
Comprendre l'architecture GPU pour l'optimisation de l'inférence LLM
Publié: 2024-04-02Introduction aux LLM et à l'importance de l'optimisation du GPU
À l'ère actuelle des progrès du traitement du langage naturel (NLP), les grands modèles linguistiques (LLM) sont apparus comme des outils puissants pour une myriade de tâches, de la génération de texte à la réponse aux questions et au résumé. Ce sont plus qu’un prochain générateur de jetons probable. Cependant, la complexité et la taille croissantes de ces modèles posent des défis importants en termes d’efficacité et de performances informatiques.
Dans ce blog, nous approfondissons les subtilités de l'architecture GPU, en explorant comment différents composants contribuent à l'inférence LLM. Nous discuterons des indicateurs de performances clés, tels que la bande passante mémoire et l'utilisation du cœur tensoriel, et expliquerons les différences entre les différentes cartes GPU, vous permettant ainsi de prendre des décisions éclairées lors de la sélection du matériel pour vos tâches de modèles de langage volumineux.
Dans un paysage en évolution rapide où les tâches NLP nécessitent des ressources de calcul toujours croissantes, l'optimisation du débit d'inférence LLM est primordiale. Rejoignez-nous alors que nous nous embarquons dans ce voyage pour libérer tout le potentiel des LLM grâce à des techniques d'optimisation GPU et plongez dans divers outils qui nous permettent d'améliorer efficacement les performances.
Principes essentiels de l'architecture GPU pour les LLM - Connaissez les composants internes de votre GPU
En raison de leur nature à effectuer des calculs parallèles très efficaces, les GPU deviennent le dispositif de choix pour exécuter toutes les tâches d'apprentissage en profondeur. Il est donc important de comprendre la vue d'ensemble de haut niveau de l'architecture GPU pour comprendre les goulots d'étranglement sous-jacents qui surviennent lors de la phase d'inférence. Les cartes Nvidia sont préférées en raison de CUDA (Compute Unified Device Architecture), une plate-forme de calcul parallèle propriétaire et une API développées par NVIDIA, qui permet aux développeurs de spécifier le parallélisme au niveau des threads dans le langage de programmation C, fournissant un accès direct au jeu d'instructions virtuelles et parallèles du GPU. éléments de calcul.
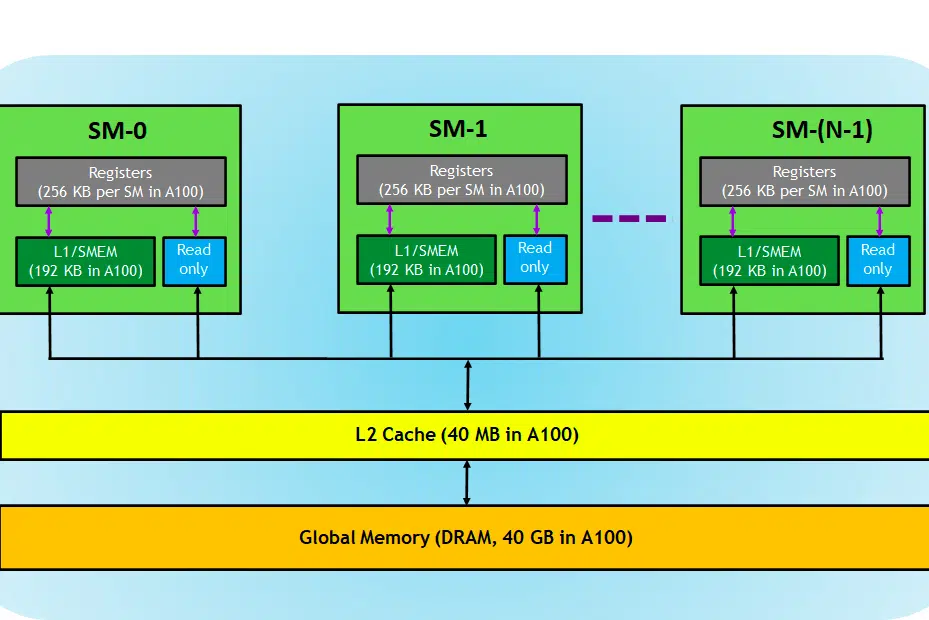
Pour le contexte, nous avons utilisé une carte NVIDIA à titre d'explication car elle est largement préférée pour les tâches de Deep Learning comme déjà indiqué et peu d'autres termes comme Tensor Cores s'appliquent à cela.
Jetons un coup d'œil à la carte GPU, ici dans l'image, nous pouvons voir trois parties principales et (une autre partie cachée majeure) d'un périphérique GPU
- SM (Streaming Multiprocesseurs)
- Cache L2
- Bande passante mémoire
- Mémoire globale (DRAM)
Tout comme votre CPU-RAM joue ensemble, la RAM étant le lieu de résidence des données (c'est-à-dire la mémoire) et le CPU pour les tâches de traitement (c'est-à-dire le processus). Dans un GPU, la mémoire globale à bande passante élevée (DRAM) contient les poids du modèle (par exemple LAMA 7B) qui sont chargés en mémoire et, si nécessaire, ces poids sont transférés à l'unité de traitement (c'est-à-dire le processeur SM) pour les calculs.
Multiprocesseurs de streaming
Un multiprocesseur de streaming ou SM est un ensemble d'unités d'exécution plus petites appelées cœurs CUDA (plate-forme informatique parallèle propriétaire de NVIDIA), ainsi que des unités fonctionnelles supplémentaires responsables de la récupération, du décodage, de la planification et de la répartition des instructions. Chaque SM fonctionne indépendamment et contient son propre fichier de registre, sa mémoire partagée, son cache L1 et son unité de texture. Les SM sont hautement parallélisés, ce qui leur permet de traiter des milliers de threads simultanément, ce qui est essentiel pour atteindre un débit élevé dans les tâches de calcul GPU. Les performances du processeur sont généralement mesurées en FLOPS, le no. d'opérations flottantes qu'il peut effectuer chaque seconde.
Les tâches d'apprentissage profond consistent principalement en opérations tensorielles, c'est-à-dire la multiplication matrice-matrice, nvidia a introduit des cœurs tenseurs dans les GPU de nouvelle génération, qui sont spécifiquement conçus pour effectuer ces opérations tensorielles de manière très efficace. Comme mentionné, les cœurs Tensor sont utiles lorsqu'il s'agit de tâches d'apprentissage en profondeur et au lieu des cœurs CUDA, nous devons vérifier les cœurs Tensor pour déterminer l'efficacité avec laquelle un GPU peut effectuer la formation/inférence du LLM.
Cache L2
Le cache L2 est une mémoire à bande passante élevée partagée entre les SM visant à optimiser l'accès à la mémoire et l'efficacité du transfert de données au sein du système. Il s'agit d'un type de mémoire plus petit et plus rapide, plus proche des unités de traitement (telles que les multiprocesseurs de streaming) par rapport à la DRAM. Il contribue à améliorer l’efficacité globale de l’accès à la mémoire en réduisant le besoin d’accéder à la DRAM, plus lente, pour chaque demande de mémoire.
Bande passante mémoire
Ainsi, les performances dépendent de la rapidité avec laquelle nous pouvons transférer les poids de la mémoire au processeur et de l'efficacité et de la rapidité avec lesquelles le processeur peut traiter les calculs donnés.
Lorsque la capacité de calcul est supérieure/plus rapide que le taux de transfert de données entre la mémoire et le SM, le SM manquera de données à traiter et le calcul sera donc sous-utilisé. Cette situation dans laquelle la bande passante de la mémoire est inférieure au taux de consommation est connue sous le nom de phase liée à la mémoire. . Il est très important de le noter car il s’agit du goulot d’étranglement dominant dans le processus d’inférence.
Au contraire, si le calcul prend plus de temps pour le traitement et si davantage de données sont mises en file d'attente pour le calcul, cet état est une phase liée au calcul .
Pour tirer pleinement parti du GPU, nous devons être dans un état lié au calcul tout en effectuant les calculs en cours aussi efficacement que possible.

Mémoire DRAM
La DRAM sert de mémoire principale dans un GPU, fournissant un grand pool de mémoire pour stocker les données et les instructions nécessaires au calcul. Il est généralement organisé selon une hiérarchie, avec plusieurs banques et canaux de mémoire pour permettre un accès à haut débit.
Pour la tâche d'inférence, la DRAM du GPU détermine la taille d'un modèle que nous pouvons charger et le calcul des FLOPS et de la bande passante détermine le débit que nous pouvons obtenir.
Comparaison des cartes GPU pour les tâches LLM
Pour obtenir des informations sur le nombre de cœurs tenseurs et la vitesse de la bande passante, on peut consulter le livre blanc publié par le fabricant du GPU. Voici un exemple,
| RTXA6000 | RTX4090 | RTX3090 | |
| Taille mémoire | 48 Go | 24 Go | 24 Go |
| Type de mémoire | GDDR6 | GDDR6X | |
| Bande passante | 768,0 Go/s | 1 008 Go/s | 936,2 Go/s |
| Cœurs CUDA/GPU | 10752 | 16384 | 10496 |
| Noyaux tenseurs | 336 | 512 | 328 |
| Cache L1 | 128 Ko (par SM) | 128 Ko (par SM) | 128 Ko (par SM) |
| FP16 Non Tenseur | 38,71 TFLOPS (1:1) | 82,6 | 35,58 TFLOPS (1:1) |
| FP32 non tenseur | 38,71 TFLOPS | 82,6 | 35,58 TFLOPS |
| FP64 non tenseur | 1 210 GFLOPS (1:32) | 556,0 GFLOPS (1:64) | |
| Peak FP16 Tensor TFLOPS avec accumulation FP16 | 154,8/309,6 | 330,3/660,6 | 142/284 |
| Peak FP16 Tensor TFLOPS avec accumulation FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Peak BF16 Tenseur TFLOPS avec FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Tenseur Peak TF32 TFLOPS | 77,4/154,8 | 82,6/165,2 | 35,6/71 |
| Tenseur Peak INT8 TOPS | 309,7/619,4 | 660,6/1321,2 | 284/568 |
| Tenseur Peak INT4 TOPS | 619,3/1238,6 | 1321.2/2642.4 | 568/1136 |
| Cache L2 | 6 Mo | 72 Mo | 6 Mo |
| Bus mémoire | 384 bits | 384 bits | 384 bits |
| TMU | 336 | 512 | 328 |
| ROP | 112 | 176 | 112 |
| Nombre SM | 84 | 128 | 82 |
| Cœurs RT | 84 | 128 | 82 |
Ici, nous pouvons voir que FLOPS est spécifiquement mentionné pour les opérations Tensor, ces données nous aideront à comparer les différentes cartes GPU et à sélectionner celle qui convient à notre cas d'utilisation. D'après le tableau, bien que l'A6000 dispose de deux fois la mémoire de 4090, les flops tenseurs et la bande passante mémoire de 4090 sont meilleurs en nombre et donc plus puissants pour l'inférence de grands modèles de langage.
A lire également : Nvidia CUDA en 100 secondes
Conclusion
Dans le domaine en évolution rapide du NLP, l’optimisation des grands modèles linguistiques (LLM) pour les tâches d’inférence est devenue un domaine d’intérêt critique. Comme nous l'avons exploré, l'architecture des GPU joue un rôle central pour atteindre des performances et une efficacité élevées dans ces tâches. Comprendre les composants internes des GPU, tels que les multiprocesseurs de streaming (SM), le cache L2, la bande passante mémoire et la DRAM, est essentiel pour identifier les goulots d'étranglement potentiels dans les processus d'inférence LLM.
La comparaison entre les différentes cartes GPU NVIDIA (RTX A6000, RTX 4090 et RTX 3090) révèle des différences significatives en termes de taille de mémoire, de bande passante et de nombre de cœurs CUDA et Tensor, entre autres facteurs. Ces distinctions sont cruciales pour prendre des décisions éclairées quant au GPU le mieux adapté à des tâches LLM spécifiques. Par exemple, alors que le RTX A6000 offre une taille de mémoire plus grande, le RTX 4090 excelle en termes de Tensor FLOPS et de bande passante mémoire, ce qui en fait un choix plus puissant pour les tâches d'inférence LLM exigeantes.
L'optimisation de l'inférence LLM nécessite une approche équilibrée qui prend en compte à la fois la capacité de calcul du GPU et les exigences spécifiques de la tâche LLM à accomplir. La sélection du bon GPU implique de comprendre les compromis entre la capacité de mémoire, la puissance de traitement et la bande passante pour garantir que le GPU peut gérer efficacement les pondérations du modèle et effectuer des calculs sans devenir un goulot d'étranglement. Alors que le domaine du NLP continue d'évoluer, rester informé des dernières technologies GPU et de leurs capacités sera primordial pour ceux qui cherchent à repousser les limites de ce qui est possible avec les grands modèles linguistiques.
Terminologie utilisée
- Débit:
En cas d'inférence, le débit est la mesure du nombre de requêtes/invites traitées pendant une période de temps donnée. Le débit est généralement mesuré de deux manières :
- Requêtes par seconde (RPS) :
- RPS mesure le nombre de requêtes d'inférence qu'un modèle peut traiter en une seconde. Une demande d'inférence implique généralement la génération d'une réponse ou d'une prédiction basée sur les données d'entrée.
- Pour la génération LLM, RPS indique la rapidité avec laquelle le modèle peut répondre aux invites ou requêtes entrantes. Des valeurs RPS plus élevées suggèrent une meilleure réactivité et évolutivité pour les applications en temps réel ou quasi-réel.
- Atteindre des valeurs RPS élevées nécessite souvent des stratégies de déploiement efficaces, telles que le regroupement de plusieurs requêtes pour amortir les frais généraux et maximiser l'utilisation des ressources informatiques.
- Jetons par seconde (TPS) :
- TPS mesure la vitesse à laquelle un modèle peut traiter et générer des jetons (mots ou sous-mots) lors de la génération de texte.
- Dans le contexte de la génération LLM, TPS reflète le débit du modèle en termes de génération de texte. Il indique la rapidité avec laquelle le modèle peut produire des réponses cohérentes et significatives.
- Des valeurs TPS plus élevées impliquent une génération de texte plus rapide, permettant au modèle de traiter davantage de données d'entrée et de générer des réponses plus longues dans un laps de temps donné.
- Atteindre des valeurs TPS élevées implique souvent d'optimiser l'architecture du modèle, de paralléliser les calculs et de tirer parti d'accélérateurs matériels tels que les GPU pour accélérer la génération de jetons.
- Latence:
La latence dans les LLM fait référence au délai entre l'entrée et la sortie pendant l'inférence. Minimiser la latence est essentiel pour améliorer l'expérience utilisateur et permettre des interactions en temps réel dans les applications tirant parti des LLM. Il est essentiel de trouver un équilibre entre débit et latence en fonction du service que nous devons fournir. Une faible latence est souhaitable pour les cas tels que les chatbots/copilotes d'interaction en temps réel, mais n'est pas nécessaire pour les cas de traitement de données en masse comme le retraitement des données internes.
En savoir plus sur les techniques avancées pour améliorer le débit LLM ici.