
Python Web Crawler – Tutoriel étape par étape
Publié: 2023-12-07Les robots d'exploration Web sont des outils fascinants dans le monde de la collecte de données et du web scraping. Ils automatisent le processus de navigation sur le Web pour collecter des données qui peuvent être utilisées à diverses fins, telles que l'indexation des moteurs de recherche, l'exploration de données ou l'analyse concurrentielle. Dans ce didacticiel, nous allons nous lancer dans un voyage informatif pour créer un robot d'exploration Web de base à l'aide de Python, un langage connu pour sa simplicité et ses puissantes capacités de gestion des données Web.
Python, avec son riche écosystème de bibliothèques, fournit une excellente plate-forme pour développer des robots d'exploration Web. Que vous soyez un développeur en herbe, un passionné de données ou simplement curieux de savoir comment fonctionnent les robots d'exploration Web, ce guide étape par étape est conçu pour vous présenter les bases de l'exploration Web et vous doter des compétences nécessaires pour créer votre propre robot d'exploration. .
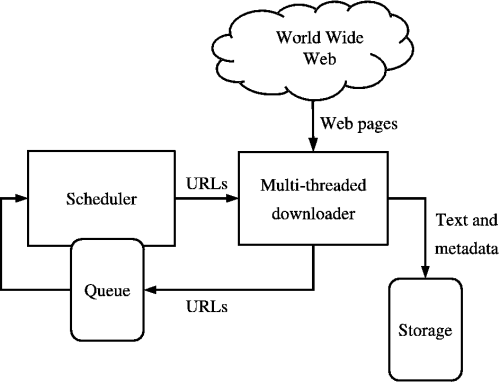
Source : https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Crawler - Comment créer un robot d'exploration Web
Étape 1 : Comprendre les bases
Un robot d'exploration Web, également connu sous le nom d'araignée, est un programme qui parcourt le World Wide Web de manière méthodique et automatisée. Pour notre robot d'exploration, nous utiliserons Python en raison de sa simplicité et de ses bibliothèques puissantes.
Étape 2 : Configurez votre environnement
Installer Python : assurez-vous que Python est installé. Vous pouvez le télécharger depuis python.org.
Installer les bibliothèques : vous aurez besoin de requêtes pour effectuer des requêtes HTTP et de BeautifulSoup de bs4 pour analyser le HTML. Installez-les en utilisant pip :
demandes d'installation pip pip install beautifulsoup4
Étape 3 : Écrire un robot d'exploration de base
Importer des bibliothèques :
importer des requêtes depuis bs4 importer BeautifulSoup
Récupérer une page Web :
Ici, nous allons récupérer le contenu d'une page Web. Remplacez « URL » par la page Web que vous souhaitez explorer.
url = 'URL' réponse = requêtes.get(url) contenu = réponse.content
Analyser le contenu HTML :
soupe = BeautifulSoup (contenu, 'html.parser')
Extraire les informations :
Par exemple, pour extraire tous les hyperliens, vous pouvez faire :
pour le lien dans soup.find_all('a'): print(link.get('href'))
Étape 4 : Développez votre robot d'exploration
Gestion des URL relatives :
Utilisez urljoin pour gérer les URL relatives.
depuis urllib.parse importer urljoin
Évitez d'explorer deux fois la même page :
Conservez un ensemble d’URL visitées pour éviter la redondance.
Ajout de délais :
L'exploration respectueuse inclut les délais entre les demandes. Utilisez time.sleep().
Étape 5 : Respectez le fichier Robots.txt
Assurez-vous que votre robot respecte le fichier robots.txt des sites Web, qui indique quelles parties du site ne doivent pas être explorées.
Étape 6 : Gestion des erreurs
Implémentez des blocs try-sauf pour gérer les erreurs potentielles telles que les délais d'attente de connexion ou l'accès refusé.
Étape 7 : Aller plus loin
Vous pouvez améliorer votre robot pour gérer des tâches plus complexes, telles que les soumissions de formulaires ou le rendu JavaScript. Pour les sites Web utilisant beaucoup de JavaScript, envisagez d'utiliser Selenium.
Étape 8 : stocker les données
Décidez comment stocker les données que vous avez explorées. Les options incluent des fichiers simples, des bases de données ou même l'envoi direct de données à un serveur.
Étape 9 : Soyez éthique
- Ne surchargez pas les serveurs ; ajouter des retards dans vos demandes.
- Suivez les conditions d'utilisation du site Web.
- Ne récupérez pas et ne stockez pas de données personnelles sans autorisation.
Se faire bloquer est un défi courant lors de l'exploration du Web, en particulier lorsqu'il s'agit de sites Web qui ont mis en place des mesures pour détecter et bloquer l'accès automatisé. Voici quelques stratégies et considérations pour vous aider à résoudre ce problème en Python :
Comprendre pourquoi vous êtes bloqué
Requêtes fréquentes : des requêtes rapides et répétées provenant de la même adresse IP peuvent déclencher un blocage.
Modèles non humains : les robots présentent souvent un comportement distinct des modèles de navigation humains, comme accéder aux pages trop rapidement ou dans un ordre prévisible.
Mauvaise gestion des en-têtes : des en-têtes HTTP manquants ou incorrects peuvent rendre vos demandes suspectes.
Ignorer le fichier robots.txt : le non-respect des directives du fichier robots.txt d'un site peut entraîner des blocages.
Stratégies pour éviter d'être bloqué
Respectez le fichier robots.txt : Vérifiez et respectez toujours le fichier robots.txt du site. C'est une pratique éthique et peut éviter un blocage inutile.
Agents utilisateurs rotatifs : les sites Web peuvent vous identifier grâce à votre agent utilisateur. En le faisant pivoter, vous réduisez le risque d’être signalé comme robot. Utilisez la bibliothèque fake_useragent pour implémenter cela.
from fake_useragent import UserAgent ua = UserAgent() en-têtes = {'User-Agent': ua.random}
Ajout de délais : la mise en œuvre d'un délai entre les requêtes peut imiter le comportement humain. Utilisez time.sleep() pour ajouter un délai aléatoire ou fixe.

temps d'importation time.sleep(3) # Attend 3 secondes
Rotation IP : si possible, utilisez les services proxy pour faire pivoter votre adresse IP. Il existe des services gratuits et payants disponibles pour cela.
Utilisation de sessions : un objet request.Session en Python peut aider à maintenir une connexion cohérente et à partager des en-têtes, des cookies, etc. entre les requêtes, faisant ressembler votre robot d'exploration à une session de navigateur normale.
avec request.Session() comme session : session.headers = {'User-Agent' : ua.random} réponse = session.get(url)
Gestion de JavaScript : certains sites Web s'appuient fortement sur JavaScript pour charger le contenu. Des outils comme Selenium ou Puppeteer peuvent imiter un vrai navigateur, y compris le rendu JavaScript.
Gestion des erreurs : implémentez une gestion robuste des erreurs pour gérer et répondre avec élégance aux blocages ou autres problèmes.
Considérations éthiques
- Respectez toujours les conditions d’utilisation d’un site Web. Si un site interdit explicitement le web scraping, il est préférable de s'y conformer.
- Soyez conscient de l'impact de votre robot sur les ressources du site Web. La surcharge d'un serveur peut entraîner des problèmes pour le propriétaire du site.
Techniques avancées
- Web Scraping Frameworks : envisagez d'utiliser des frameworks comme Scrapy, qui disposent de fonctionnalités intégrées pour gérer divers problèmes d'exploration.
- Services de résolution de CAPTCHA : pour les sites présentant des défis CAPTCHA, il existe des services qui peuvent résoudre les CAPTCHA, bien que leur utilisation soulève des problèmes éthiques.
Meilleures pratiques d'exploration du Web en Python
S'engager dans des activités d'exploration du Web nécessite un équilibre entre efficacité technique et responsabilité éthique. Lorsque vous utilisez Python pour l'exploration du Web, il est important de respecter les meilleures pratiques qui respectent les données et les sites Web dont elles proviennent. Voici quelques considérations clés et bonnes pratiques pour l’exploration Web en Python :
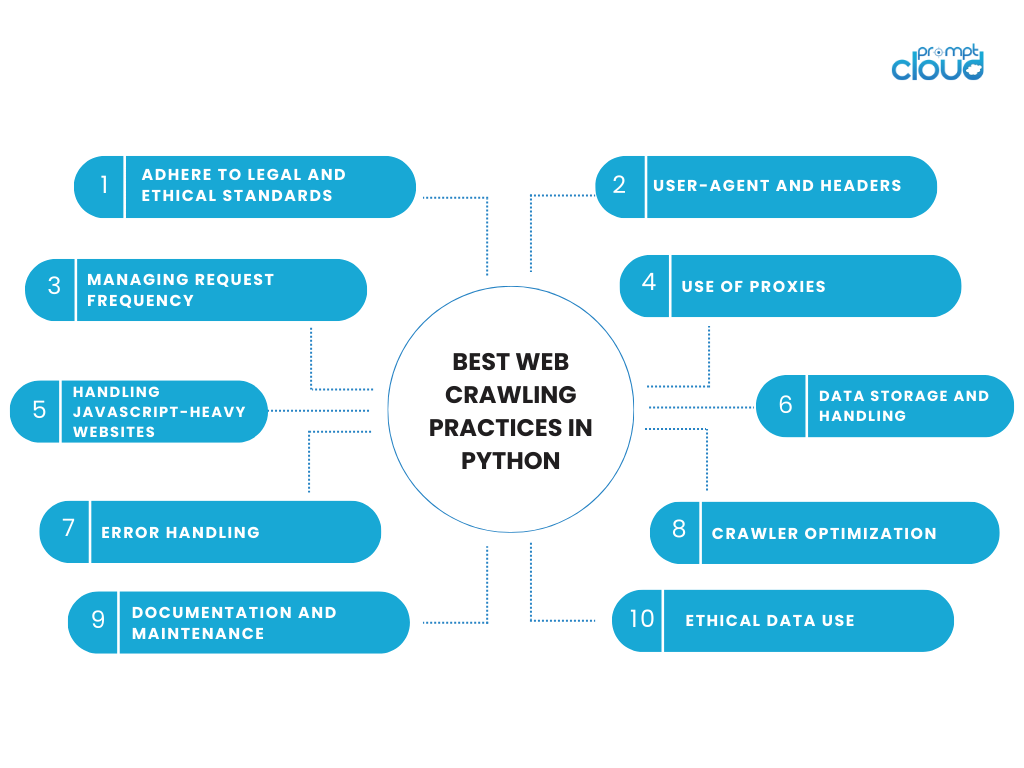
Adhérer aux normes juridiques et éthiques
- Respectez le fichier robots.txt : vérifiez toujours le fichier robots.txt du site Web. Ce fichier décrit les zones du site que le propriétaire du site Web préfère ne pas explorer.
- Suivez les conditions d’utilisation : de nombreux sites Web incluent des clauses concernant le web scraping dans leurs conditions d’utilisation. Le respect de ces conditions est à la fois éthique et juridiquement prudent.
- Évitez de surcharger les serveurs : effectuez des demandes à un rythme raisonnable pour éviter de surcharger le serveur du site Web.
Agent utilisateur et en-têtes
- Identifiez-vous : utilisez une chaîne d'agent utilisateur qui inclut vos informations de contact ou le but de votre exploration. Cette transparence peut renforcer la confiance.
- Utilisez les en-têtes de manière appropriée : des en-têtes HTTP bien configurés peuvent réduire le risque de blocage. Ils peuvent inclure des informations telles que l'agent utilisateur, la langue d'acceptation, etc.
Gestion de la fréquence des demandes
- Ajouter des délais : implémentez un délai entre les requêtes pour imiter les modèles de navigation humaine. Utilisez la fonction time.sleep() de Python.
- Limitation du débit : soyez conscient du nombre de requêtes que vous envoyez à un site Web dans un laps de temps donné.
Utilisation de procurations
- Rotation IP : l'utilisation de proxys pour alterner votre adresse IP peut aider à éviter le blocage basé sur l'IP, mais cela doit être fait de manière responsable et éthique.
Gestion des sites Web lourds en JavaScript
- Contenu dynamique : pour les sites qui chargent du contenu de manière dynamique avec JavaScript, des outils comme Selenium ou Puppeteer (en combinaison avec Pyppeteer pour Python) peuvent afficher les pages comme un navigateur.
Stockage et traitement des données
- Stockage des données : stockez les données analysées de manière responsable, en tenant compte des lois et réglementations sur la confidentialité des données.
- Minimisez l’extraction de données : extrayez uniquement les données dont vous avez besoin. Évitez de collecter des informations personnelles ou sensibles, sauf si cela est absolument nécessaire et légal.
La gestion des erreurs
- Gestion robuste des erreurs : implémentez une gestion complète des erreurs pour gérer les problèmes tels que les délais d'attente, les erreurs de serveur ou le contenu qui ne se charge pas.
Optimisation du robot d'exploration
- Évolutivité : concevez votre robot d'exploration pour gérer une augmentation d'échelle, à la fois en termes de nombre de pages explorées et de quantité de données traitées.
- Efficacité : optimisez votre code pour plus d’efficacité. Un code efficace réduit la charge sur votre système et sur le serveur cible.
Documentation et maintenance
- Conserver la documentation : documentez votre code et votre logique d'exploration pour référence et maintenance futures.
- Mises à jour régulières : gardez votre code d'exploration à jour, surtout si la structure du site Web cible change.
Utilisation éthique des données
- Utilisation éthique : utilisez les données que vous avez collectées de manière éthique, en respectant la confidentialité des utilisateurs et les normes d'utilisation des données.
En conclusion
En concluant notre exploration de la création d'un robot d'exploration Web en Python, nous avons parcouru les subtilités de la collecte automatisée de données et les considérations éthiques qui l'accompagnent. Cet effort améliore non seulement nos compétences techniques, mais approfondit également notre compréhension de la gestion responsable des données dans le vaste paysage numérique.
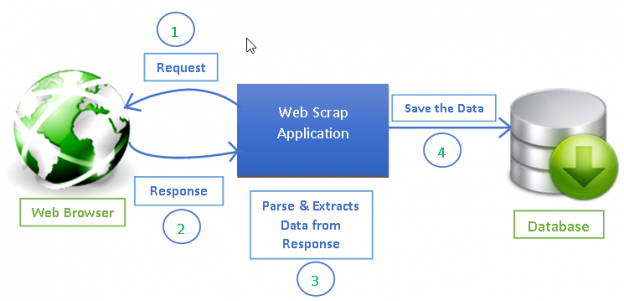
Source : https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Cependant, la création et la maintenance d'un robot d'exploration Web peuvent s'avérer une tâche complexe et fastidieuse, en particulier pour les entreprises ayant des besoins spécifiques en matière de données à grande échelle. C'est là que les services de scraping Web personnalisés de PromptCloud entrent en jeu. Si vous recherchez une solution sur mesure, efficace et éthique pour répondre à vos besoins en matière de données Web, PromptCloud propose une gamme de services adaptés à vos besoins uniques. De la gestion de sites Web complexes à la fourniture de données claires et structurées, ils garantissent que vos projets de web scraping se déroulent sans tracas et correspondent à vos objectifs commerciaux.
Pour les entreprises et les particuliers qui n’ont peut-être pas le temps ou l’expertise technique pour développer et gérer leurs propres robots d’exploration Web, confier cette tâche à des experts comme PromptCloud peut changer la donne. Leurs services permettent non seulement d'économiser du temps et des ressources, mais garantissent également que vous obtenez les données les plus précises et les plus pertinentes, tout en respectant les normes juridiques et éthiques.
Vous souhaitez en savoir plus sur la façon dont PromptCloud peut répondre à vos besoins spécifiques en matière de données ? Contactez-les à sales@promptcloud.com pour plus d'informations et pour discuter de la manière dont leurs solutions de web scraping personnalisées peuvent vous aider à faire progresser votre entreprise.
Dans le monde dynamique des données Web, disposer d'un partenaire fiable comme PromptCloud peut donner du pouvoir à votre entreprise, vous donnant l'avantage dans la prise de décision basée sur les données. N’oubliez pas que dans le domaine de la collecte et de l’analyse des données, le bon partenaire fait toute la différence.
Bonne chasse aux données !