
Guide étape par étape pour créer un robot d'exploration Web
Publié: 2023-12-05Dans le tissu complexe d’Internet, où les informations sont dispersées sur d’innombrables sites Web, les robots d’exploration du Web apparaissent comme des héros méconnus, travaillant avec diligence pour organiser, indexer et rendre accessible cette richesse de données. Cet article se lance dans une exploration des robots d'exploration Web, mettant en lumière leur fonctionnement fondamental, distinguant l'exploration du Web et le scraping Web, et fournissant des informations pratiques telles qu'un guide étape par étape pour créer un robot d'exploration Web simple basé sur Python. Au fur et à mesure que nous approfondirons, nous découvrirons les capacités d'outils avancés tels que Scrapy et découvrirons comment PromptCloud élève l'exploration du Web à une échelle industrielle.
Qu'est-ce qu'un robot d'exploration Web
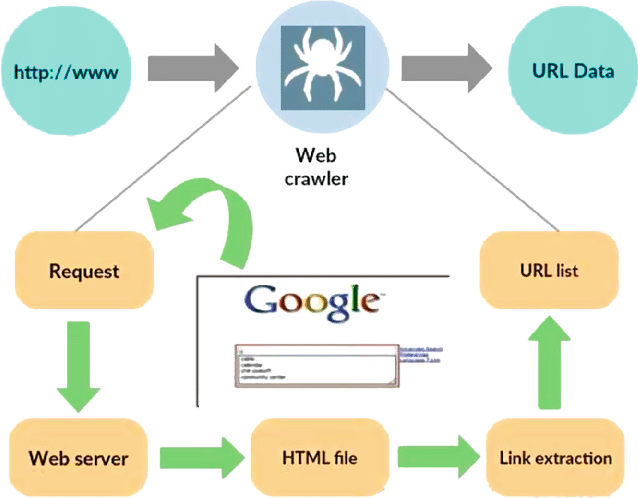
Source : https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Un robot d'exploration Web, également connu sous le nom d'araignée ou de robot, est un programme spécialisé conçu pour naviguer de manière systématique et autonome sur la vaste étendue du World Wide Web. Sa fonction principale est de parcourir des sites Web, de collecter des données et d'indexer des informations à diverses fins, telles que l'optimisation des moteurs de recherche, l'indexation de contenu ou l'extraction de données.
À la base, un robot d'exploration Web imite les actions d'un utilisateur humain, mais à un rythme beaucoup plus rapide et efficace. Il commence son voyage à partir d'un point de départ désigné, souvent appelé URL de départ, puis suit des hyperliens d'une page Web à une autre. Ce processus de suivi des liens est récursif, permettant au robot d'exploration d'explorer une partie importante d'Internet.
Lorsque le robot visite les pages Web, il extrait et stocke systématiquement les données pertinentes, qui peuvent inclure du texte, des images, des métadonnées, etc. Les données extraites sont ensuite organisées et indexées, ce qui permet aux moteurs de recherche de récupérer et de présenter plus facilement les informations pertinentes aux utilisateurs lorsqu'ils sont interrogés.
Les robots d'exploration Web jouent un rôle central dans les fonctionnalités des moteurs de recherche comme Google, Bing et Yahoo. En explorant continuellement et systématiquement le Web, ils garantissent que les index des moteurs de recherche sont à jour, fournissant ainsi aux utilisateurs des résultats de recherche précis et pertinents. De plus, les robots d'exploration Web sont utilisés dans diverses autres applications, notamment l'agrégation de contenu, la surveillance de sites Web et l'exploration de données.
L'efficacité d'un robot d'exploration Web repose sur sa capacité à naviguer dans diverses structures de sites Web, à gérer le contenu dynamique et à respecter les règles définies par les sites Web via le fichier robots.txt, qui décrit les parties d'un site qui peuvent être explorées. Comprendre le fonctionnement des robots d'exploration Web est fondamental pour apprécier leur importance pour rendre le vaste Web d'informations accessible et organisé.
Comment fonctionnent les robots d'exploration Web
Les robots d'exploration du Web, également connus sous le nom d'araignées ou de robots, fonctionnent via un processus systématique de navigation sur le World Wide Web pour recueillir des informations sur les sites Web. Voici un aperçu du fonctionnement des robots d’exploration Web :
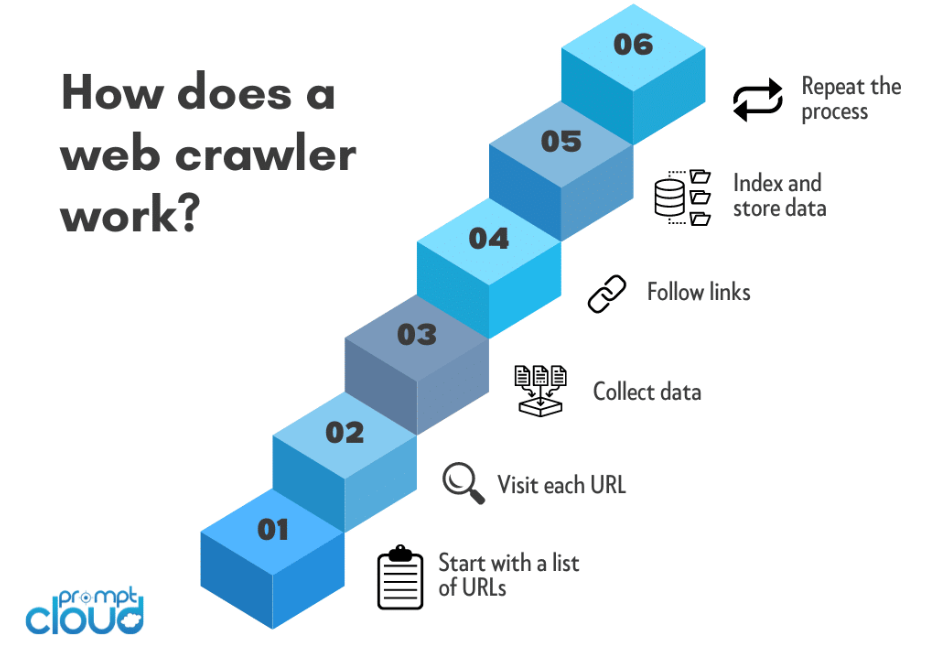
Sélection de l'URL de départ :
Le processus d'exploration du Web commence généralement par une URL de départ. Il s’agit de la page Web ou du site Web initial à partir duquel le robot commence son parcours.
Requête HTTP :
Le robot envoie une requête HTTP à l'URL de départ pour récupérer le contenu HTML de la page Web. Cette requête est similaire aux requêtes faites par les navigateurs Web lors de l’accès à un site Web.
Analyse HTML :
Une fois le contenu HTML récupéré, le robot l'analyse pour extraire les informations pertinentes. Cela implique de décomposer le code HTML dans un format structuré que le robot peut parcourir et analyser.
Extraction d'URL :
Le robot identifie et extrait les hyperliens (URL) présents dans le contenu HTML. Ces URL représentent des liens vers d'autres pages que le robot visitera ultérieurement.
File d'attente et planificateur :
Les URL extraites sont ajoutées à une file d'attente ou à un planificateur. La file d'attente garantit que le robot visite les URL dans un ordre spécifique, en donnant souvent la priorité aux URL nouvelles ou non visitées.
Récursion :
Le robot suit les liens dans la file d'attente, répétant le processus d'envoi de requêtes HTTP, d'analyse du contenu HTML et d'extraction de nouvelles URL. Ce processus récursif permet au robot d'exploration de naviguer à travers plusieurs couches de pages Web.
Extraction de données:
Lorsque le robot parcourt le Web, il extrait les données pertinentes de chaque page visitée. Le type de données extraites dépend de l'objectif du robot d'exploration et peut inclure du texte, des images, des métadonnées ou tout autre contenu spécifique.
Indexation du contenu :
Les données collectées sont organisées et indexées. L'indexation implique la création d'une base de données structurée qui facilite la recherche, la récupération et la présentation d'informations lorsque les utilisateurs soumettent des requêtes.
Respectant Robots.txt :
Les robots d'exploration Web adhèrent généralement aux règles spécifiées dans le fichier robots.txt d'un site Web. Ce fichier fournit des directives sur les zones du site qui peuvent être explorées et celles qui doivent être exclues.
Retards d’exploration et politesse :
Pour éviter de surcharger les serveurs et de provoquer des perturbations, les robots intègrent souvent des mécanismes de retard d'exploration et de politesse. Ces mesures garantissent que le robot interagit avec les sites Web de manière respectueuse et non perturbatrice.
Les robots d'exploration Web parcourent systématiquement le Web, suivent les liens, extraient des données et créent un index organisé. Ce processus permet aux moteurs de recherche de fournir des résultats précis et pertinents aux utilisateurs en fonction de leurs requêtes, faisant ainsi des robots d'exploration Web un élément fondamental de l'écosystème Internet moderne.

Exploration Web et grattage Web

Source : https://research.aimultiple.com/web-crawling-vs-web-scraping/
Bien que l'exploration du Web et le grattage du Web soient souvent utilisés de manière interchangeable, ils répondent à des objectifs distincts. L'exploration du Web consiste à naviguer systématiquement sur le Web pour indexer et collecter des informations, tandis que le web scraping se concentre sur l'extraction de données spécifiques à partir de pages Web. Essentiellement, l’exploration du Web consiste à explorer et à cartographier le Web, tandis que le web scraping consiste à récolter des informations ciblées.
Construire un robot d'exploration Web
La création d'un simple robot d'exploration Web en Python implique plusieurs étapes, de la configuration de l'environnement de développement au codage de la logique du robot. Vous trouverez ci-dessous un guide détaillé pour vous aider à créer un robot d'exploration Web de base à l'aide de Python, en utilisant la bibliothèque de requêtes pour effectuer des requêtes HTTP et BeautifulSoup pour l'analyse HTML.
Étape 1 : configurer l'environnement
Assurez-vous que Python est installé sur votre système. Vous pouvez le télécharger depuis python.org. De plus, vous devrez installer les bibliothèques requises :
pip install requests beautifulsoup4
Étape 2 : Importer des bibliothèques
Créez un nouveau fichier Python (par exemple, simple_crawler.py) et importez les bibliothèques nécessaires :
import requests from bs4 import BeautifulSoup
Étape 3 : Définir la fonction du robot d'exploration
Créez une fonction qui prend une URL en entrée, envoie une requête HTTP et extrait les informations pertinentes du contenu HTML :
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Étape 4 : tester le robot d'exploration
Fournissez un exemple d'URL et appelez la fonction simple_crawler pour tester le robot :
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Étape 5 : Exécutez le robot d'exploration
Exécutez le script Python dans votre terminal ou invite de commande :
python simple_crawler.py
Le robot d'exploration récupérera le contenu HTML de l'URL fournie, l'analysera et imprimera le titre. Vous pouvez étendre le robot d'exploration en ajoutant davantage de fonctionnalités pour extraire différents types de données.
Exploration Web avec Scrapy
L'exploration du Web avec Scrapy ouvre la porte à un cadre puissant et flexible conçu spécifiquement pour un scraping Web efficace et évolutif. Scrapy simplifie la complexité de la création de robots d'exploration Web, en offrant un environnement structuré pour créer des robots d'exploration capables de naviguer sur des sites Web, d'extraire des données et de les stocker de manière systématique. Voici un aperçu plus approfondi de l'exploration du Web avec Scrapy :
Installation:
Avant de commencer, assurez-vous que Scrapy est installé. Vous pouvez l'installer en utilisant :
pip install scrapy
Création d'un projet Scrapy :
Lancer un projet Scrapy :
Ouvrez un terminal et accédez au répertoire dans lequel vous souhaitez créer votre projet Scrapy. Exécutez la commande suivante :
scrapy startproject your_project_name
Cela crée une structure de projet de base avec les fichiers nécessaires.
Définir l'araignée :
Dans le répertoire du projet, accédez au dossier spiders et créez un fichier Python pour votre spider. Définissez une classe spider en sous-classant scrapy.Spider et en fournissant des détails essentiels tels que le nom, les domaines autorisés et les URL de démarrage.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Extraction de données :
Utilisation des sélecteurs :
Scrapy utilise de puissants sélecteurs pour extraire des données du HTML. Vous pouvez définir des sélecteurs dans la méthode d'analyse du spider pour capturer des éléments spécifiques.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Cet exemple extrait le contenu textuel de la balise <title>.
Liens suivants :
Scrapy simplifie le processus de suivi des liens. Utilisez la méthode suivante pour accéder à d’autres pages.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Exécuter l'araignée :
Exécutez votre spider à l'aide de la commande suivante depuis le répertoire du projet :
scrapy crawl your_spider
Scrapy lancera le spider, suivra les liens et exécutera la logique d'analyse définie dans la méthode d'analyse.
L'exploration du Web avec Scrapy offre un cadre robuste et extensible pour gérer des tâches de scraping complexes. Son architecture modulaire et ses fonctionnalités intégrées en font un choix privilégié pour les développeurs engagés dans des projets sophistiqués d'extraction de données Web.
Exploration Web à grande échelle
L'exploration du Web à grande échelle présente des défis uniques, en particulier lorsqu'il s'agit de traiter une grande quantité de données réparties sur de nombreux sites Web. PromptCloud est une plateforme spécialisée conçue pour rationaliser et optimiser le processus d'exploration Web à grande échelle. Voici comment PromptCloud peut vous aider à gérer des initiatives d'exploration Web à grande échelle :
- Évolutivité
- Extraction et enrichissement des données
- Qualité et précision des données
- Gestion des infrastructures
- Facilité d'utilisation
- Conformité et éthique
- Surveillance et reporting en temps réel
- Assistance et maintenance
PromptCloud est une solution robuste pour les organisations et les particuliers cherchant à effectuer une exploration Web à grande échelle. En relevant les principaux défis associés à l'extraction de données à grande échelle, la plateforme améliore l'efficacité, la fiabilité et la gérabilité des initiatives d'exploration du Web.
En résumé
Les robots d'exploration Web sont des héros méconnus du vaste paysage numérique, naviguant avec diligence sur le Web pour indexer, rassembler et organiser des informations. À mesure que l'ampleur des projets d'exploration du Web augmente, PromptCloud intervient en tant que solution, offrant évolutivité, enrichissement des données et conformité éthique pour rationaliser les initiatives à grande échelle. Contactez-nous à sales@promptcloud.com