
Jarvis Rising - Comment Google pourrait générer un modèle d'apprentissage automatique "à la volée" pour prédire les réponses lorsque la recherche ne le peut pas, et comment il pourrait indexer ces modèles pour prédire les réponses aux future
Publié: 2023-07-13
Après avoir analysé un brevet Google lié à PAA et PASF, j'ai commencé à examiner d'autres brevets récemment accordés. Et il n'a pas fallu longtemps avant que j'en découvre une autre très intéressante concernant l'utilisation des modèles d'apprentissage automatique. Le brevet que je viens d'analyser porte sur l'utilisation et/ou la génération d'un modèle d'apprentissage automatique en réponse à une requête (lorsque Google doit prédire une réponse car les résultats de recherche standard ne peuvent pas fournir de réponse adéquate). Après avoir lu le brevet à plusieurs reprises, il a souligné à quel point les systèmes de Google pouvaient être sophistiqués lorsqu'ils devaient fournir une réponse (ou une prédiction) de qualité aux utilisateurs.
Comme pour tout brevet, nous ne savons jamais si Google a réellement mis en œuvre ce que le brevet couvre, mais c'est toujours possible. Et s'il était mis en œuvre, non seulement Google pourrait utiliser un modèle d'apprentissage automatique formé pour aider à prédire une réponse à une requête, mais il peut indexer ces modèles d'apprentissage automatique, les associer à diverses entités, pages Web, etc., puis récupérer et utiliser ces modèles pour les recherches connexes ultérieures. Pensez à la puissance et à l'évolutivité que cela peut être pour Google.
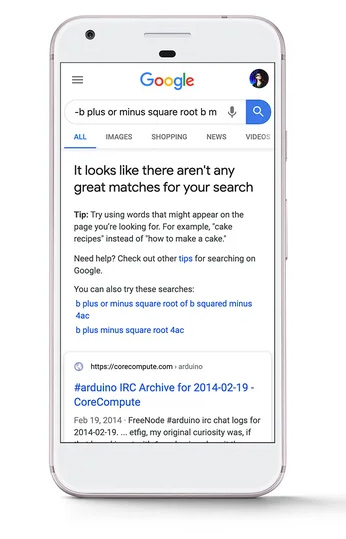
De plus, le brevet explique que Google peut renvoyer une interface interactive au modèle d'apprentissage automatique dans les résultats de la recherche, ce qui permet aux utilisateurs d'ajouter des paramètres pouvant être utilisés pour générer une prédiction pour les requêtes lorsque les résultats de la recherche ne sont pas suffisants. Cette partie du brevet m'a fait penser au message que Google a déployé dans les SERP en avril 2020 lorsqu'aucun résultat de recherche de qualité n'est renvoyé pour une requête. L'implémentation actuelle ne fournit pas de formulaire avec lequel les utilisateurs peuvent interagir, mais cela pourrait certainement arriver à un moment donné. Et peut-être que cette interface pourrait être utilisée pour plus de requêtes à l'avenir par rapport aux plus obscures qu'elle fait apparaître pour le moment. Je couvrirai plus à ce sujet dans les puces ci-dessous.
Points clés du brevet :
Semblable à mon dernier article sur un récent brevet de Google, je pense que la meilleure façon de couvrir les détails est de fournir des puces des points clés.
Génération et/ou utilisation d'un modèle d'apprentissage automatique en réponse à une requête de recherche
États-Unis 11645277 B2
Date d'octroi : 9 mai 2023
Date de dépôt : 12 décembre 2017
Nom du cessionnaire : Google LLC
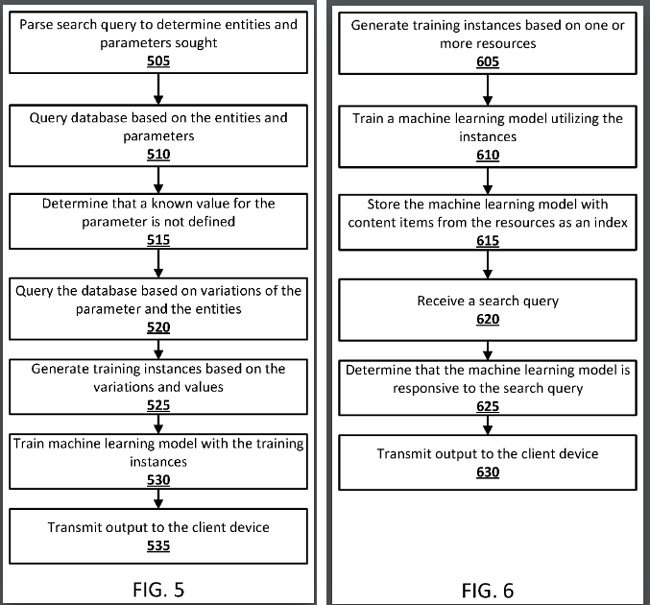
1. Le brevet de Google explique que si une réponse ne peut pas être localisée avec certitude et que l'utilisateur soumet une demande de nature prédictive, un modèle d'apprentissage automatique formé peut être utilisé pour générer une prédiction.
2. Par exemple, Google pourrait d'abord générer des résultats de recherche basés sur une requête, mais si les résultats ne sont pas de qualité suffisante, un modèle d'apprentissage automatique peut être utilisé pour fournir une réponse prédite plus forte. Ainsi, le système peut fournir des réponses prédites basées sur un modèle d'apprentissage automatique lorsqu'une réponse ne peut pas être validée par Google.

3. En outre, le modèle d'apprentissage automatique peut être généré "à la volée", et Google peut stocker des modèles d'apprentissage automatique formés dans un index de recherche. Oui, Google pourrait indexer des modèles d'apprentissage automatique qui viennent d'être formés pour fournir des prédictions basées sur des types de requêtes spécifiques. Je couvrirai plus à ce sujet bientôt.

4. Le brevet fournissait un exemple basé sur la question « Combien de médecins y aura-t-il en Chine en 2050 ? » Si une réponse faisant autorité ne peut pas être fournie via les résultats de recherche standard, la requête peut être transmise à un modèle d'apprentissage automatique formé pour générer une prédiction.

5. Le brevet poursuit en expliquant que le système pourrait prendre d'autres années comme 2010, 2015, 2020, etc. et les utiliser pour générer une prédiction (via un modèle d'apprentissage automatique formé sur ces paramètres).
6. Le brevet explique que les modèles d'apprentissage automatique formés peuvent être indexés par un ou plusieurs éléments de contenu à partir de "ressources utilisées pour former le modèle". Et pour les requêtes futures, lorsque le système identifie des paramètres liés à un modèle d'apprentissage automatique (par exemple, si un utilisateur ultérieur pose une question connexe telle que "Combien de médecins y a-t-il en Chine en 2040 ?"), le modèle d'apprentissage automatique pourrait être utilisé pour générer une prédiction.


7. Le brevet poursuit en expliquant que les modèles d'apprentissage automatique pourraient être stockés avec un ou plusieurs éléments de contenu, comme des entités dans un graphe de connaissances, des noms de table, des noms de colonne, des noms de page Web, etc. De plus, des mots associés à la requête tels que "Chine" et "médecins" pourraient être utilisés par le modèle d'apprentissage automatique pour générer une prédiction.
8. Le brevet poursuit en expliquant que le système pourrait fournir une interface interactive permettant aux utilisateurs de sélectionner des paramètres pouvant être transmis au modèle d'apprentissage automatique. Cela peut être un champ de texte, un menu déroulant, etc. De plus, la réponse peut inclure un message présenté à l'utilisateur indiquant que la réponse est une prédiction basée sur un modèle d'apprentissage automatique entraîné. Google veut donc s'assurer que les utilisateurs comprennent qu'il s'agit d'une prédiction basée sur un modèle d'apprentissage automatique par rapport aux réponses fournies sur la base des données qu'il a indexées.

9. Le modèle formé peut ensuite être validé pour s'assurer que les prédictions sont d'au moins une "qualité seuil". Tout ce qui est en dessous d'un certain seuil peut être supprimé et non fourni à l'utilisateur. Dans ce cas, les résultats de la recherche standard peuvent être affichés à la place.

10. Au-delà des résultats de recherche publics, le brevet explique que le système pourrait être utilisé sur une base de données privée pour aider les entreprises à prédire certains résultats. Le brevet explique, "privé à un groupe d'utilisateurs, une société et/ou d'autres ensembles restreints". Par exemple, un employé d'un parc d'attractions pourrait demander : "combien de cônes de neige vendrons-nous demain ?" Le système pourrait alors interroger une base de données privée pour comprendre les ventes des jours précédents, les informations météorologiques, les données de présence, etc., afin de prédire une réponse pour l'employé.
11. Le brevet explique que le système pourrait fournir des notifications push à partir d'un "assistant automatisé" à un moment donné. Et juste en pensant à haute voix, je me demande si cela pourrait provenir d'un assistant de type Jarvis, comme je l'ai expliqué dans mon article sur le Code Red de Google qui a déclenché des milliers de Code Reds chez les éditeurs.

12. Du point de vue de la latence, le brevet explique qu'il peut y avoir un délai après qu'un utilisateur a soumis une requête. Lorsque cela se produit, les résultats de recherche standard peuvent être initialement affichés avec un message indiquant que les « bons » résultats ne sont pas disponibles pour la requête et qu'un modèle d'apprentissage automatique est utilisé pour générer une prédiction. Dans ces situations, le système peut pousser cette prédiction à l'utilisateur ultérieurement ou fournir un lien hypertexte sur lequel les utilisateurs peuvent cliquer pour afficher la sortie d'apprentissage automatique.
13. En outre, le brevet indique que dans certaines situations, l'utilisateur devrait confirmer l'invite pour que le processus se poursuive. Par exemple, le système peut fournir un message indiquant : « Une bonne réponse n'est pas disponible. Voulez-vous que je prédise une réponse pour vous ? » Ensuite, le modèle d'apprentissage automatique ne serait formé que si une entrée utilisateur affirmative est reçue en réponse à l'invite. Comme je l'ai expliqué plus tôt, je vois un lien avec le message "Il n'y a pas de bonnes correspondances pour votre recherche" qui s'est déroulé en avril 2020. Je me demande si cela pourrait s'étendre pour utiliser ce modèle à l'avenir…

Résumé : Google pourrait prédire des réponses de qualité de manière puissante et extrêmement efficace via des modèles d'apprentissage automatique (indexés).
Bien que nous ne sachions pas si un brevet spécifique est utilisé, la puissance et l'efficacité de ce processus ont beaucoup de sens pour Google. De la génération de modèles d'apprentissage automatique "à la volée" à l'indexation de ces modèles pour une utilisation future en passant par l'utilisation d'une interface interactive avec des notifications push, Google semble préparer le terrain pour un assistant comme Jarvis. Alors, la prochaine fois que vous demanderez à Google de prédire une réponse, pensez à ce brevet. Et vous pourriez être invité à fournir plus d'informations à un moment donné (jusqu'à ce que Jarvis puisse faire tout cela en une nanoseconde). :)
GG