
Comment sauvegarder vos données Universal Analytics sur BigQuery avec R
Publié: 2023-09-26Universal Analytics (UA) a finalement pris fin et nos données circulent désormais librement dans nos propriétés Google Analytics 4 (GA4). Il peut être tentant de ne plus jamais revoir nos configurations UA, cependant, avant de laisser UA derrière nous, il est important que nous stockions les données qu'il a déjà traitées, si nous devions les analyser à l'avenir. Pour stocker vos données, nous vous recommandons bien sûr BigQuery, le service d'entreposage de données de Google, et dans ce blog nous allons vous montrer quelles données sauvegarder depuis UA, et comment le faire !
Pour télécharger nos données, nous allons utiliser l'API Google Analytics. Nous allons écrire un script qui téléchargera les données nécessaires depuis UA et les téléchargera sur BigQuery, en une seule fois. Pour cette tâche, nous vous recommandons fortement d'utiliser R, car les packages googleAnalyticsR et bigQueryR rendent ce travail très simple, et nous avons écrit notre tutoriel pour R pour cette raison !
Ce guide ne couvrira pas les étapes les plus complexes de configuration de l'authentification, telles que le téléchargement de votre fichier d'informations d'identification. Pour plus d'informations à ce sujet et plus d'informations sur la façon de télécharger des données vers BigQuery, consultez notre blog sur le téléchargement de données vers BigQuery à partir de R et Python !
Sauvegarder vos données UA avec R
Comme d'habitude pour tout script R, la première étape consiste à charger nos bibliothèques. Pour ce script, nous aurons besoin des éléments suivants :
bibliothèque (googleAuthR)
bibliothèque (googleAnalyticsR)
bibliothèque (bigQueryR)
Si vous n'avez jamais utilisé ces bibliothèques auparavant, exécutez install.packages(<PACKAGE NAME>)dans la console pour les installer.
Il nous faudra ensuite faire le tri dans toutes nos différentes autorisations. Pour ce faire, vous devrez exécuter le code suivant et suivre les instructions qui vous sont données :
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = « <votre email ici> »)
ga_id <- <VOTRE GA VOIR ID ICI>
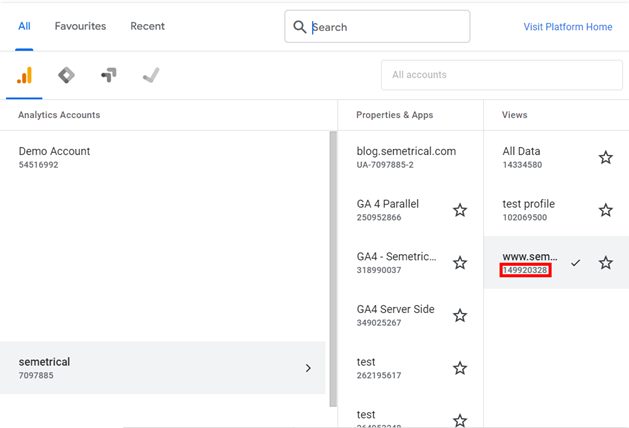
Le ga_id se trouve sous le nom de la vue lorsque vous la sélectionnez dans UA, comme indiqué ci-dessous :
Ensuite, nous devons décider quelles données extraire réellement de l’UA. Nous vous recommandons de tirer ce qui suit :
| Dimensions à l'échelle de la session | Dimensions à l'échelle de l'événement | Dimensions au niveau de la page vue |
| identité du client | identité du client | Chemin de la page |
| Horodatage | Horodatage | Horodatage |
| Source/Support | Catégorie d'événement | Source/Support |
| Catégorie d'appareil | Action d'événement | Catégorie d'appareil |
| Campagne | Étiquette d'événement | Campagne |
| Regroupement de canaux | Source/Support | Regroupement de canaux |
| Campagne |
Les regrouper dans trois tables dans BigQuery devrait suffire à répondre à tous vos futurs besoins potentiels en données UA. Pour extraire ces données de UA, vous devez d’abord spécifier une plage de dates. Accédez à la plateforme UA et consultez l’un de vos rapports pour voir quand la collecte de données a commencé. Ensuite, spécifiez une plage de dates qui s'étend jusqu'au jour précédant l'exécution de votre script, qui est le dernier jour pour lequel vous disposerez de 24 heures complètes de données (et si vous faites cela après que UA ait été coucher du soleil, inclura de toute façon 100 % de vos données disponibles). Notre collecte de données a commencé en mai 2017, j'ai donc écrit :

dates <- c("2017-05-01", Sys.Date()-1)
Nous devons maintenant spécifier ce qui doit être extrait de l’UA selon le tableau ci-dessus. Pour cela, nous devrons exécuter la méthode google_analytics() trois fois, car vous ne pouvez pas interroger ensemble les dimensions de différentes portées. Vous pouvez copier exactement le code suivant :
sessionspull <- google_analytics(ga_id,
date_range = dates,
métriques = c("sessions"),
dimensions = c("clientId", "dateHourMinute",
"sourceMedium", "deviceCategory", "campagne", "channelGrouping"),
anti_sample = VRAI)
eventspull <- google_analytics(ga_id,
date_range = dates,
metrics = c("totalEvents", "eventValue"),
dimensions = c("clientId", "dateHourMinute", "eventCategory", "eventAction", "eventLabel", "sourceMedium", "campaign"),
anti_sample = VRAI)
pvpull <- google_analytics(ga_id,
date_range = dates,
métriques = c("pages vues"),
dimensions = c("pagePath", "dateHourMinute", "sourceMedium", "deviceCategory", "campaign", "channelGrouping"),
anti_sample = VRAI)
Cela devrait soigneusement placer toutes vos données dans trois blocs de données intitulés sessionspull pour les dimensions de la session, eventspull pour les dimensions de l'événement et pvpull pour les dimensions de la page vue.
Nous devons maintenant télécharger les données sur BigQuery, dont le code devrait ressembler à ceci, répété trois fois pour chaque trame de données :
bqr_upload_data("<votre projet>", "<votre ensemble de données>", "<votre table>", <votre dataframe>)
Dans mon cas, cela signifie que mon code se lit comme suit :
bqr_upload_data("mon-projet", "test2", "bloguploadRSess", sessionspull)
bqr_upload_data("mon-projet", "test2", "bloguploadREvent", eventspull)
bqr_upload_data("mon-projet", "test2", "bloguploadRpv", pvpull)
Une fois que tout est écrit, vous pouvez configurer votre script pour qu'il s'exécute, vous asseoir et vous détendre ! Une fois cela fait, vous pourrez vous diriger vers BigQuery et vous devriez voir toutes vos données à leur place !
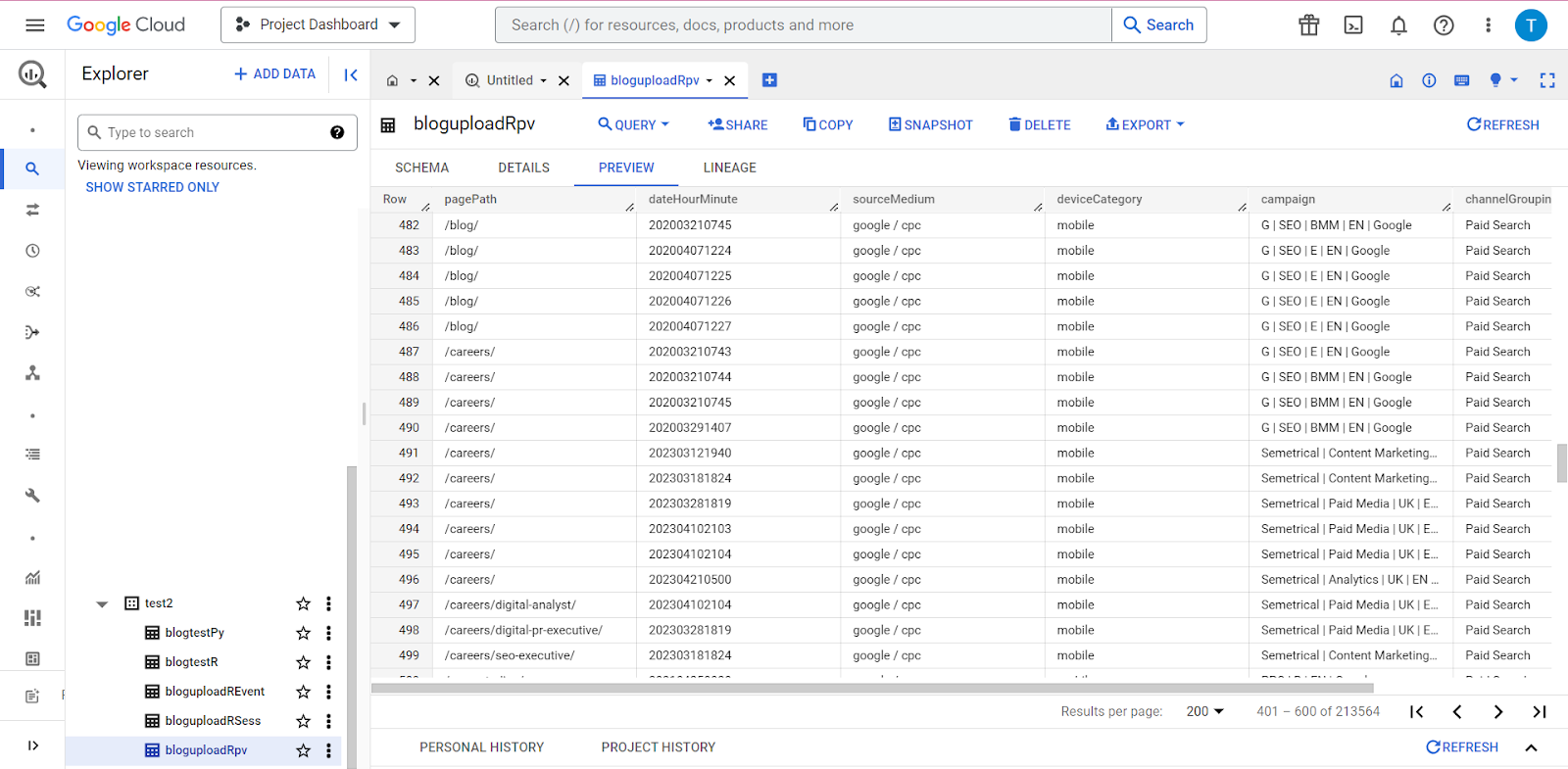
Avec vos données UA conservées en toute sécurité pour les jours de pluie, vous pouvez vous concentrer entièrement sur l'optimisation du potentiel de votre configuration GA4 – et Semetrical est là pour vous aider ! Consultez notre blog pour plus d’informations sur la façon de tirer le meilleur parti de vos données. Ou, pour plus d'assistance sur tout ce qui concerne l'analyse, consultez nos services d'analyse Web pour découvrir comment nous pouvons vous aider.