
Comment empêcher les IA d'explorer votre contenu
Publié: 2023-10-24Les outils génératifs d'IA, comme Google Bard et Bing Chat, sont construits à partir de nombreuses sources de contenu, y compris le Web. À la consternation de beaucoup, les moteurs de recherche ont tranquillement entraîné leurs modèles d’IA sur tout le contenu qu’ils trouvent lors de l’exploration de la recherche Web traditionnelle.
Bing et Google ont annoncé des méthodes permettant d'empêcher l'utilisation de contenus pour la formation en IA tout en restant indexés pour la recherche sur le Web.
Alors, faut-il bloquer les IA, et comment s’y prendre ?
- Faut-il bloquer les IA ?
- Comment bloquer les robots IA ?
- Comment bloquer l'IA de Bing
- Comment bloquer l'IA de Google
- Comment bloquer ChatGPT
- Essai
Faut-il bloquer les IA ?
Les entreprises qui fabriquent leurs propres produits peuvent considérer qu’il est avantageux d’inclure leur contenu dans des modèles d’IA. Les informations, telles que les spécifications techniques ou l'assistance produit, peuvent faciliter les ventes et réduire les coûts d'assistance client.
Mais pour de nombreuses autres entreprises en ligne, le contenu est leur produit. Il existe des craintes légitimes selon lesquelles l’énergie investie dans la création de contenu sera utilisée pour améliorer les produits d’IA appartenant aux grandes entreprises technologiques sans apporter aucune valeur sous forme de trafic.
Google et Bing tentent de trouver des moyens de créditer les sources et de générer du trafic de référence, mais il est probable que celui-ci soit inférieur à celui de la recherche Web traditionnelle et plus susceptible d'être transactionnel que les requêtes de recherche informationnelles.
Il est important de noter que le blocage du contenu de ces IA n'affectera pas le comportement d'exploration. Google indique que « le jeton d'agent utilisateur robots.txt est utilisé à des fins de contrôle ». Votre site sera exploré normalement par les robots pour créer leurs index de recherche.
Et si les moteurs de recherche ne peuvent déjà pas explorer certaines pages, vous n’avez pas besoin de les bloquer spécifiquement pour les IA.
Comment bloquer les robots IA ?
Il est actuellement possible de bloquer Google, Bing et ChatGPT en utilisant des méthodes familières à la plupart des référenceurs, le fichier robots.txt et les directives robots au niveau de la page.
Google et ChatGPT ont opté pour la méthode robots.txt qui permet de spécifier des modèles d'URL, et Bing a opté pour l'utilisation de directives robots appliquées à des pages individuelles.
Le robots.txt a l’avantage d’être facile à configurer pour l’ensemble d’un site web en un seul endroit. Il est très transparent quelles URL sont bloquées par rapport aux directives des robots au niveau de la page, qui doivent être testées en récupérant chaque page.
Comment bloquer l'IA de Bing
Bing recherche les directives robots nocache ou noarchive, qui peuvent être ajoutées à une page en tant que balise méta ou dans un en-tête de réponse X-Robots-Tag.
Nocache permettra d'inclure des pages dans les réponses Bing Chat en utilisant uniquement des URL, des titres et des extraits de code lors de la formation des modèles d'IA de Microsoft.
Noarchive ne permet pas d'inclure des pages dans Bing Chat et aucun contenu ne sera utilisé pour entraîner les modèles d'IA de Microsoft.
Si une page contient à la fois Nocache et Noarchive, le Nocache le moins restrictif aura la priorité.
Le jeton ' robots ' appliquera la directive à tous les robots. Cela inclut Google qui empêchera la page d'apparaître avec un lien en cache dans les résultats de recherche.
<meta name="robots" content="noarchive">
Vous pouvez utiliser les jetons « bingbot » ou « msnbot » plus spécifiques pour éviter d'affecter les autres moteurs de recherche.
<meta name=”bingbot” content=”nocache”>
Comment bloquer l'IA de Google
Google a opté pour la méthode robots.txt qui vous permet de spécifier des modèles d'URL correspondant aux pages que vous ne souhaitez pas utiliser dans Bard et leur équivalent Vertex API. Cela ne s’applique actuellement pas à la Search Generative Experience (SGE).
Ils correspondront à un jeton d'agent utilisateur de Google étendu. La casse du jeton n'a pas d'importance.
Agent utilisateur : Google Extended
Interdire : /
S'il n'existe pas de bloc de règles spécifiquement pour le jeton étendu de Google, il correspondra au jeton générique (*).

Agent utilisateur: *
Interdire : /
Soyez prudent si vous disposez d'un bloc de règles spécifique pour Googlebot et d'un bloc de caractères génériques distinct. Google-extended correspondra au bloc générique, pas au bloc Googlebot.
Agent utilisateur : Googlebot
Permettre: /
Agent utilisateur: *
Interdire : /
Vous pouvez lister plusieurs agents utilisateurs avant les blocs de règles pour être plus précis.
Agent utilisateur : Google Extended
Agent utilisateur : Googlebot
Permettre: /
Agent utilisateur: *
Interdire : /
Comment bloquer ChatGPT
ChatGPT a également opté pour la méthode robots.txt.
Chat GPT dispose de deux jetons d'agent utilisateur différents, ChatGPT-User pour les requêtes au nom des utilisateurs de ChatGPT et GPTBot, qui est le robot d'exploration Web d'OpenAI utilisé pour créer leurs modèles.
Le système de désinscription traite actuellement les deux agents utilisateurs de la même manière, donc toute interdiction de fichier robots.txt pour un agent couvrira les deux. Cela pourrait changer à l'avenir, nous vous recommandons donc de les bloquer séparément.
Agent utilisateur : GPTBot
Agent utilisateur : ChatGPT-Utilisateur
Interdire : /
Essai
Les tests sont simples si vous bloquez l’intégralité de votre site Web.
Pour vérifier si Google et ChatGPT sont bloqués, vous devez voir si votre robots.txt a une règle de tout interdire pour les robots que vous souhaitez bloquer.
Agent utilisateur : Google Extended
Agent utilisateur : GPTbot
Interdire : /
Si vous souhaitez uniquement bloquer certaines URL, cela peut nécessiter un ensemble plus complexe de directives robots.txt. Vous pouvez envisager de tester un certain nombre d'URL qui, selon vous, seront bloquées et non bloquées.
Tomo est notre outil robots.txt gratuit qui peut vous aider à tester si des URL spécifiques sont bloquées dans robots.txt. Vous pouvez définir des tests sous la forme d'une liste d'URL et le statut non autorisé attendu pour chaque URL.
Il peut être configuré avec les jetons d'agent utilisateur Google-Extended, GPTBot et ChatGPT-User pour vous montrer quelles URL sont bloquées pour chacune et si cela correspond au résultat du test attendu.
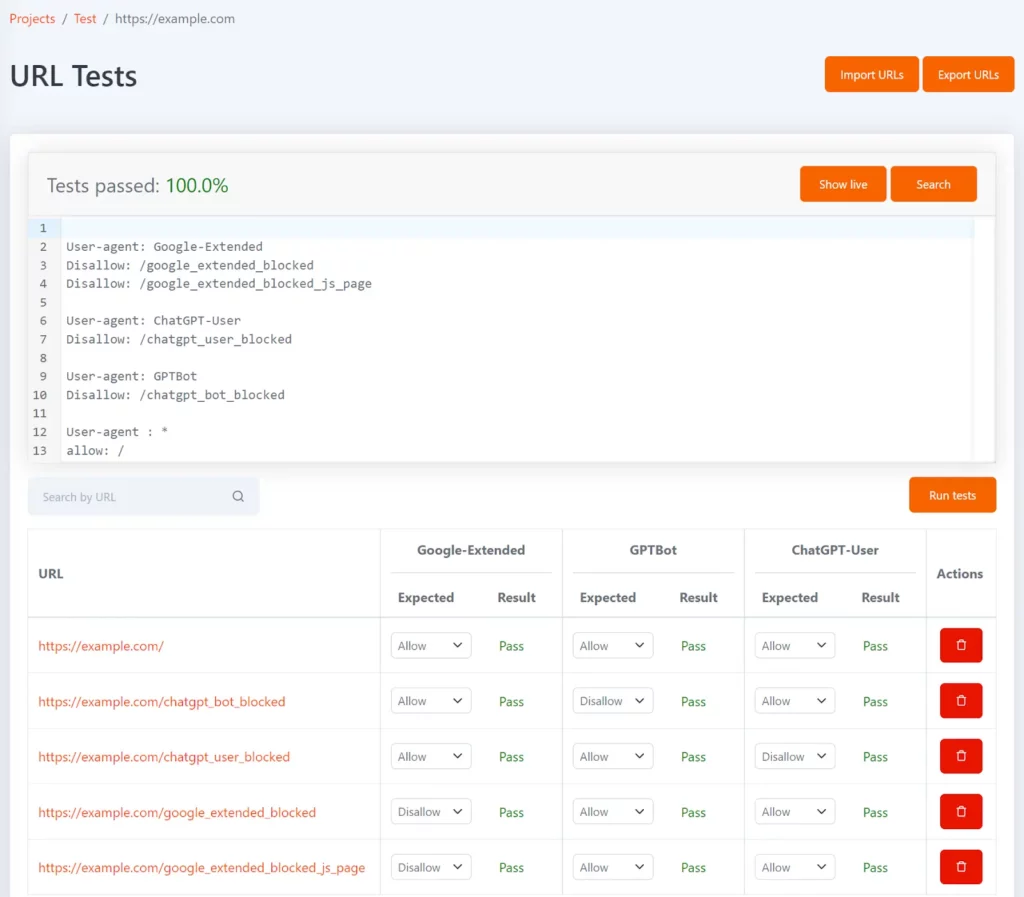
Chaque fois que votre fichier robots.txt est mis à jour, les tests seront réexécutés et vous serez averti si les résultats ne correspondent pas à ceux attendus.
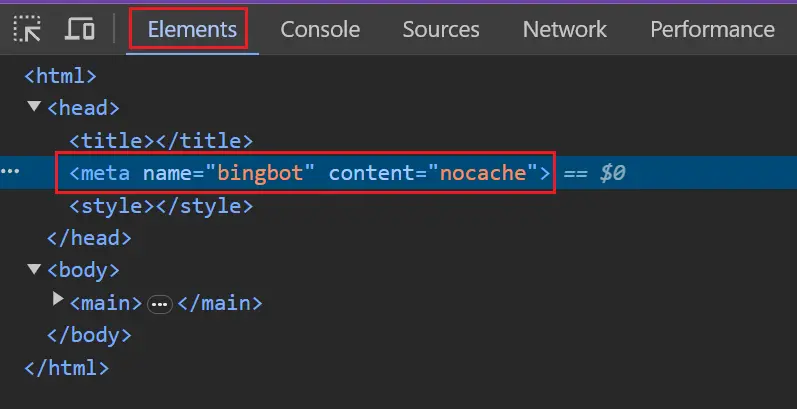
Pour tester si Bing est bloqué, vous pouvez inspecter vos modèles de pages clés dans le navigateur et confirmer qu'ils contiennent la balise robots.
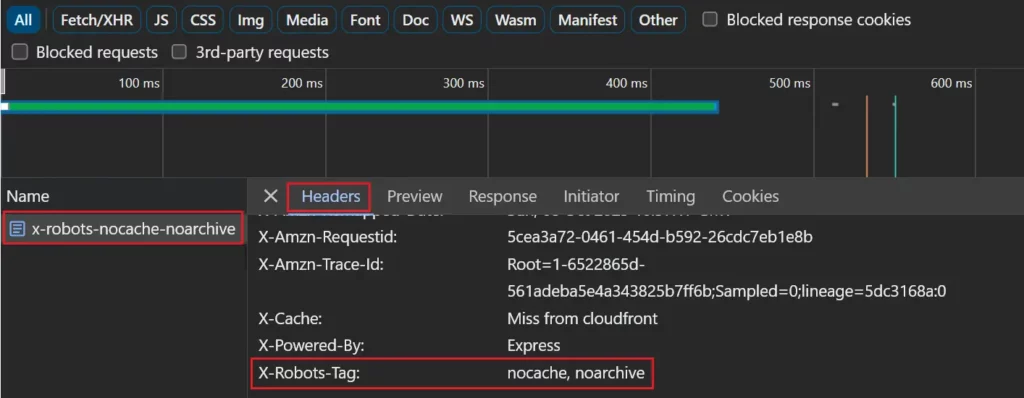
Si vous utilisez un en-tête de réponse X-Robots-Tag, il peut être vu dans l'onglet réseau en sélectionnant la page dans la liste des requêtes réseau et en affichant l'onglet « En-têtes ».
Les tests seront plus compliqués si vous bloquez un ensemble spécifique de pages, mais certains outils peuvent vous aider.
Le robot d'exploration Lumar signalera également désormais automatiquement toutes les pages sur lesquelles les IA de Google et Bing sont bloquées.
Avez-vous besoin d'une assistance technique supplémentaire ? Apprenez-en plus sur l’offre technologique de Semetrical ou contactez-nous pour plus d’informations !