
ETL inversé : prise de décision basée sur les données à chaque étape
Publié: 2022-09-29ETL, ou Extract, Transform, Load, est un processus de pipeline d'analyse de données qui comprend trois étapes de sourçage, de nettoyage et de chargement de données dans un référentiel accessible et opérationnel.
Cependant, que se passerait-il si vous pouviez inverser l'ETL ? Autrement dit, la prise de décision à chaque étape du processus en utilisant les données collectées à la source.
Bien qu'il y ait toujours des irrégularités et des vulnérabilités dans votre architecture de données, l'ETL inversé est le meilleur moyen de s'assurer que tout le monde travaille à partir des mêmes informations et que les chiffres des rapports sont exacts et prédisent plus précisément les performances de l'entreprise.
Ce guide vous aidera à comprendre l'ETL inversé, pourquoi il est utile et les cas d'utilisation quotidiens.
Points clés à retenir
- L'ETL inversé vous permet d'automatiser le processus d'obtention de données propres et prêtes à l'emploi de vos systèmes sources vers des outils d'analyse et de BI en aval.
- Utilisez l'ETL inversé pour améliorer l'efficacité, la flexibilité, la visibilité et la cohérence tout en opérationnalisant vos données.
- Tirez parti des outils ETL inversés dédiés et éloignez-vous des solutions personnalisées peu fiables (et coûteuses) ou de l'automatisation point à point épuisante.
Qu'est-ce que l'ETL inversé ?
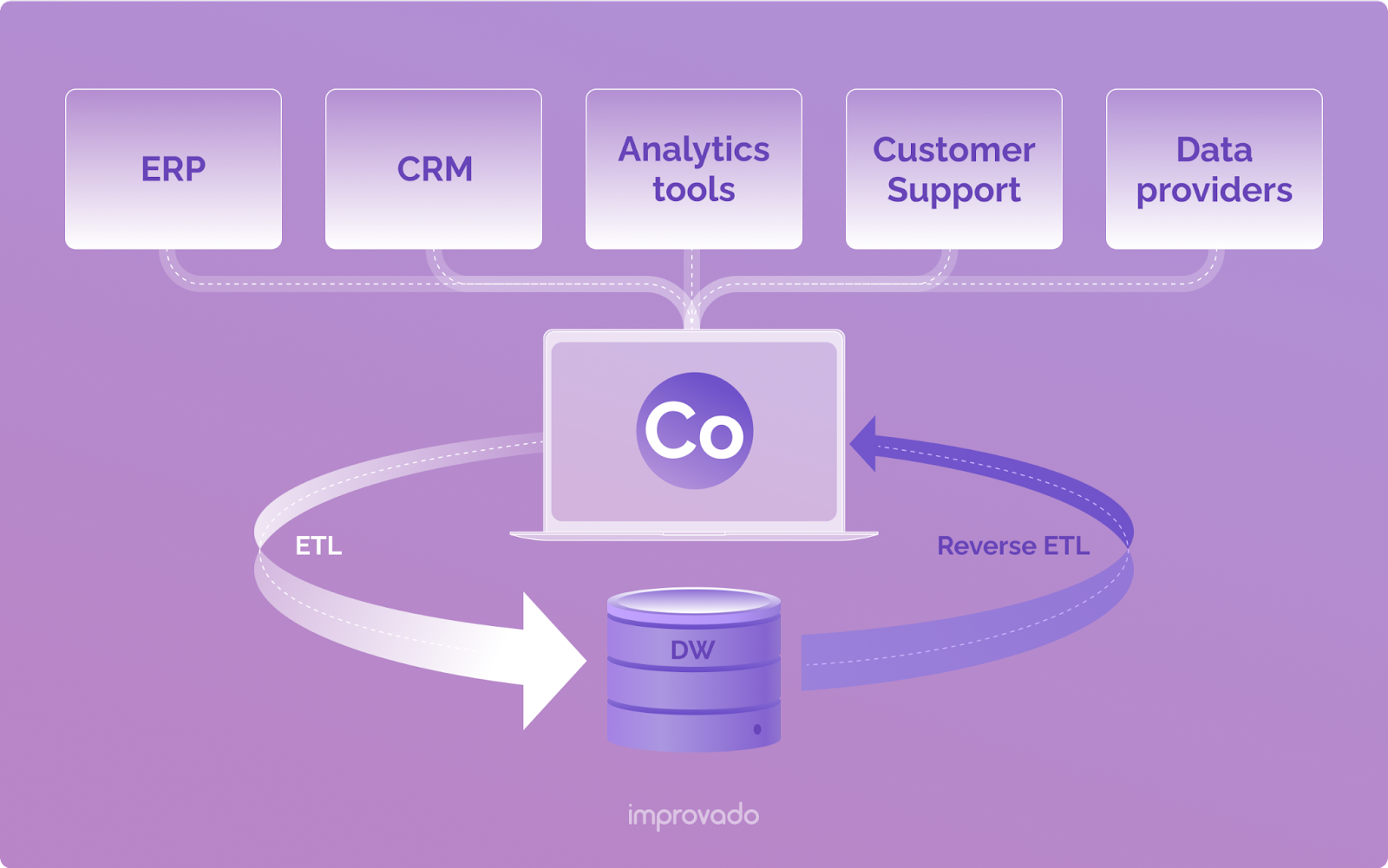
L'ETL inversé est la pratique consistant à synchroniser les données d'une source de vérité, généralement un entrepôt de données ou un lac de données, directement vers différentes applications commerciales telles que les CRM, les plateformes publicitaires, les ERP et bien d'autres.
Pour mieux comprendre le concept, voici un rappel rapide sur les systèmes ETL et ELT et en quoi l'ETL inversé est différent.
ETL, ELT et ETL inverse sont tous des pipelines de données. Ils déplacent les données du système A vers le système B tout en appliquant des transformations aux données en cours de route. "E" est pour "extraire", "T" est pour "transformer" et "L" est pour "charger". Spécifiquement:
- L'ETL consiste à extraire des données d'une ou plusieurs sources et à les transformer dans un format pouvant être chargé dans un système cible.
- ELT est un processus similaire qui inverse l'ordre des étapes de transformation et de chargement. Les données sont d'abord chargées dans le système cible, puis transformées pour répondre aux exigences de ce système.
- Reverse ETL inverse l'ordre des étapes d'extraction et de chargement. Les données sont extraites du système source et chargées directement dans le système cible sans être transformées.
L'ETL inversé élimine le besoin d'une étape de transformation intermédiaire, ce qui peut économiser du temps et des ressources. Cependant, cela signifie également que les données peuvent ne pas être compatibles avec le système cible et peuvent nécessiter un traitement supplémentaire avant de pouvoir les utiliser.
Par conséquent, l'ETL inversé prospère dans les situations où les systèmes source et cible sont très similaires ou lorsqu'il n'est pas nécessaire de transformer les données.
Avantages de l'intégration de l'ETL inverse
Les outils ETL inversés utilisent ce que l'on appelle une approche en étoile. Cela signifie que vous pouvez utiliser votre entrepôt de données pour toutes les connexions sortantes. Vos outils métier peuvent extraire des données de la même source sous-jacente fiable, évitant ainsi les différences potentielles entre les nombreuses intégrations point à point.
Voici quelques avantages de l'ETL inversé :
- Opérationnaliser les données : faire apparaître des données sur chaque "rayon" de votre pile technologique permet à votre équipe de prendre des informations abstraites et de les transformer en quelque chose de concret et mesurable.
- Cohérence des données : en ingérant des données à partir d'une source unifiée, vous pouvez être sûr que tout le monde travaille à partir des mêmes informations. L'accessibilité aux données centralisées est cruciale pour les équipes commerciales et marketing qui ont besoin de rapports précis pour prévoir les performances de l'entreprise.
- Efficacité améliorée : une mise en œuvre appropriée de l'ETL inversé vous fera gagner du temps et des ressources en éliminant le besoin d'une étape de transformation intermédiaire, en particulier pour votre équipe de données. Toutes les connexions API s'intègrent à l'entrepôt, vous n'avez donc pas à vous soucier de la création ou de la maintenance d'un code personnalisé en interne. Ainsi, l'ETL inversé permet à votre équipe de données de se concentrer sur un travail de grande valeur.
- Une plus grande flexibilité : Avec l'ETL inversé, vous pouvez choisir les données à synchroniser et quand, ce qui vous permet d'ajouter ou de supprimer facilement des applications de votre processus ETL inversé selon vos besoins.
- Visibilité accrue : Reverse ETL vous fournit une image complète de votre flux de données, ce qui vous permet de repérer facilement les erreurs potentielles ou les domaines à améliorer.
- Cohérence des outils : En envoyant les données transformées directement aux applications métier, les utilisateurs peuvent rester dans leur outil natif, qu'ils sont plus à l'aise d'utiliser qu'un outil de BI.

Cas d'utilisation ETL inversés
Maintenant que nous avons passé en revue les avantages de l'ETL inversé, examinons quelques cas d'utilisation spécifiques où ce cadre est efficace.
Téléchargement des données clients dans un CRM
Dans ce scénario, vous extrayez des données de vos systèmes internes, par exemple, votre outil ERP, financier ou de gestion des commandes.
Ces données sont ensuite chargées dans le système CRM afin que les équipes de vente et de marketing puissent accéder aux informations client dans un emplacement central. Vous n'avez pas besoin de transformer les données car elles sont déjà dans un format compatible.
Synchronisation des données entre deux systèmes similaires
Ce cas d'utilisation est similaire à celui ci-dessus, mais les deux systèmes ne sont pas nécessairement compatibles. Vous devrez peut-être transformer les données dans le système cible avant de les charger. Par exemple, vous devrez peut-être convertir des données du format CSV au format JSON.
Migration des données vers un nouveau système
Vous pouvez passer d'un entrepôt de données sur site à une solution basée sur le cloud ou changer de système CRM. Dans tous les cas, vous pouvez mettre en place un transfert ETL inverse vers les données.
Cette intégration éviterait d'avoir à transférer des données manuellement ou à écrire des scripts personnalisés. Notez que vous devrez peut-être transformer les données pour répondre aux exigences du nouveau système.
Création d'une sauvegarde
La gestion des sauvegardes est un cas d'utilisation quotidien pour l'ETL inversé. Les données sont extraites du système source et chargées dans un système de sauvegarde. Vous n'avez pas besoin de transformer les données car elles ne sont requises que pour la sauvegarde.
Comment l'ETL inversé s'adapte à la pile de données moderne
Les applications d'opérationnalisation de vos données à l'aide de l'ETL inverse sont infinies. Examinons trois exemples d'utilisation de l'ETL inversé dans votre pile de données.

Synchronisez les données avec le CRM pour votre équipe de vente
Les outils CRM tels que Salesforce proposent de très bonnes solutions de reporting prêtes à l'emploi et sont généralement là où votre équipe de vente passera le plus clair de son temps.
Vous allez toujours extraire et charger les données Salesforce brutes dans votre entrepôt, en les combinant avec d'autres données d'entreprise pour créer des métriques personnalisées dans votre pipeline ETL/ELT habituel.
Mais vous pouvez utiliser votre outil ETL inversé pour synchroniser ces nouvelles données et mesures personnalisées de votre entrepôt vers votre CRM pour votre équipe de vente.
Votre équipe de vente utilise toujours la logique d'entrepôt partagé, mais n'a pas besoin d'accéder à un outil de création de rapports distinct pour la voir. Et ils n'ont pas besoin de créer des rapports personnalisés pour déterminer ce dont ils ont besoin.
Utiliser les données client pour les campagnes marketing
Votre équipe marketing souhaite créer une liste segmentée de clients à partir de votre entrepôt de données pour une nouvelle campagne marketing. Plutôt que d'écrire une requête et d'exporter les données, ils peuvent utiliser l'ETL inversé pour envoyer automatiquement les données de votre entrepôt vers une feuille de calcul Google, une feuille de calcul ou quelque chose de similaire.
L'équipe marketing peut ensuite utiliser les données selon ses besoins et n'a pas à compter sur l'équipe d'ingénierie pour obtenir les données pour elle.
Améliorez le support client grâce aux données
Le support client utilise une combinaison de Slack et Zendesk pour gérer les tickets clients. Et si vous pouviez utiliser les données de votre entrepôt pour acheminer automatiquement les tickets vers le bon agent d'assistance ?
Vous pouvez utiliser l'ETL inversé pour surveiller vos données pour des occurrences spécifiques, puis prendre des mesures en conséquence. Dans ce cas, vous enverriez un message à Slack qui inclurait les détails du ticket et l'attribuerait au bon agent d'assistance.
De cette façon, votre équipe de support client peut se concentrer sur la résolution des tickets plutôt que sur leur routage. Et vous pouvez être sûr que le bon billet va à la bonne personne.
Il n'y a pas de limite à ce que vous pouvez faire avec l'ETL inversé. La clé est de comprendre comment l'utiliser pour former un pipeline de données complet.
Build vs. Buy : quelle solution ETL inverse choisir ?
Bien que le concept d'ETL inversé ne soit pas nouveau, jusqu'à récemment, aucun outil n'était disponible pour aider à la mise en œuvre. Cela a changé avec l'avènement des entrepôts de données basés sur le cloud.
Auparavant, vous deviez créer une application personnalisée pour synchroniser les données entre les canaux. Une telle entreprise impliquerait d'être responsable de la connexion et de la gestion des API et de la conception des interfaces. Plus important encore, vous devez maintenir à la fois le produit et le code.
Le problème avec cette approche est qu'un ou deux ingénieurs doivent être disponibles en cas de problème.
Une autre approche consiste à imiter les données d'un autre outil de BI dans un tableau de bord ; cependant, il est difficile de faire correspondre les nombres avec précision en utilisant cette méthode.
Vous pouvez également essayer d'utiliser des outils d'automatisation comme Zapier ou Make. Ces outils peuvent être efficaces pour les petites charges de travail, par exemple si vous souhaitez créer un déclencheur ponctuel. Cependant, le nombre de ces synchronisations augmentera rapidement en fonction de vos besoins, rendant l'automatisation impraticable pour autre chose que leur utilisation prévue.
C'est là qu'intervient un outil ETL inversé : il offre un moyen de gérer la synchronisation des données sans avoir besoin de code personnalisé ni faire appel à des ingénieurs.
En limitant la dépendance vis-à-vis d'autres services, vous pouvez être opérationnel plus rapidement qu'avec une solution sur mesure. Il est également plus facile à utiliser et à entretenir, car le fournisseur fournira une assistance et des mises à jour.
Plus important encore, l'envoi de données transformées directement aux applications métier signifie que votre équipe peut continuer à utiliser des logiciels qu'elle connaît au lieu de traiter avec une interface d'outil de BI souvent écrasante.
Reverse ETL est une solution évolutive qui peut évoluer avec vos besoins tout en restant maintenable. En tant que tel, il devient rapidement la solution incontournable pour gérer les données sur tous les canaux.
Prochaines étapes pour implémenter votre modèle ETL inversé
Pour prendre des décisions basées sur les données, vous avez besoin des données correctes dans le bon format au bon moment, et l'ETL inversé coche la plupart des cases.
En intégrant un système ETL inversé, vous pouvez automatiser le processus d'obtention de données propres et prêtes à l'emploi de vos systèmes sources vers des outils d'analyse et de BI en aval. En conséquence, vous serez en mesure d'améliorer la prise de décision et d'obtenir plus d'informations à partir de vos données plus rapidement que jamais.
Si vous recherchez une solution ETL inversée qui répond à vos besoins uniques, notre équipe d'Improvado est là pour vous aider. Nous vous aiderons à créer un modèle et vous aiderons à prendre de meilleures décisions basées sur les données aujourd'hui.