
Maîtriser les grattoirs de pages Web : guide du débutant pour extraire des données en ligne
Publié: 2024-04-09Que sont les grattoirs de pages Web ?
Web page scraper est un outil conçu pour extraire des données de sites Web. Il simule la navigation humaine pour collecter du contenu spécifique. Les débutants utilisent souvent ces scrapers pour diverses tâches, notamment les études de marché, la surveillance des prix et la compilation de données pour des projets d'apprentissage automatique.
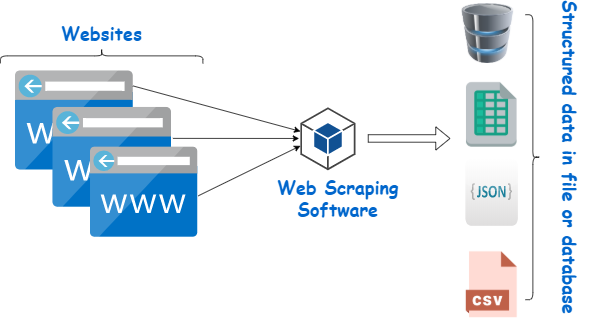
Source de l'image : https://www.webharvy.com/articles/what-is-web-scraping.html
- Facilité d'utilisation : ils sont conviviaux, permettant aux personnes ayant des compétences techniques minimales de capturer efficacement des données Web.
- Efficacité : les scrapers peuvent collecter rapidement de grandes quantités de données, dépassant de loin les efforts de collecte de données manuelle.
- Précision : le scraping automatisé réduit le risque d’erreur humaine, améliorant ainsi la précision des données.
- Rentable : ils éliminent le besoin de saisie manuelle, ce qui permet d'économiser du temps et des coûts de main-d'œuvre.
Comprendre les fonctionnalités des scrapers de pages Web est essentiel pour quiconque cherche à exploiter la puissance des données Web.
Création d'un simple grattoir de page Web avec Python
Pour commencer à créer un scraper de page Web en Python, il faut installer certaines bibliothèques, à savoir des requêtes pour effectuer des requêtes HTTP vers une page Web et BeautifulSoup de bs4 pour analyser les documents HTML et XML.
- Outils de collecte :
- Bibliothèques : utilisez des requêtes pour récupérer des pages Web et BeautifulSoup pour analyser le contenu HTML téléchargé.
- Ciblage de la page Web :
- Définissez l'URL de la page Web contenant les données que nous souhaitons récupérer.
- Téléchargement du contenu :
- À l’aide de requêtes, téléchargez le code HTML de la page Web.
- Analyser le HTML :
- BeautifulSoup transformera le HTML téléchargé dans un format structuré pour une navigation facile.
- Extraction des données :
- Identifiez les balises HTML spécifiques contenant les informations souhaitées (par exemple, les titres de produits dans les balises <div>).
- À l'aide des méthodes BeautifulSoup, extrayez et traitez les données dont vous avez besoin.
N'oubliez pas de cibler les éléments HTML spécifiques pertinents pour les informations que vous souhaitez récupérer.
Processus étape par étape pour supprimer une page Web
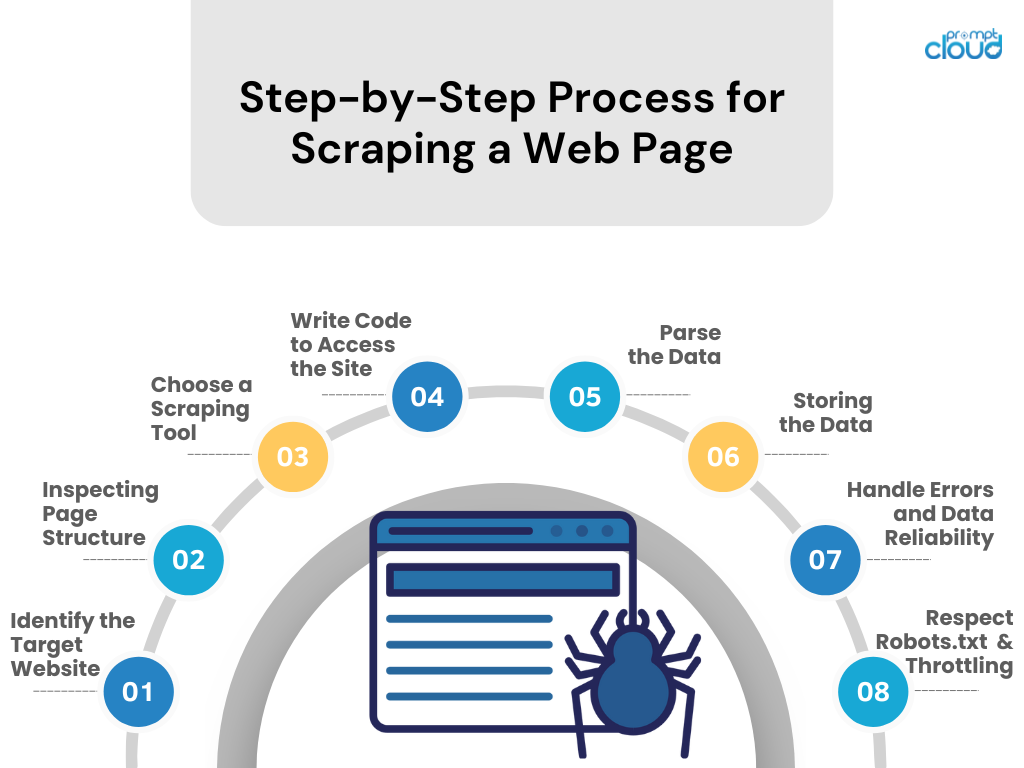
- Identifiez le site Web cible
Recherchez le site Web que vous souhaitez gratter. Assurez-vous que cela est légal et éthique. - Inspection de la structure des pages
Utilisez les outils de développement du navigateur pour examiner la structure HTML, les sélecteurs CSS et le contenu JavaScript. - Choisissez un outil de grattage
Sélectionnez un outil ou une bibliothèque dans un langage de programmation avec lequel vous êtes à l'aise (par exemple, BeautifulSoup ou Scrapy de Python). - Écrire du code pour accéder au site
Créez un script qui demande des données au site Web, en utilisant des appels API si disponibles ou des requêtes HTTP. - Analyser les données
Extrayez les données pertinentes de la page Web en analysant le HTML/CSS/JavaScript. - Stockage des données
Enregistrez les données récupérées dans un format structuré, tel que CSV, JSON ou directement dans une base de données. - Gérer les erreurs et la fiabilité des données
Implémentez la gestion des erreurs pour gérer les échecs de requêtes et maintenir l’intégrité des données. - Respectez Robots.txt et la limitation
Adhérez aux règles du fichier robots.txt du site et évitez de surcharger le serveur en contrôlant le taux de requêtes.
Sélection des outils de scraping Web idéaux pour vos besoins
Lorsque vous explorez le Web, il est crucial de sélectionner des outils adaptés à vos compétences et à vos objectifs. Les débutants devraient considérer :
- Facilité d’utilisation : Optez pour des outils intuitifs avec une assistance visuelle et une documentation claire.
- Exigences en matière de données : évaluez la structure et la complexité des données cibles pour déterminer si une simple extension ou un logiciel robuste est nécessaire.
- Budget : évaluez le coût par rapport aux fonctionnalités ; de nombreux grattoirs efficaces proposent des niveaux gratuits.
- Personnalisation : assurez-vous que l’outil est adaptable aux besoins de grattage spécifiques.
- Assistance : l'accès à une communauté d'utilisateurs utile facilite le dépannage et l'amélioration.
Choisissez judicieusement pour un voyage de grattage en douceur.
Trucs et astuces pour optimiser votre grattoir de page Web
- Utilisez des bibliothèques d'analyse efficaces comme BeautifulSoup ou Lxml en Python pour un traitement HTML plus rapide.
- Implémentez la mise en cache pour éviter de retélécharger les pages et réduire la charge sur le serveur.
- Respectez les fichiers robots.txt et utilisez la limitation de débit pour éviter d'être banni par le site Web cible.
- Faites pivoter les agents utilisateurs et les serveurs proxy pour imiter le comportement humain et éviter d'être détecté.
- Planifiez les scrapers pendant les heures creuses pour minimiser l'impact sur les performances du site Web.
- Optez pour des points de terminaison d'API s'ils sont disponibles, car ils fournissent des données structurées et sont généralement plus efficaces.
- Évitez de supprimer des données inutiles en étant sélectif dans vos requêtes, réduisant ainsi la bande passante et le stockage requis.
- Mettez régulièrement à jour vos scrapers pour vous adapter aux changements dans la structure du site Web et maintenir l’intégrité des données.
Gestion des problèmes courants et dépannage lors du scraping de pages Web
Lorsqu'ils travaillent avec des scrapers de pages Web, les débutants peuvent être confrontés à plusieurs problèmes courants :

- Problèmes de sélecteur : assurez-vous que les sélecteurs correspondent à la structure actuelle de la page Web. Des outils tels que les outils de développement de navigateur peuvent aider à identifier les bons sélecteurs.
- Contenu dynamique : Certaines pages Web chargent le contenu de manière dynamique avec JavaScript. Dans de tels cas, envisagez d'utiliser des navigateurs sans tête ou des outils qui affichent JavaScript.
- Requêtes bloquées : les sites Web peuvent bloquer les scrapers. Utilisez des stratégies telles que la rotation des agents utilisateurs, l'utilisation de proxys et le respect du fichier robots.txt pour atténuer le blocage.
- Problèmes de format des données : les données extraites peuvent nécessiter un nettoyage ou un formatage. Utilisez des expressions régulières et la manipulation de chaînes pour standardiser les données.
N'oubliez pas de consulter la documentation et les forums communautaires pour obtenir des conseils de dépannage spécifiques.
Conclusion
Les débutants peuvent désormais collecter facilement des données sur le Web grâce au grattoir de pages Web, ce qui rend la recherche et l'analyse plus efficaces. Comprendre les bonnes méthodes tout en tenant compte des aspects juridiques et éthiques permet aux utilisateurs d’exploiter tout le potentiel du web scraping. Suivez ces directives pour une introduction fluide au scraping de pages Web, remplie d'informations précieuses et d'une prise de décision éclairée.
FAQ :
Qu’est-ce que gratter une page ?
Le web scraping, également appelé data scraping ou web moissoning, consiste à extraire automatiquement des données de sites Web à l'aide de programmes informatiques imitant les comportements de navigation humaine. Avec un grattoir de pages Web, de grandes quantités d'informations peuvent être rapidement triées, en se concentrant uniquement sur les sections importantes au lieu de les compiler manuellement.
Les entreprises appliquent le web scraping pour des fonctions telles que l'examen des coûts, la gestion des réputations, l'analyse des tendances et l'exécution d'analyses concurrentielles. La mise en œuvre de projets de web scraping garantit la vérification que les sites Web visités approuvent l'action et le respect de tous les protocoles robots.txt et no-follow pertinents.
Comment gratter une page entière ?
Pour récupérer une page Web entière, vous avez généralement besoin de deux composants : un moyen de localiser les données requises dans la page Web et un mécanisme pour enregistrer ces données ailleurs. De nombreux langages de programmation prennent en charge le web scraping, notamment Python et JavaScript.
Diverses bibliothèques open source existent pour les deux, simplifiant encore davantage le processus. Certains choix populaires parmi les développeurs Python incluent BeautifulSoup, Requests, LXML et Scrapy. Alternativement, des plates-formes commerciales telles que ParseHub et Octoparse permettent à des personnes moins techniques de créer visuellement des flux de travail de web scraping complexes. Après avoir installé les bibliothèques nécessaires et compris les concepts de base derrière la sélection des éléments DOM, commencez par identifier les points de données d'intérêt dans la page Web cible.
Utilisez les outils de développement de navigateur pour inspecter les balises et les attributs HTML, puis traduisez ces résultats dans la syntaxe correspondante prise en charge par la bibliothèque ou la plate-forme choisie. Enfin, spécifiez les préférences de format de sortie, que ce soit CSV, Excel, JSON, SQL ou une autre option, ainsi que les destinations où résident les données enregistrées.
Comment utiliser le scraper Google ?
Contrairement à la croyance populaire, Google ne propose pas directement d'outil public de web scraping en soi, bien qu'il fournisse des API et des SDK pour faciliter une intégration transparente avec plusieurs produits. Néanmoins, des développeurs qualifiés ont créé des solutions tierces basées sur les technologies de base de Google, étendant efficacement les capacités au-delà des fonctionnalités natives. Les exemples incluent SerpApi, qui résume les aspects complexes de Google Search Console et présente une interface facile à utiliser pour le suivi du classement des mots clés, l'estimation du trafic organique et l'exploration des backlinks.
Bien que techniquement distincts du web scraping traditionnel, ces modèles hybrides brouillent les frontières séparant les définitions conventionnelles. D'autres exemples présentent des efforts d'ingénierie inverse appliqués à la reconstruction de la logique interne qui pilote la plate-forme Google Maps, l'API de données YouTube v3 ou les services Google Shopping, produisant des fonctionnalités remarquablement proches de leurs homologues d'origine, bien que soumises à divers degrés de risques en matière de légalité et de durabilité. En fin de compte, les aspirants scrapers de pages Web devraient explorer diverses options et évaluer leurs mérites par rapport à des exigences spécifiques avant de s'engager dans une voie donnée.
Le scraper Facebook est-il légal ?
Comme indiqué dans les politiques des développeurs de Facebook, le scraping Web non autorisé constitue une violation flagrante des normes de leur communauté. Les utilisateurs acceptent de ne pas développer ou exploiter des applications, des scripts ou d'autres mécanismes conçus pour contourner ou dépasser les limites de débit d'API désignées, et ils ne doivent pas non plus tenter de déchiffrer, décompiler ou procéder à une ingénierie inverse sur tout aspect du site ou du service. En outre, il met en évidence les attentes en matière de protection des données et de confidentialité, exigeant le consentement explicite de l'utilisateur avant de partager des informations personnellement identifiables en dehors des contextes autorisés.
Tout manquement aux principes énoncés déclenche des mesures disciplinaires croissantes commençant par des avertissements et progressant progressivement vers un accès restreint ou une révocation complète des privilèges en fonction des niveaux de gravité. Malgré les exceptions prévues pour les chercheurs en sécurité opérant dans le cadre de programmes de bug bounty approuvés, le consensus général préconise d'éviter les initiatives de scraping non autorisées de Facebook afin d'éviter des complications inutiles. Envisagez plutôt de rechercher des alternatives compatibles avec les normes et conventions en vigueur approuvées par la plateforme.