
Surmonter les défis techniques du Web Scraping : solutions expertes
Publié: 2024-03-29Le web scraping est une pratique qui comporte de nombreux défis techniques, même pour les mineurs de données chevronnés. Cela implique l'utilisation de techniques de programmation pour obtenir et récupérer des données sur des sites Web, ce qui n'est pas toujours facile en raison de la nature complexe et variée des technologies Web.
De plus, de nombreux sites Web ont mis en place des mesures de protection pour empêcher la collecte de données, ce qui oblige les scrapers à négocier des mécanismes anti-scraping, un contenu dynamique et des structures de site complexes.
Même si l’objectif d’acquérir des informations utiles paraît rapidement simple, y parvenir nécessite de surmonter plusieurs barrières redoutables, exigeant de fortes capacités analytiques et techniques.
Gestion du contenu dynamique
Le contenu dynamique, qui fait référence aux informations de page Web mises à jour en fonction des actions de l'utilisateur ou chargées après l'affichage initial de la page, pose généralement des défis aux outils de web scraping.
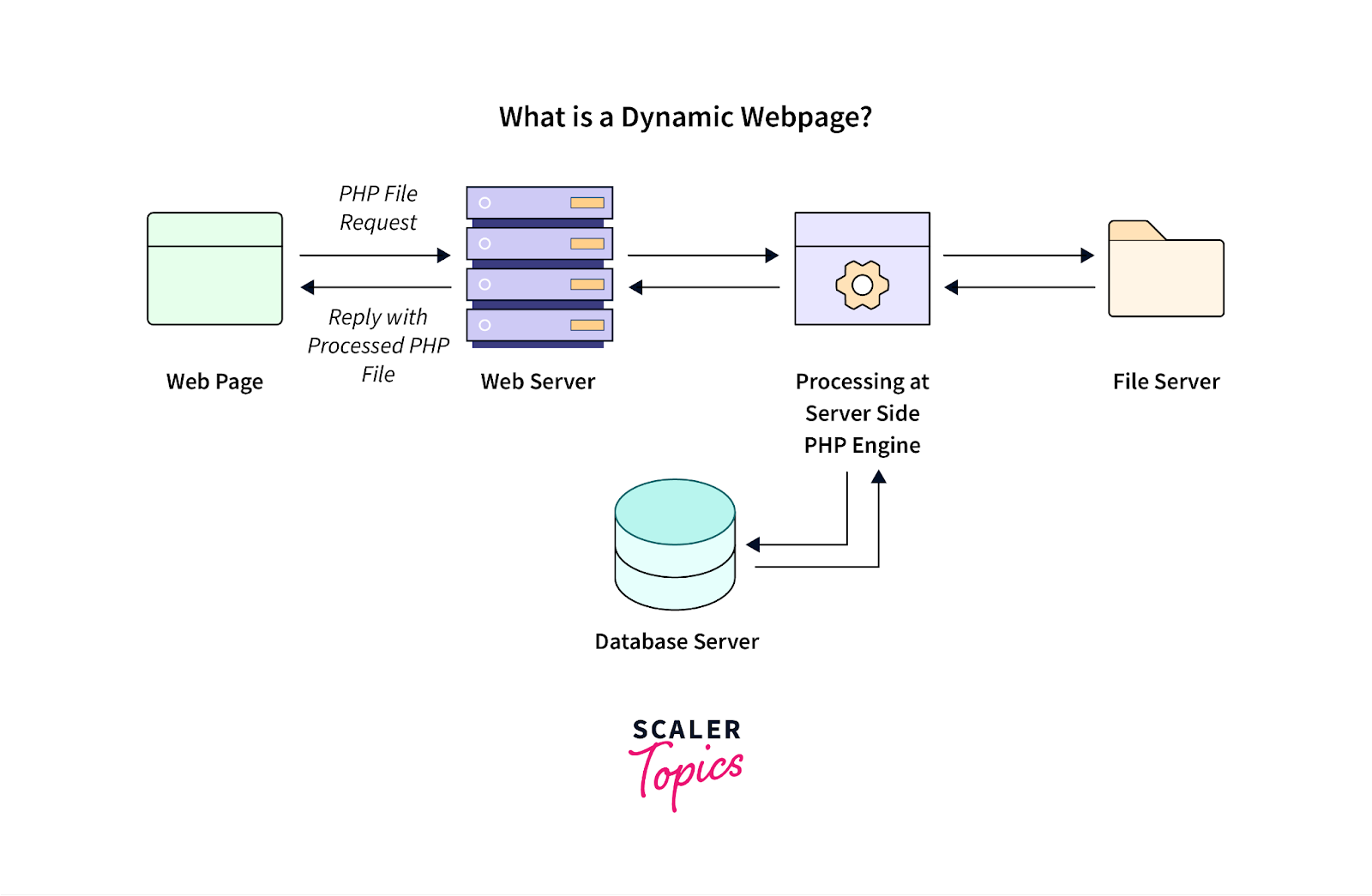
Source de l'image : https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
Un tel contenu dynamique est fréquemment utilisé dans les applications Web contemporaines créées à l'aide de frameworks JavaScript. Pour gérer et extraire avec succès les données d’un tel contenu généré dynamiquement, tenez compte de ces bonnes pratiques :
- Pensez à utiliser des outils d'automatisation Web tels que Selenium, Puppeteer ou Playwright, qui permettent à votre grattoir Web de se comporter sur la page Web de la même manière qu'un véritable utilisateur.
- Implémentez des techniques de gestion WebSockets ou AJAX si le site Web utilise ces technologies pour charger le contenu de manière dynamique.
- Attendez que les éléments se chargent en utilisant des attentes explicites dans votre code de scraping pour vous assurer que le contenu est entièrement chargé avant de tenter de le scraper.
- Explorez à l'aide de navigateurs sans tête qui peuvent exécuter JavaScript et afficher la page complète, y compris le contenu chargé dynamiquement.
En maîtrisant ces stratégies, les scrapers peuvent extraire efficacement des données même des sites Web les plus interactifs et les plus dynamiques.
Technologies anti-grattage
Il est courant que les développeurs Web mettent en place des mesures visant à empêcher le grattage de données non approuvé afin de protéger leurs sites Web. Ces mesures peuvent poser des défis importants aux web scrapers. Voici plusieurs méthodes et stratégies pour naviguer dans les technologies anti-grattage :

Source de l'image : https://kinsta.com/knowledgebase/what-is-web-scraping/
- Factorisation dynamique : les sites Web peuvent générer du contenu de manière dynamique, ce qui rend plus difficile la prédiction des URL ou des structures HTML. Utilisez des outils capables d'exécuter JavaScript et de gérer les requêtes AJAX.
- Blocage IP : des requêtes fréquentes provenant de la même IP peuvent entraîner des blocages. Utilisez un pool de serveurs proxy pour alterner les adresses IP et imiter les modèles de trafic humain.
- CAPTCHA : ils sont conçus pour faire la distinction entre les humains et les robots. Appliquez les services de résolution de CAPTCHA ou optez pour la saisie manuelle si possible.
- Limitation du débit : pour éviter les limites de taux de déclenchement, limitez vos taux de requêtes et implémentez des délais aléatoires entre les requêtes.
- Agent utilisateur : les sites Web peuvent bloquer les agents utilisateurs de grattage connus. Faites pivoter les agents utilisateurs pour imiter différents navigateurs ou appareils.
Relever ces défis nécessite une approche sophistiquée qui respecte les conditions de service du site Web tout en accédant efficacement aux données nécessaires.
Gérer les pièges CAPTCHA et Honeypot
Les scrapers Web rencontrent souvent des défis CAPTCHA conçus pour distinguer les utilisateurs humains des robots. Pour surmonter cela, il faut :
- Utiliser des services de résolution de CAPTCHA qui exploitent les capacités humaines ou IA.
- Mettre en œuvre des retards et randomiser les demandes pour imiter le comportement humain.
Pour les pièges honeypot, qui sont invisibles pour les utilisateurs mais piègent les scripts automatisés :
- Inspectez soigneusement le code du site Web pour éviter toute interaction avec des liens cachés.
- Utiliser des pratiques de grattage moins agressives pour rester sous le radar.
Les développeurs doivent éthiquement équilibrer l’efficacité avec le respect des conditions du site Web et de l’expérience utilisateur.
Efficacité de grattage et optimisation de la vitesse
Les processus de scraping Web peuvent être améliorés en optimisant à la fois l’efficacité et la vitesse. Pour surmonter les défis dans ce domaine :
- Utilisez le multithreading pour permettre une extraction simultanée des données, augmentant ainsi le débit.
- Tirez parti des navigateurs sans tête pour une exécution plus rapide en éliminant le chargement inutile de contenu graphique.
- Optimisez le code de scraping pour qu'il s'exécute avec une latence minimale.
- Mettez en œuvre une limitation de requêtes appropriée pour éviter les interdictions d’adresses IP tout en maintenant un rythme stable.
- Mettez en cache le contenu statique pour éviter les téléchargements répétés, économisant ainsi la bande passante et le temps.
- Utilisez des techniques de programmation asynchrone pour optimiser les opérations d’E/S réseau.
- Choisissez des sélecteurs et des bibliothèques d'analyse efficaces pour réduire la surcharge de manipulation du DOM.
En intégrant ces stratégies, les web scrapers peuvent atteindre des performances robustes avec des problèmes opérationnels minimisés.

Extraction et analyse de données
Le web scraping nécessite une extraction et une analyse précises des données, ce qui présente des défis distincts. Voici des façons d’y remédier :
- Utilisez des bibliothèques robustes comme BeautifulSoup ou Scrapy, qui peuvent gérer diverses structures HTML.
- Implémentez les expressions régulières avec prudence pour cibler des modèles spécifiques avec précision.
- Tirez parti des outils d'automatisation du navigateur tels que Selenium pour interagir avec des sites Web contenant beaucoup de JavaScript, en garantissant que les données sont restituées avant l'extraction.
- Adoptez les sélecteurs XPath ou CSS pour identifier avec précision les éléments de données dans le DOM.
- Gérez la pagination et le défilement infini en identifiant et en manipulant le mécanisme qui charge le nouveau contenu (par exemple, mise à jour des paramètres d'URL ou gestion des appels AJAX).
Maîtriser l’art du Web Scraping
Le Web scraping est une compétence inestimable dans le monde axé sur les données. Relever les défis techniques, allant du contenu dynamique à la détection des robots, nécessite de la persévérance et de l'adaptabilité. Un web scraping réussi implique un mélange de ces approches :
- Mettez en œuvre une exploration intelligente pour respecter les ressources du site Web et naviguer sans détection.
- Utilisez une analyse avancée pour gérer le contenu dynamique, garantissant ainsi que l’extraction des données est robuste face aux modifications.
- Utilisez stratégiquement les services de résolution de CAPTCHA pour maintenir l’accès sans interrompre le flux de données.
- Gérez judicieusement les adresses IP et les en-têtes de requêtes pour dissimuler les activités de scraping.
- Gérez les modifications de la structure du site Web en mettant régulièrement à jour les scripts de l'analyseur.
En maîtrisant ces techniques, on peut naviguer habilement dans les subtilités de l’exploration du Web et débloquer de vastes réserves de données précieuses.
Gestion de projets de scraping à grande échelle
Les projets de web scraping à grande échelle nécessitent une gestion robuste pour garantir l’efficacité et la conformité. Le partenariat avec des fournisseurs de services de web scraping offre plusieurs avantages :

Confier les projets de scraping à des professionnels peut optimiser les résultats et minimiser la charge technique de votre équipe interne.
FAQ
Quelles sont les limites du web scraping ?
Le Web scraping est confronté à certaines contraintes qu'il faut prendre en compte avant de l'intégrer dans ses opérations. Légalement, certains sites Web interdisent le scraping via des termes et conditions ou des fichiers robot.txt ; ignorer ces restrictions pourrait entraîner de graves conséquences.
Techniquement, les sites Web peuvent déployer des contre-mesures contre le scraping, telles que des CAPTCHA, des blocs IP et des pots de miel, empêchant ainsi tout accès non autorisé. L'exactitude des données extraites peut également devenir un problème en raison du rendu dynamique et des sources fréquemment mises à jour. Enfin, le web scraping nécessite un savoir-faire technique, un investissement en ressources et des efforts continus, ce qui présente des défis, en particulier pour les personnes non techniques.
Pourquoi la récupération de données est-elle un problème ?
Les problèmes surviennent principalement lorsque la récupération de données se produit sans autorisations requises ni conduite éthique. L’extraction d’informations confidentielles enfreint les normes de confidentialité et transgresse les lois conçues pour protéger les intérêts individuels.
La surutilisation du scraping met à rude épreuve les serveurs cibles, ce qui a un impact négatif sur les performances et la disponibilité. Le vol de propriété intellectuelle constitue encore une autre préoccupation découlant du grattage illicite en raison d'éventuelles poursuites pour violation du droit d'auteur intentées par les parties lésées.
Par conséquent, le respect des stipulations politiques, le respect des normes éthiques et la recherche du consentement lorsque cela est nécessaire restent cruciaux lors de l’exécution de tâches de grattage de données.
Pourquoi le web scraping peut-il être inexact ?
Le web scraping, qui consiste à extraire automatiquement des données de sites Web via un logiciel spécialisé, ne garantit pas une exactitude totale en raison de divers facteurs. Par exemple, des modifications dans la structure du site Web pourraient entraîner un dysfonctionnement de l'outil de grattage ou capturer des informations erronées.
De plus, certains sites Web mettent en œuvre des mesures anti-scraping telles que des tests CAPTCHA, des blocages IP ou un rendu JavaScript, entraînant des données manquées ou déformées. Parfois, les oublis des développeurs lors de la création contribuent également à des résultats sous-optimaux.
Cependant, un partenariat avec des fournisseurs de services de web scraping compétents peut renforcer la précision, car ils apportent le savoir-faire et les atouts requis pour construire des scrapers résilients et agiles, capables de maintenir des niveaux de précision élevés malgré les changements de configuration des sites Web. Des experts qualifiés testent et valident méticuleusement ces grattoirs avant leur mise en œuvre, garantissant ainsi l'exactitude tout au long du processus d'extraction.
Le web scraping est-il fastidieux ?
En effet, s’engager dans des activités de web scraping peut s’avérer laborieux et exigeant, en particulier pour ceux qui manquent d’expertise en codage ou de compréhension des plateformes numériques. De telles tâches nécessitent de créer des codes sur mesure, de rectifier les scrapers défectueux, d’administrer les architectures de serveur et de se tenir au courant des modifications survenant sur les sites Web ciblés – tout cela nécessitant des capacités techniques considérables ainsi que des investissements substantiels en termes de temps.
L'extension des activités de base de web scraping devient de plus en plus complexe compte tenu des considérations liées à la conformité réglementaire, à la gestion de la bande passante et à la mise en œuvre de systèmes informatiques distribués.
En revanche, opter pour des services professionnels de web scraping réduit considérablement les charges associées grâce à des offres prêtes à l'emploi conçues en fonction des demandes spécifiques des utilisateurs. Par conséquent, les clients se concentrent principalement sur l'exploitation des données collectées tout en laissant la logistique de collecte à des équipes dédiées composées de développeurs qualifiés et de spécialistes informatiques responsables de l'optimisation du système, de l'allocation des ressources et du traitement des requêtes juridiques, réduisant ainsi considérablement l'ennui global lié aux initiatives de web scraping.