
Sélection et configuration des moteurs d'inférence pour les LLM
Publié: 2024-04-02Introduction aux moteurs d'inférence
De nombreuses techniques d'optimisation ont été développées pour atténuer les inefficacités qui se produisent aux différentes étapes du processus d'inférence. Il est difficile de mettre à l'échelle l'inférence à l'échelle avec les techniques/transformateurs vanille. Les moteurs d'inférence regroupent les optimisations dans un seul package et nous facilitent le processus d'inférence.
Pour un très petit ensemble de tests ad hoc ou une référence rapide, nous pouvons utiliser le code du transformateur Vanilla pour faire l'inférence.
Le paysage des moteurs d'inférence évolue rapidement, car nous avons plusieurs choix, il est important de tester et de présélectionner le meilleur des meilleurs pour des cas d'utilisation spécifiques. Vous trouverez ci-dessous quelques expériences de moteurs d'inférence que nous avons réalisées et les raisons pour lesquelles nous avons découvert pourquoi cela a fonctionné dans notre cas.
Pour notre modèle Vicuna-7B affiné, nous avons essayé
- TGI
- vLLM
- Aphrodite
- Optimum-Nvidia
- PowerInfer
- LAMACPP
- Ctranslate2
Nous avons parcouru la page github et son guide de démarrage rapide pour configurer ces moteurs, PowerInfer, LlaamaCPP, Ctranslate2 ne sont pas très flexibles et ne prennent pas en charge de nombreuses techniques d'optimisation telles que le traitement par lots continu, l'attention paginée et les performances inférieures à la moyenne par rapport aux autres moteurs mentionnés. .
Pour obtenir un débit plus élevé, le moteur/serveur d'inférence doit maximiser la mémoire et les capacités de calcul et le client et le serveur doivent fonctionner de manière parallèle/asynchrone pour répondre aux requêtes afin que le serveur reste toujours opérationnel. Comme mentionné précédemment, sans l'aide de techniques d'optimisation telles que PagedAttention, Flash Attention, le traitement par lots continu, cela conduira toujours à des performances sous-optimales.
TGI, vLLM et Aphrodite sont des candidats plus appropriés à cet égard et en effectuant plusieurs expériences indiquées ci-dessous, nous avons trouvé la configuration optimale pour tirer le maximum de performances de l'inférence. Des techniques telles que le traitement par lots continu et l'attention paginée sont activées par défaut, le décodage spéculatif doit être activé manuellement dans le moteur d'inférence pour les tests ci-dessous.
Analyse comparative des moteurs d'inférence
TGI
Pour utiliser TGI, on peut passer par la section 'Get Started' de la page github, ici docker est le moyen le plus simple de configurer et d'utiliser le moteur TGI.
Arguments du lanceur de génération de texte -> cette liste répertorie les différents paramètres que nous pouvons utiliser côté serveur. Peu d'importants,
- –max-input-length : détermine la longueur maximale d'entrée dans le modèle, cela nécessite des modifications dans la plupart des cas, la valeur par défaut étant 1024.
- –max-total-jetons : max nombre total de jetons, c'est-à-dire longueur du jeton d'entrée + sortie.
- –speculate, –quantiz, –max-concurrent-requests -> la valeur par défaut est 128 seulement, ce qui est évidemment inférieur.
Pour démarrer un modèle local optimisé,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –spéculer 2
Pour démarrer un modèle à partir du hub,
modèle = "lmsys/vicuna-7b-v1.5" ; volume=$PWD/données ; token=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –spéculer 2
Vous pouvez demander à chatGPT d'expliquer la commande ci-dessus pour une compréhension plus détaillée. Ici, nous démarrons le serveur d'inférence sur le port 9091. Et nous pouvons utiliser un client de n'importe quelle langue pour publier une demande sur le serveur. API d'inférence de génération de texte -> mentionne tous les points de terminaison et paramètres de charge utile pour la demande.
Par exemple
payload="<invite ici>"
curl -XPOST « 0.0.0.0:9091/generate » -H « Content-Type : application/json » -d « {« inputs » : $payload, « paramètres » : {« max_new_tokens » : 400, « do_sample » : false "best_of" : null, "repetition_penalty" : 1, "return_full_text" : false, "seed" : null, "stop_sequences" : null, "température" : 0,1, "top_k" : 100, "top_p" : 0,3, " truncate : null, "typique_p": null, "filigrane": faux, "decoder_input_details": faux}}"
Quelques observations,
- La latence augmente avec le nombre maximum de jetons, ce qui est évident que si nous traitons un texte long, le temps global augmentera.
- Spéculer aide, mais cela dépend du cas d'utilisation et de la distribution entrées-sorties.
- La quantification Eetq contribue le plus à augmenter le débit.
- Si vous disposez d'un multi-GPU, exécuter 1 API sur chaque GPU et avoir ces API multi-GPU derrière un équilibreur de charge entraîne un débit plus élevé que le partitionnement par TGI lui-même.
vLLM
Pour démarrer un serveur vLLM, nous pouvons utiliser un serveur/docker API REST compatible OpenAI. C'est très simple à démarrer, suivez Déploiement avec Docker — vLLM, si vous comptez utiliser un modèle local, puis attachez le volume et utilisez le chemin comme nom de modèle,
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – modèle / modèle
Ci-dessus démarrera un serveur vLLM sur le port 8000 mentionné, comme toujours, vous pouvez jouer avec les arguments.
Faire une demande de publication avec,
« `coquille
payload="<invite ici>"
curl -XPOST -m 1200 « 0.0.0.0:8000/v1/completions » -H « Content-Type : application/json » -d « {« prompt » : $payload, « model » : »/model » , « max_tokens " : 400, " top_p " : 0,3, " top_k " : 100, " température " : 0,1} "
"`
Aphrodite
« `coquille
pip installer le moteur aphrodite
python -m aphrodite.endpoints.openai.api_server –modèle PygmalionAI/pygmalion-2-7b
"`
Ou
"`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc host alpindale/aphrodite-engine

"`
Aphrodite fournit à la fois l'installation de pip et de docker, comme mentionné dans la section de démarrage. Docker est généralement relativement plus facile à démarrer et à tester. Les options d'utilisation et les options du serveur nous aident à faire des demandes.
- Aphrodite et vLLM utilisent tous deux des charges utiles basées sur un serveur openAI, vous pouvez donc consulter sa documentation.
- Nous avons essayé deepspeed-mii, car il est dans un état de transition (lorsque nous avons essayé) de l'ancienne base de code à la nouvelle base de code, il ne semble pas fiable et facile à utiliser.
- Optimum-NVIDIA ne prend pas en charge les autres optimisations majeures et entraîne des performances sous-optimales, lien de référence.
- Ajout d'un résumé, le code que nous avons utilisé pour effectuer les requêtes parallèles ad hoc.
Métriques et mesures
Nous voulons essayer et trouver :
- Numéro optimal. de threads pour le serveur client/moteur d'inférence.
- Comment le débit augmente par rapport à l'augmentation de la mémoire
- Comment le débit augmente par rapport aux cœurs tenseurs.
- Effet des threads par rapport aux demandes parallèles du client.
Un moyen très simple d'observer l'utilisation est de la regarder via les utilitaires Linux nvidia-smi, nvtop, cela nous indiquera la mémoire occupée, l'utilisation du calcul, le taux de transfert de données, etc.
Une autre façon consiste à profiler le processus à l'aide du GPU avec nsys.
| S. Non | GPU | Mémoire vRAM | Moteur d'inférence | Sujets | Temps (s) | Spéculer |
| 1 | A6000 | 48/48 Go | TGI | 24 | 664 | – |
| 2 | A6000 | 48/48 Go | TGI | 64 | 561 | – |
| 3 | A6000 | 48/48 Go | TGI | 128 | 554 | – |
| 4 | A6000 | 48/48 Go | TGI | 256 | 568 | – |
Sur la base des expériences ci-dessus, 128/256 threads sont meilleurs qu'un nombre de threads inférieur et au-delà de 256, la surcharge commence à contribuer à un débit réduit. Cela dépend du CPU et du GPU et nécessite sa propre expérience. | ||||||
| 5 | A6000 | 48/48 Go | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48/48 Go | TGI | 128 | 945 | 8 |
Une valeur spéculative plus élevée entraîne davantage de rejets pour notre modèle affiné et réduit ainsi le débit. 1/2, car spéculer sur la valeur est acceptable, cela dépend du modèle et il n'est pas garanti que le fonctionnement soit identique dans tous les cas d'utilisation. Mais la conclusion est que le décodage spéculatif améliore le débit. | ||||||
| 7 | 3090 | 24/24 Go | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24 Go | TGI | 128 | 481 | 2 |
Le 4090 possède moins de vRAM que le A6000, mais il surpasse en raison d'un nombre de cœurs tenseurs et d'une vitesse de bande passante mémoire plus élevés. | ||||||
| 8 | A6000 | 24/48 Go | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2 x 24/48 Go | TGI | 128 | 1205 | 2 |
Installation et configuration de TGI pour un débit élevé
Configurez les requêtes asynchrones dans un langage de script de votre choix comme python/ruby et en utilisant le même fichier pour la configuration, nous avons trouvé :
- Le temps nécessaire augmente par rapport à la longueur de sortie maximale de la génération de séquence.
- 128/256 threads sur le client et le serveur sont meilleurs que 24, 64, 512. Lors de l'utilisation de threads inférieurs, le calcul est sous-utilisé et au-delà d'un seuil comme 128, la surcharge devient plus élevée et donc le débit est réduit.
- Il y a une amélioration de 6 % lors du passage des requêtes asynchrones aux requêtes parallèles en utilisant « GNU parallèle » au lieu du threading dans des langages comme Go, Python/Ruby.
- Le 4090 a un débit 12 % plus élevé que l’A6000. Le 4090 possède moins de vRAM que le A6000, mais il surpasse en raison d'un nombre de cœurs tenseurs et d'une vitesse de bande passante mémoire plus élevés.
- Étant donné que l'A6000 dispose de 48 Go de vRAM, pour déterminer si la RAM supplémentaire contribue ou non à améliorer le débit, nous avons essayé d'utiliser des fractions de mémoire GPU dans l'expérience 8 du tableau. Nous constatons que la RAM supplémentaire contribue à l'amélioration, mais pas de manière linéaire. De plus, lorsque vous essayez de diviser, c'est-à-dire d'héberger 2 API sur le même GPU en utilisant la moitié de la mémoire pour chaque API, cela se comporte comme 2 API séquentielles en cours d'exécution, au lieu d'accepter les demandes en parallèle.
Observations et mesures
Vous trouverez ci-dessous des graphiques pour certaines expériences et le temps nécessaire pour terminer un ensemble d'entrées fixe, il est préférable de réduire le temps nécessaire.
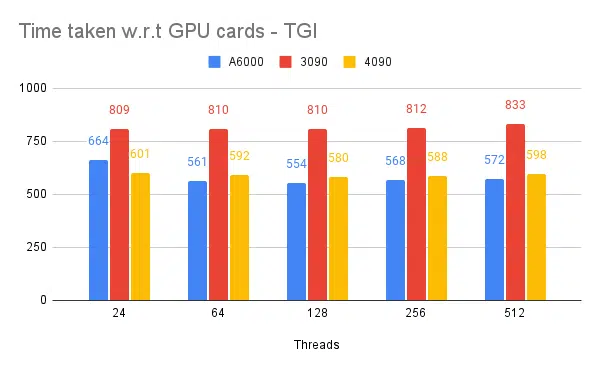
- Les threads côté client sont mentionnés. Côté serveur, nous devons le mentionner lors du démarrage du moteur d'inférence.
Tests spéculatifs :

Tests de plusieurs moteurs d'inférence :
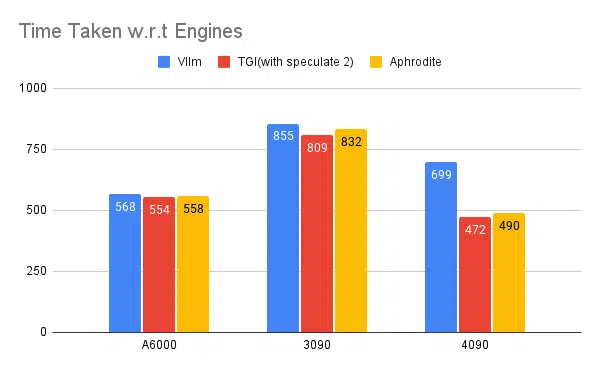
Même type d'expériences effectuées avec d'autres moteurs comme vLLM et Aphrodite, nous observons un type de résultats similaire. Au moment de la rédaction de cet article, vLLM et Aphrodite ne prennent pas encore en charge le décodage spéculatif, ce qui nous laisse choisir TGI car il offre un débit plus élevé que le repos dû. au décodage spéculatif.
De plus, vous pouvez configurer des profileurs GPU pour améliorer l'observabilité, aidant ainsi à identifier les zones présentant une utilisation excessive des ressources et à optimiser les performances. Pour en savoir plus : Outils de développement Nvidia Nsight — Max Katz
Conclusion
Nous constatons que le paysage de la génération d'inférences évolue constamment et que l'amélioration du débit dans LLM nécessite une bonne compréhension du GPU, des mesures de performances, des techniques d'optimisation et des défis associés aux tâches de génération de texte. Cela aide à choisir les bons outils pour le travail. En comprenant les composants internes du GPU et la façon dont ils correspondent à l'inférence LLM, comme l'exploitation des cœurs tenseurs et l'optimisation de la bande passante mémoire, les développeurs peuvent choisir le GPU rentable et optimiser efficacement les performances.
Différentes cartes GPU offrent des capacités variables, et comprendre les différences est crucial pour sélectionner le matériel le plus adapté à des tâches spécifiques. Des techniques telles que le traitement par lots continu, l'attention paginée, la fusion du noyau et l'attention flash offrent des solutions prometteuses pour surmonter les défis émergents et améliorer l'efficacité. TGI semble le meilleur choix pour notre cas d'utilisation sur la base des expériences et des résultats que nous obtenons.
Lisez d’autres articles liés au grand modèle de langage :
Comprendre l'architecture GPU pour l'optimisation de l'inférence LLM
Techniques avancées pour améliorer le débit LLM