockage de données. Ces données peuvent ensuite être utilisées à des fins d’indexation, d’analyse ou à d’autres fins.
Types de robots d'exploration Web
Les robots d'exploration Web se déclinent en différentes variantes et ont des cas d'utilisation spécifiques. Voici quelques types de robots d’exploration Web couramment utilisés :

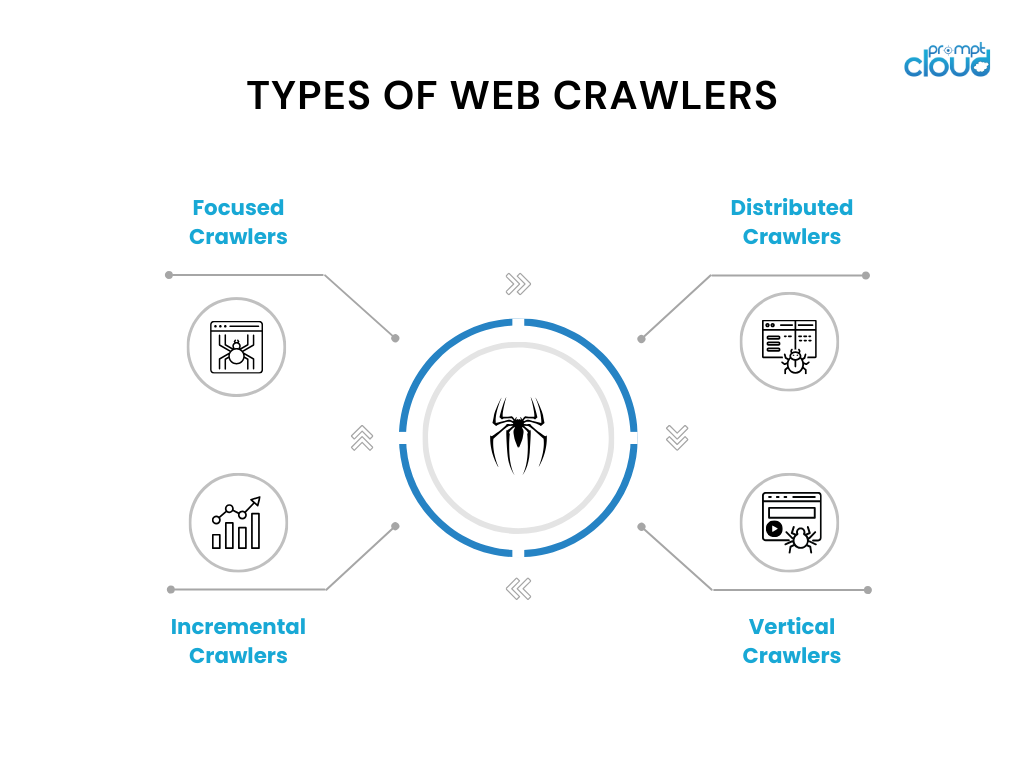
- Robots d'exploration ciblés : ces robots d'exploration opèrent dans un domaine ou un sujet spécifique et explorent les pages pertinentes pour ce domaine. Les exemples incluent les robots d'exploration thématiques utilisés pour les sites Web d'actualités ou les articles de recherche.
- Robots d'exploration incrémentiels : les robots d'exploration incrémentiels se concentrent sur l'exploration du contenu nouveau ou mis à jour depuis la dernière exploration. Ils utilisent des techniques telles que l'analyse d'horodatage ou des algorithmes de détection de modifications pour identifier et explorer les pages modifiées.
- Robots d'exploration distribués : dans les robots d'exploration distribués, plusieurs instances du robot d'exploration s'exécutent en parallèle, partageant la charge de travail d'exploration d'un grand nombre de pages. Cette approche permet une exploration plus rapide et une évolutivité améliorée.
- Robots d'exploration verticaux : les robots d'exploration verticaux ciblent des types spécifiques de contenu ou de données dans les pages Web, tels que des images, des vidéos ou des informations sur les produits. Ils sont conçus pour extraire et indexer des types spécifiques de données pour les moteurs de recherche spécialisés.
À quelle fréquence devez-vous explorer les pages Web ?
La fréquence d'exploration des pages Web dépend de plusieurs facteurs, notamment la taille et la fréquence de mise à jour du site Web, l'importance des pages et les ressources disponibles. Certains sites Web peuvent nécessiter une exploration fréquente pour garantir que les informations les plus récentes sont indexées, tandis que d'autres peuvent être explorés moins fréquemment.
Pour les sites Web à fort trafic ou ceux dont le contenu évolue rapidement, une exploration plus fréquente est essentielle pour maintenir les informations à jour. D’un autre côté, les sites Web plus petits ou les pages avec des mises à jour peu fréquentes peuvent être explorés moins fréquemment, réduisant ainsi la charge de travail et les ressources requises.
Robot d'exploration Web interne et outils d'exploration Web
Lorsque l'on envisage la création d'un robot d'exploration Web, il est crucial d'évaluer la complexité, l'évolutivité et les ressources nécessaires. Construire un robot d'exploration à partir de zéro peut prendre beaucoup de temps, englobant des activités telles que la gestion de la concurrence, la supervision des systèmes distribués et la résolution des obstacles liés à l'infrastructure. D’un autre côté, opter pour des outils ou des frameworks d’exploration Web peut offrir une résolution plus rapide et plus efficace.
Alternativement, l’utilisation d’outils ou de frameworks d’exploration Web peut fournir une solution plus rapide et plus efficace. Ces outils offrent des fonctionnalités telles que des règles d'exploration personnalisables, des capacités d'extraction de données et des options de stockage de données. En tirant parti des outils existants, les développeurs peuvent se concentrer sur leurs besoins spécifiques, tels que l'analyse des données ou l'intégration avec d'autres systèmes.
Cependant, il est crucial de prendre en compte les limites et les coûts associés à l'utilisation d'outils tiers, tels que les restrictions sur la personnalisation, la propriété des données et les modèles de tarification potentiels.
Conclusion
Les moteurs de recherche s'appuient fortement sur les robots d'exploration Web, qui jouent un rôle déterminant dans la tâche d'organisation et de catalogage des nombreuses informations présentes sur Internet. Comprendre les mécanismes, les composants et les diverses catégories de robots d'exploration Web permet de mieux comprendre la technologie complexe qui sous-tend ce processus fondamental.
Qu'il s'agisse de créer un robot d'exploration Web à partir de zéro ou d'exploiter des outils préexistants pour l'exploration Web, il devient impératif d'adopter une approche adaptée à vos besoins spécifiques. Cela implique de prendre en compte des facteurs tels que l’évolutivité, la complexité et les ressources dont vous disposez. En prenant ces éléments en compte, vous pouvez utiliser efficacement l'exploration du Web pour collecter et analyser des données précieuses, propulsant ainsi votre entreprise ou vos efforts de recherche vers l'avant .
Chez PromptCloud, nous sommes spécialisés dans l'extraction de données Web, en obtenant des données à partir de ressources en ligne accessibles au public. Contactez-nous à sales@promptcloud.com