
Libérer le potentiel de l’IA dans le scraping de sites Web : un aperçu
Publié: 2024-02-02Aujourd'hui, le web scraping est passé d'une activité de programmation de niche à un outil commercial essentiel. Initialement, le scraping était un processus manuel, les individus copiant les données des pages Web. L’évolution de la technologie a introduit des scripts automatisés capables d’extraire les données plus efficacement, bien que de manière grossière.
À mesure que les sites Web devenaient plus avancés, les techniques de scraping ont également progressé, s'adaptant à des structures complexes et résistant aux mesures anti-scraping. Les progrès de l’IA et de l’apprentissage automatique ont propulsé le web scraping dans des territoires inexplorés, permettant une compréhension contextuelle et des approches adaptables qui imitent les comportements de navigation humains. Cette progression continue façonne la manière dont les organisations exploitent les données Web à grande échelle et avec une sophistication sans précédent.
L'émergence de l'IA dans le Web Scraping

Source de l'image : https://www.scrapehero.com/
L’impact de l’intelligence artificielle (IA) sur le web scraping ne peut être surestimé ; cela a complètement changé le paysage, rendant le processus plus efficace. Fini l’époque des configurations manuelles laborieuses et de la vigilance constante pour s’adapter aux structures changeantes des sites Web.
Aujourd’hui, grâce à l’IA, les web scrapers sont devenus des outils intuitifs capables d’apprendre à partir de modèles et de s’adapter de manière autonome aux changements structurels sans surveillance humaine constante. Cela signifie qu'ils peuvent saisir le contexte des données, discerner ce qui est pertinent avec une précision remarquable et laisser de côté ce qui est superflu.
Cette méthode plus intelligente et plus flexible a transformé le processus d'extraction de données, fournissant aux industries les outils nécessaires pour prendre des décisions plus éclairées, fondées sur une qualité de données de premier ordre. À mesure que la technologie de l’IA progresse, son intégration dans les outils de web scraping est sur le point d’établir de nouvelles normes, modifiant fondamentalement la manière dont nous collectons des informations sur le Web.
Considérations éthiques et juridiques dans le scraping Web moderne
À mesure que le web scraping évolue avec les progrès de l’IA, les implications éthiques et juridiques deviennent plus complexes. Les scrapers Web doivent naviguer :
- Lois sur la confidentialité des données : les développeurs de Scraper doivent comprendre les législations telles que le RGPD et le CCPA pour éviter les violations juridiques impliquant des données personnelles.
- Conformité aux conditions de service : Le respect des conditions de service d'un site Web est crucial ; le grattage contraire à celles-ci peut conduire à des litiges ou à un refus d'accès.
- Matériel protégé par le droit d'auteur : le contenu obtenu ne doit pas enfreindre les droits d'auteur, ce qui soulève des inquiétudes quant à la distribution et à l'utilisation des données récupérées.
- Norme d'exclusion des robots : l'adhésion au fichier robots.txt des sites Web indique une conduite éthique en honorant les préférences de scraping du propriétaire du site.
- Consentement de l'utilisateur : Lorsque des données personnelles sont impliquées, s'assurer que le consentement de l'utilisateur a été obtenu préserve l'intégrité éthique.
- Transparence : une communication claire concernant l'intention et la portée des opérations de scraping favorise un environnement de confiance et de responsabilité.
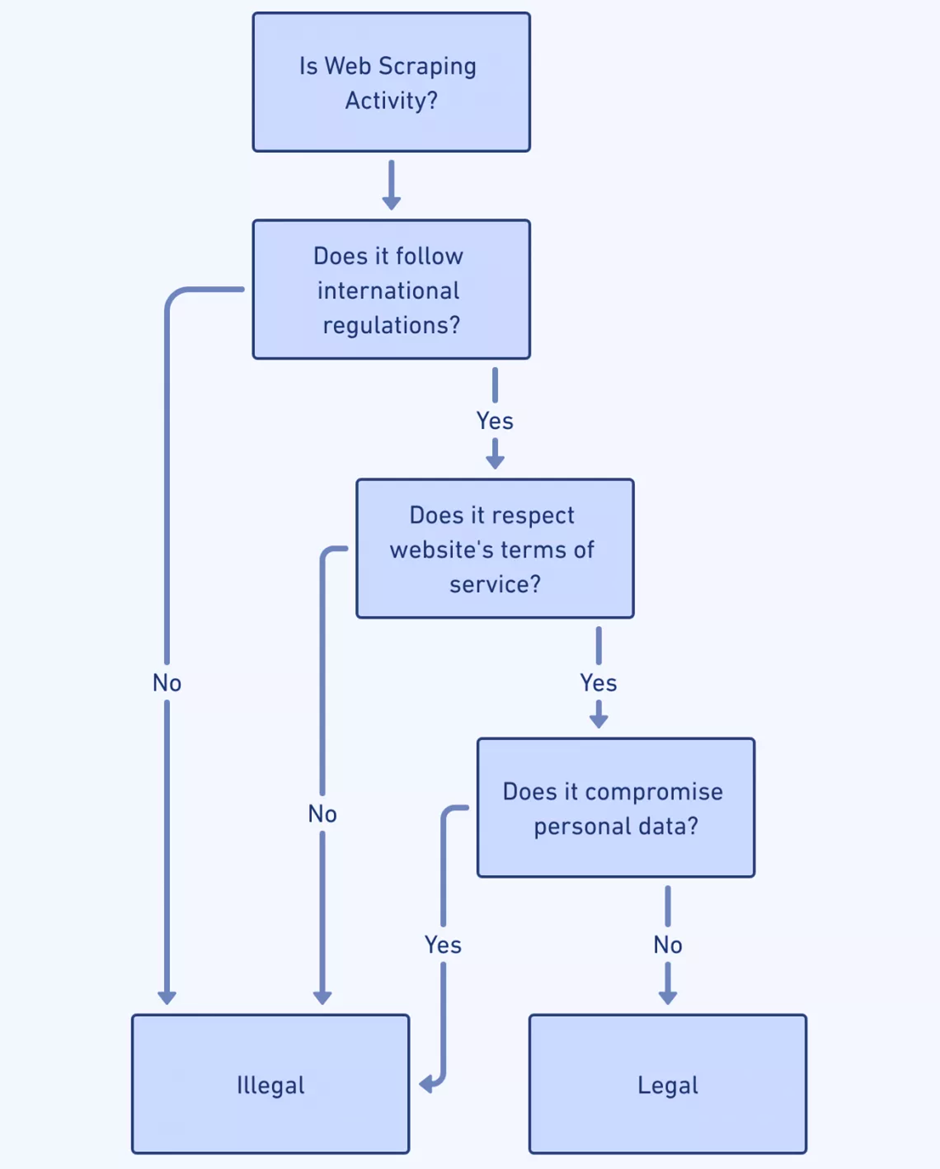
Source de l'image : https://scrape-it.cloud/
Naviguer dans ces considérations nécessite de la vigilance et un engagement envers des pratiques éthiques.

Avancées dans les algorithmes d’IA pour une extraction améliorée des données
Dernièrement, nous avons observé une évolution notable des algorithmes d’IA, remodelant considérablement le paysage des capacités d’extraction de données. Les modèles avancés d’apprentissage automatique, démontrant une capacité améliorée à déchiffrer des modèles complexes, ont élevé la précision de l’extraction de données à des niveaux sans précédent.
Les progrès du traitement du langage naturel (NLP) ont approfondi la compréhension contextuelle, facilitant non seulement l'extraction d'informations pertinentes, mais permettant également l'interprétation de nuances et de sentiments sémantiques subtils.
L'émergence des réseaux de neurones, en particulier des réseaux de neurones convolutifs (CNN), a déclenché une révolution dans l'extraction de données d'images. Cette percée permet à l’intelligence artificielle non seulement de reconnaître, mais également de classer le contenu visuel provenant de la vaste étendue d’Internet.
De plus, l’apprentissage par renforcement (RL) a introduit un nouveau paradigme, dans lequel les outils d’IA affinent les stratégies de scraping optimales au fil du temps, améliorant ainsi leur efficacité opérationnelle. L'intégration de ces algorithmes dans les outils de web scraping a abouti à :
- Interprétation et analyse sophistiquées des données
- Adaptabilité améliorée à diverses structures Web
- Besoin réduit d’intervention humaine pour des tâches complexes
- Efficacité améliorée dans la gestion de l’extraction de données à grande échelle
Surmonter les obstacles : CAPTCHA, contenu dynamique et qualité des données
La technologie de web scraping doit surmonter plusieurs obstacles :
- CAPTCHA : les grattoirs de sites Web basés sur l'IA utilisent désormais des algorithmes avancés de reconnaissance d'images et d'apprentissage automatique pour résoudre les CAPTCHA avec une plus grande précision, permettant ainsi un accès sans intervention humaine.
- Contenu dynamique : les scrapers de sites Web IA sont conçus pour interpréter JavaScript et AJAX qui génèrent du contenu dynamique, garantissant ainsi que les données sont capturées à partir d'applications Web aussi efficacement qu'à partir de pages statiques.

Source de l'image : PromptCloud
- Qualité des données : L'introduction de l'IA a apporté des améliorations dans l'identification et la classification des données. Il s’agit de garantir que les informations collectées sont pertinentes et de haute qualité, réduisant ainsi le besoin de nettoyage et de vérification manuels. Les scrapers de sites Web IA apprennent continuellement à faire la distinction entre le bruit et les données précieuses, affinant ainsi leur processus d'extraction de données.
Fusion de l'IA avec l'analyse du Big Data dans le Web Scraping
L'intégration de l'intelligence artificielle (IA) avec l'analyse du Big Data représente un bond en avant transformateur dans le domaine du web scraping. Dans cette intégration :
- Des algorithmes d’IA sont déployés pour interpréter et analyser de vastes ensembles de données exploités grâce au scraping, obtenant ainsi des informations à des vitesses sans précédent.
- Les éléments d’apprentissage automatique au sein de l’IA peuvent améliorer encore l’extraction de données, en apprenant à identifier et à extrapoler efficacement des modèles et des informations.
- L’analyse Big Data peut ensuite traiter ces informations, fournissant ainsi aux entreprises des informations exploitables.
- De plus, l’IA aide à nettoyer et à structurer les données, une étape cruciale pour exploiter efficacement l’analyse du Big Data.
- Cette synergie entre l'IA et l'analyse du Big Data dans le web scraping est cruciale pour la prise de décision urgente et le maintien des avantages concurrentiels.
Le paysage futur : prévisions et potentiel pour les grattoirs de sites Web IA
Le domaine du scraping de sites Web par l’IA se situe à un seuil de transformation important. Les prédictions indiquent :
- Capacités cognitives améliorées, permettant aux scrapers d’interpréter des données complexes avec une compréhension humaine.
- Intégration avec d'autres technologies d'IA comme le traitement du langage naturel pour une extraction de données plus nuancée.
- Des scrapers auto-apprenants qui affinent leurs méthodes en fonction des taux de réussite, créant ainsi des protocoles de collecte de données plus efficaces.
- Meilleur respect des normes éthiques et juridiques grâce à des algorithmes de conformité avancés.
- Collaboration entre les scrapers IA et les technologies blockchain pour des transactions de données sécurisées et transparentes.
Contactez-nous dès aujourd'hui à sales@promptcloud.com pour découvrir comment notre technologie de pointe de grattage de sites Web par IA peut révolutionner vos processus d'extraction de données et propulser votre organisation vers de nouveaux sommets !