
Le rôle du Web Scraping dans l'amélioration de la précision des modèles d'IA
Publié: 2023-12-27L’IA évolue constamment, alimentée par les immenses données nécessaires pour affiner l’apprentissage automatique. Ce processus d'apprentissage implique de reconnaître des modèles et de prendre des décisions éclairées.
Entrez dans le web scraping, un acteur essentiel dans la recherche de données. Il s’agit d’extraire de vastes informations de sites Web, un trésor pour former des modèles d’IA. L’harmonie entre l’IA et le web scraping souligne l’essence de l’apprentissage automatique contemporain, basée sur les données. À mesure que l’IA progresse, la soif d’ensembles de données variés augmente, faisant du web scraping un atout indispensable pour les développeurs qui créent des systèmes d’IA plus précis et plus efficaces.
L'évolution du Web Scraping : du manuel à l'amélioration de l'IA
Le développement du web scraping reflète les avancées technologiques. Les premières méthodes étaient basiques et nécessitaient une extraction manuelle des données, une tâche souvent longue et sujette aux erreurs. À mesure que l’Internet se développait rapidement, ces techniques ne parvenaient pas à suivre le rythme de l’augmentation du volume de données. Des scripts et des robots ont été introduits pour automatiser le scraping, mais ils manquaient de sophistication.
Entrez dans l’IA du web scraping, qui révolutionne la collecte de données. L’apprentissage automatique permet désormais d’analyser des données complexes et non structurées et de leur donner un sens efficace. Ce changement accélère non seulement la collecte de données, mais améliore également la qualité des données extraites, permettant des applications plus sophistiquées et fournissant un terrain d'alimentation plus riche pour les modèles d'IA qui apprennent continuellement à partir d'ensembles de données vastes et nuancés.
Source de l'image : https://www.scrapingdog.com/
Comprendre les technologies d'IA dans le Web Scraping
Grâce à l’intelligence artificielle, les outils de web scraping sont devenus plus puissants. L’IA automatise la reconnaissance des formes lors de l’extraction des données, ce qui rend l’identification des informations pertinentes plus rapide et plus précise. Les scrapers Web basés sur l'IA peuvent :
- Adaptez-vous aux différentes mises en page de sites Web à l’aide de l’apprentissage automatique, réduisant ainsi le besoin de conception manuelle de modèles.
- Utilisez le traitement du langage naturel (NLP) pour comprendre et catégoriser les données textuelles, améliorant ainsi la qualité des données récoltées.
- Utilisez les capacités de reconnaissance d'images pour extraire du contenu visuel, ce qui peut être critique dans certains contextes d'analyse de données.
- Mettez en œuvre des algorithmes de détection d’anomalies pour identifier et gérer les valeurs aberrantes ou les erreurs d’extraction de données, garantissant ainsi l’intégrité des données.
Grâce à la puissance de l'IA, le web scraping devient plus puissant et plus adaptable, répondant ainsi aux exigences étendues en matière de données des modèles d'IA avancés d'aujourd'hui.
Le rôle de l'apprentissage automatique dans l'extraction intelligente de données
L'apprentissage automatique révolutionne l'extraction de données en permettant aux systèmes de reconnaître, comprendre et extraire de manière indépendante des informations pertinentes. Les principales contributions comprennent :
- Reconnaissance de modèles : les algorithmes d'apprentissage automatique excellent dans la reconnaissance de modèles et d'anomalies dans de grands ensembles de données, ce qui les rend idéaux pour identifier les points de données pertinents lors du web scraping.
- Traitement du langage naturel (NLP) : grâce à la PNL, l'apprentissage automatique peut comprendre et interpréter le langage humain, facilitant ainsi l'extraction d'informations à partir de sources de données non structurées telles que les médias sociaux.
- Apprentissage adaptatif : à mesure que les modèles d'apprentissage automatique sont exposés à davantage de données, ils apprennent et améliorent leur précision, garantissant ainsi que le processus d'extraction de données devient plus efficace au fil du temps.
- Réduire les erreurs humaines : grâce à l'apprentissage automatique, la probabilité d'erreurs associées à l'extraction manuelle des données est considérablement réduite, améliorant ainsi la qualité de l'ensemble de données pour les modèles d'IA.
Source de l'image : https://research.aimultiple.com/
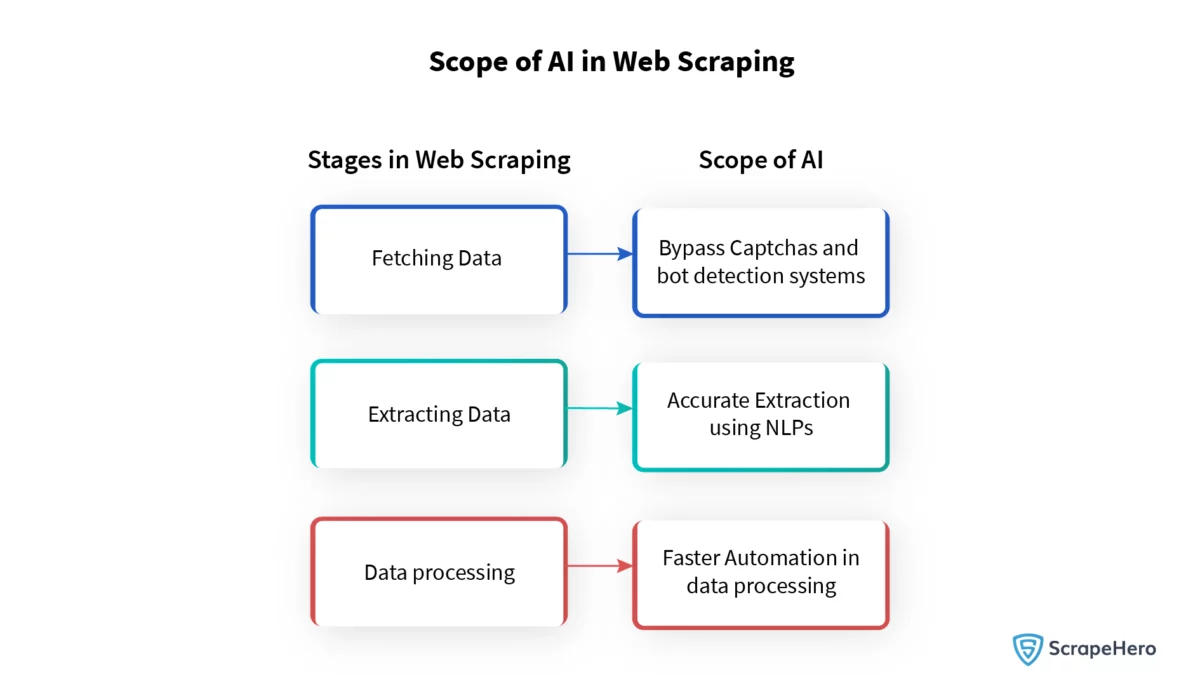
Reconnaissance de formes pilotée par l'IA pour un grattage efficace
Le Web scraping joue un rôle essentiel pour répondre à la demande croissante de données dans les modèles d’apprentissage automatique. Au premier plan se trouve la reconnaissance de formes basée sur l’IA, qui rationalise l’extraction de données avec une efficacité remarquable. Cette technique avancée identifie et catégorise de grandes quantités de données avec une implication humaine minimale.
Tirant parti d'algorithmes complexes, l'IA de web scraping navigue rapidement dans les pages Web, reconnaît les modèles et extrait des ensembles de données structurés. Ces systèmes automatisés fonctionnent non seulement plus rapidement, mais améliorent également considérablement la précision, minimisant les erreurs par rapport aux méthodes de grattage manuel. À mesure que l’IA évolue, sa capacité à discerner des modèles complexes continuera de remodeler le paysage du web scraping et de l’acquisition de données.
Traitement du langage naturel pour l'agrégation de contenu
La fonction cruciale du traitement du langage naturel (NLP) arrive au premier plan dans l'agrégation de contenu, permettant aux systèmes d'IA de comprendre, d'interpréter et d'organiser efficacement les données. Il donne aux scrapers la capacité de distinguer les informations pertinentes des discussions non pertinentes. En analysant la sémantique et la syntaxe du texte, la PNL classe le contenu, extrait les entités clés et résume les informations.

Ces données distillées deviennent le matériel de formation de base pour les modèles qui apprennent à reconnaître des modèles, à anticiper les requêtes des utilisateurs et à fournir des réponses pertinentes. Par conséquent, l’agrégation de contenu basée sur la PNL est essentielle au développement de modèles d’IA plus intelligents et contextuels. Il facilite une approche ciblée de la collecte de données, affinant les données brutes qui alimentent l’appétit insatiable de données de l’IA contemporaine.
Surmonter les défis des captchas et du contenu dynamique avec l'IA
Les captchas et le contenu dynamique présentent de formidables obstacles à un web scraping efficace. Ces mécanismes sont conçus pour différencier les utilisateurs humains des services automatisés, perturbant souvent les efforts de collecte de données. Cependant, les progrès de l’intelligence artificielle ont introduit des solutions sophistiquées :
- Les algorithmes d’apprentissage automatique se sont considérablement améliorés dans l’interprétation des captchas visuels, imitant les capacités humaines de reconnaissance de formes.
- Les outils basés sur l'IA peuvent désormais s'adapter au contenu dynamique en apprenant les structures des pages et en prédisant les changements d'emplacement des données.
- Certains systèmes utilisent des réseaux contradictoires génératifs (GAN) pour former des modèles capables de résoudre des captchas complexes.
- Les techniques de traitement du langage naturel (NLP) aident à comprendre la sémantique des textes générés dynamiquement, facilitant ainsi une extraction précise des données.
Alors que la lutte continue se déroule entre les créateurs de captcha et les développeurs d’IA, chaque progrès de la technologie captcha est contré par une contre-mesure plus astucieuse et plus agile, basée sur l’IA. Cette interaction dynamique garantit un flux transparent de données, alimentant l’expansion incessante du secteur de l’IA.
Améliorer la qualité et la précision des données grâce à la puissance des applications d'IA
Les applications d'intelligence artificielle (IA) améliorent considérablement la qualité et la précision des données, ce qui est essentiel pour former des modèles efficaces. En employant des algorithmes sophistiqués, l’IA peut :
- Détectez et corrigez les incohérences dans de grands ensembles de données.
- Filtrez les informations non pertinentes en vous concentrant sur les sous-ensembles de données essentiels à la compréhension du modèle.
- Validez les données par rapport à des critères de qualité préétablis.
- Effectuez un nettoyage des données en temps réel, ce qui garantit que les ensembles de données d'entraînement restent à jour et précis.
- Utilisez l’apprentissage non supervisé pour identifier des modèles ou des anomalies qui pourraient échapper à l’examen humain.
L’utilisation de l’IA dans la préparation des données ne rend pas seulement le processus plus fluide ; il améliore la qualité des informations obtenues à partir des données, ce qui donne lieu à des modèles d'IA plus intelligents et plus fiables.
Augmenter les opérations de Web Scraping avec l'intégration de l'IA
L'intégration de l'IA dans les pratiques de web scraping améliore considérablement l'efficacité et l'évolutivité des processus de collecte de données. Les systèmes basés sur l'IA peuvent s'adapter à différentes présentations de sites Web et extraire les données avec précision, même si le site subit des modifications. Cette adaptabilité provient d'algorithmes d'apprentissage automatique qui apprennent des modèles et des anomalies au cours du processus de scraping.
De plus, l’IA peut hiérarchiser et catégoriser les points de données, reconnaissant ainsi rapidement les informations précieuses. Les compétences en traitement du langage naturel (NLP) permettent aux outils de scraping de comprendre et de traiter le langage humain, permettant ainsi l'extraction de sentiments ou d'intentions à partir de données textuelles. À mesure que les tâches de scraping augmentent en complexité et en volume, l'intégration de l'IA garantit que ces tâches sont effectuées avec une surveillance manuelle réduite, conduisant à une opération plus rationalisée et plus rentable. La mise en œuvre de tels systèmes intelligents facilite :
- Automatiser l’identification et l’extraction des données pertinentes
- Apprendre et s'adapter continuellement aux nouvelles structures Web
- Analyser et interpréter des données non structurées avec des techniques de PNL
- Améliorer la précision et réduire le besoin d’intervention humaine
Tendances à venir : le paysage futur de l'IA de Web Scraping
Alors que nous naviguons dans le domaine en constante évolution de l’intelligence artificielle, un point central émerge sur les progrès remarquables de l’IA de web scraping. Explorez ces tendances cruciales qui façonnent l’avenir :
- Compréhension complète : l'IA se développe pour comprendre les vidéos, les images et l'audio de manière contextuelle.
- Apprentissage adaptatif : l'IA ajuste les stratégies de scraping en fonction des structures des sites Web, réduisant ainsi l'intervention humaine.
- Extraction de données précise : les algorithmes sont affinés pour une extraction de données précise et pertinente.
- Intégration transparente : les outils de scraping basés sur l'IA s'intègrent de manière transparente aux plates-formes d'analyse de données.
- Acquisition de données éthiques : l'IA intègre des directives éthiques pour le consentement des utilisateurs et la protection des données.
Source de l'image : https://www.scrapehero.com/
Découvrez la synergie du web scraping et de l’IA pour vos besoins en données. Contactez PromptCloud à sales@promptcloud.com pour des services de web scraping de pointe qui améliorent la précision de vos modèles d'IA.
FAQ :
L’IA peut-elle faire du web scraping ?
Certes, l’IA est apte à gérer les tâches de web scraping. Équipés d'algorithmes avancés, les systèmes d'IA peuvent parcourir indépendamment des sites Web, identifier des modèles et extraire des données pertinentes avec une efficacité notable. Cette capacité marque une avancée significative, amplifiant la rapidité, la précision et la flexibilité des procédures d’extraction de données.
Le web scraping est-il illégal ?
En ce qui concerne la légalité du web scraping, le paysage est nuancé. Le web scraping lui-même n'est pas intrinsèquement illégal, mais la légalité dépend de la manière dont il est exécuté. Un scraping responsable et éthique, aligné sur les conditions d’utilisation des sites Web ciblés, est crucial pour éviter les complications juridiques. Il est essentiel d’aborder le web scraping avec un état d’esprit attentif et conforme.
ChatGPT peut-il effectuer du web scraping ?
Quant à ChatGPT, il ne s'engage pas dans des activités de web scraping. Son point fort réside dans la compréhension et la génération du langage naturel, fournissant des réponses basées sur les informations reçues. Pour les tâches réelles de web scraping, des outils et une programmation spécialisés sont nécessaires.
Combien coûte Scraper AI ?
Lorsque l’on considère le coût des services d’IA de scraping, il est important de prendre en compte des variables telles que la complexité de la tâche de scraping, le volume de données à extraire et les besoins de personnalisation spécifiques. Les modèles de tarification peuvent inclure des frais uniques, des plans d'abonnement ou des frais basés sur l'utilisation. Pour un devis personnalisé adapté à vos besoins, il est conseillé de s'adresser à un fournisseur de services de web scraping comme PromptCloud.