
Mise à l'échelle des opérations de grattage de données : conseils d'experts pour gérer de gros volumes de données
Publié: 2024-05-25À mesure que la demande de données augmente, les défis associés à la mise à l’échelle des opérations de récupération de données augmentent également. Le web scraping à grande échelle ne consiste pas seulement à augmenter la quantité de données collectées ; il s'agit de maintenir la qualité, d'assurer l'efficacité et de surmonter les obstacles techniques et juridiques.
Imaginez une entreprise de vente au détail commençant par une modeste opération de récupération de données, collectant des informations sur les prix et les produits sur quelques sites Web concurrents. Au départ, cette configuration fonctionne sans problème, fournissant des informations précieuses pour la prise de décision stratégique. Cependant, à mesure que l’entreprise se développe et commence à cibler un marché plus large, le besoin d’un web scraping à grande échelle sur des centaines, voire des milliers de sites Web devient évident. L'infrastructure initiale, qui était adaptée aux opérations à petite échelle, se débat désormais face à une charge accrue, ce qui entraîne un ralentissement des performances et des inexactitudes potentielles des données.
De plus, la gestion de sources Web diverses et dynamiques ajoute un autre niveau de complexité. Les sites Web mettent souvent à jour leurs structures, mettent en œuvre des mesures anti-scraping ou nécessitent l'extraction de données à partir de contenus complexes rendus en JavaScript. Ces défis nécessitent des solutions robustes et adaptables qui peuvent évoluer de manière transparente sans compromettre la qualité ou la légalité des données.
Le web scraping à grande échelle ne consiste pas seulement à traiter davantage de données, mais à le faire de manière efficace, fiable et conforme aux normes légales. Cela implique de choisir les bons outils et technologies, de construire une infrastructure robuste et de mettre en œuvre des pipelines de traitement de données efficaces. Comprendre les défis du web scraping à grande échelle et développer des stratégies pour les surmonter est essentiel pour les entreprises qui cherchent à exploiter tout le potentiel du data scraping.
#1 : Choisir les bons outils et technologies
La sélection des outils et technologies appropriés est la base des opérations de web scraping à grande échelle. Les frameworks de scraping avancés tels que Scrapy, Beautiful Soup et Selenium offrent des fonctionnalités robustes capables de gérer des tâches de scraping complexes. Ces outils sont excellents pour les projets plus petits et plus faciles à gérer, mais à mesure que l'ampleur et la complexité des opérations de récupération de données augmentent, des solutions plus puissantes et plus flexibles sont nécessaires.
C’est là qu’interviennent les fournisseurs de services de web scraping comme PromptCloud. PromptCloud propose une solution complète d'extraction de données de bout en bout conçue pour s'adapter de manière transparente aux besoins de l'entreprise. Contrairement aux outils traditionnels, PromptCloud fournit un service entièrement géré qui s'occupe de tout, de la configuration de l'infrastructure de scraping à la livraison des données.
#2 : Construire une infrastructure robuste
Une infrastructure robuste est cruciale pour prendre en charge les opérations de web scraping à grande échelle. Cela inclut des serveurs puissants, de nombreuses solutions de stockage et des connexions Internet haut débit. L'exploitation de services d'infrastructure cloud tels qu'Amazon Web Services (AWS), Google Cloud Platform (GCP) ou Microsoft Azure garantit l'évolutivité et la fiabilité, permettant aux entreprises d'adapter leurs opérations selon leurs besoins.

La configuration et la gestion de votre propre infrastructure peuvent être complexes et gourmandes en ressources. PromptCloud propose une solution rationalisée qui élimine ces défis. En fournissant un service de récupération de données entièrement géré, PromptCloud prend en charge les exigences d'infrastructure, garantissant ainsi le bon déroulement et l'efficacité de vos opérations.
#3 : Garantir la qualité et l’exactitude des données à grande échelle
Maintenir la qualité et l’exactitude des données constitue un défi important lorsqu’il s’agit de grands ensembles de données. À mesure que le volume de données augmente, le risque d’erreurs et d’incohérences augmente, ce qui rend crucial la mise en œuvre de procédures robustes de validation et de nettoyage des données. S'assurer que les données collectées sont fiables et utilisables est essentiel pour prendre des décisions commerciales éclairées et maintenir l'intégrité de vos analyses.
Les sites Web modifient fréquemment leur structure, ce qui peut perturber les opérations de récupération de données et conduire à des inexactitudes. Un suivi et une mise à jour réguliers de vos scripts de scraping sont essentiels pour s'adapter à ces changements et garantir l'exactitude continue des données collectées.
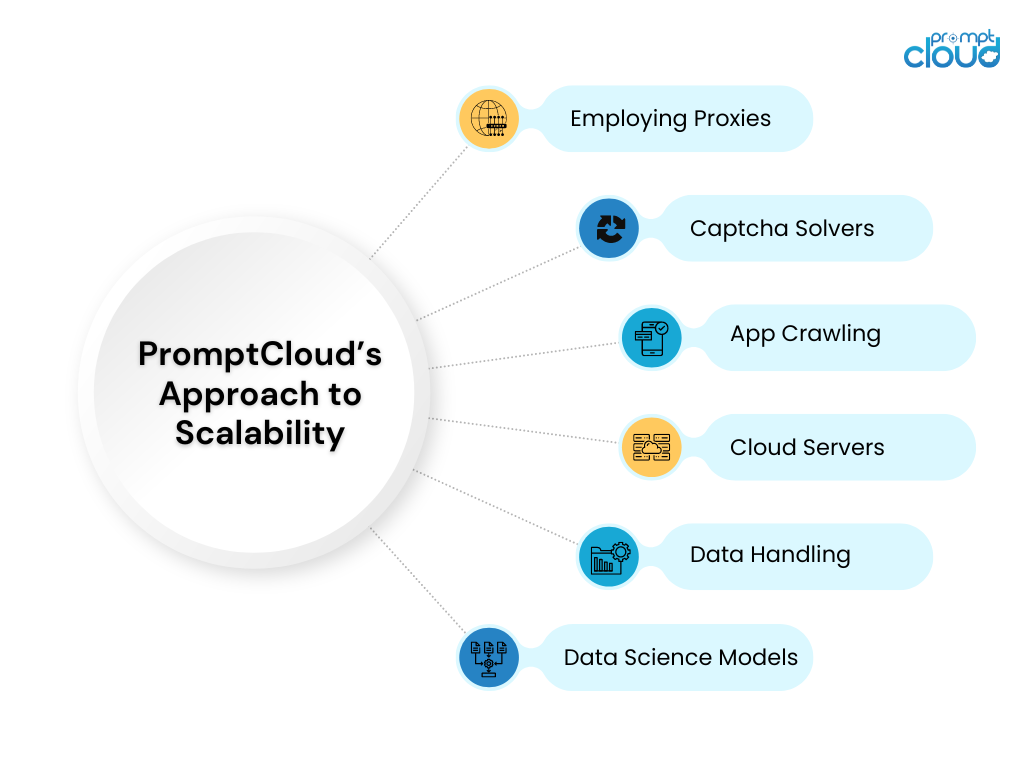
PromptCloud fournit une solution complète pour maintenir la qualité et la précision des données à grande échelle. En tirant parti de leurs services de web scraping à grande échelle et de data scraping gérés, vous pouvez garantir que vos processus de collecte de données restent robustes et fiables.
#4 : Tirer parti des solutions cloud pour l'évolutivité
Les solutions cloud offrent une évolutivité inégalée pour les opérations de récupération de données. Des services comme AWS EC2 et Google Cloud Compute Engine permettent aux entreprises d'augmenter ou de réduire leurs ressources informatiques en fonction de la demande. Cette flexibilité garantit que les opérations de récupération de données peuvent gérer différentes charges de travail sans compromettre les performances.
PromptCloud tire pleinement parti des solutions cloud pour offrir un service de web scraping à grande échelle évolutif et efficace. En s'intégrant aux principales plates-formes cloud, PromptCloud garantit que vos opérations de récupération de données peuvent gérer facilement n'importe quel volume de données.
#5 : Gestion du stockage et de la gestion des données
Des solutions efficaces de stockage et de gestion des données sont essentielles pour gérer de gros volumes de données récupérées. À mesure que la quantité de données augmente, il devient de plus en plus important de garantir qu’elles soient stockées en toute sécurité et qu’elles soient accessibles rapidement.
PromptCloud propose des solutions complètes de stockage et de gestion de données dans le cadre de ses services de récupération de données gérées. En utilisant des solutions de stockage évolutives et en mettant en œuvre les meilleures pratiques en matière de gestion des données, PromptCloud garantit que vos données sont stockées en toute sécurité et sont accessibles efficacement.
Mise à l'échelle des opérations de Web Scraping avec PromptCloud
La mise à l'échelle des opérations de web scraping pour gérer de gros volumes de données présente de nombreux défis, du maintien de la qualité des données et de la gestion du stockage à la garantie d'une récupération et d'un traitement efficaces. Cependant, avec les stratégies et les outils appropriés, ces défis peuvent être relevés efficacement, permettant aux entreprises d'exploiter tout le potentiel du web scraping pour obtenir un avantage concurrentiel et une prise de décision éclairée.
PromptCloud propose une suite complète de solutions conçues pour résoudre les complexités du web scraping à grande échelle. En tirant parti de technologies avancées et d’une infrastructure robuste, nous garantissons que vos opérations de scraping de données sont évolutives, efficaces et fiables. Prêt à faire évoluer vos opérations de scraping Web et à libérer tout le potentiel de vos données ? Associez-vous à PromptCloud pour tirer parti de nos solutions de pointe et de nos services experts. Contactez-nous dès aujourd'hui pour planifier une démonstration et voir nos solutions en action.