
Comment importer des données dans BigQuery avec R et Python
Publié: 2023-06-06Le monde de l'analyse Web continue de se précipiter vers la date fatidique du 1er juillet, date à laquelle Universal Analytics cesse de traiter les données et est remplacé par Google Analytics 4 (GA4). L'un des principaux changements est que dans GA4, vous ne pouvez conserver les données sur la plate-forme que pendant 14 mois maximum. Il s'agit d'un changement majeur par rapport à UA, mais en échange de cela, vous pouvez transférer gratuitement des données GA4 dans BigQuery, jusqu'à une certaine limite.
BigQuery est une ressource extrêmement utile pour le stockage de données au-delà de GA4. Comme il devient plus important que jamais dans quelques mois, c'est le moment idéal pour commencer à l'utiliser pour tous vos besoins de stockage de données. Souvent, il sera préférable de manipuler les données d'une manière ou d'une autre avant de les télécharger. Pour cela, nous vous recommandons d'utiliser un script écrit en R ou en Python, surtout si ce genre de manipulation doit être répété. Vous pouvez également télécharger des données dans BigQuery directement à partir de ces scripts, et c'est exactement ce que ce blog va vous guider.
Importer dans BigQuery à partir de R
R est un langage extrêmement puissant pour la science des données et le plus facile à utiliser pour importer des données dans BigQuery. La première étape consiste à importer toutes les bibliothèques nécessaires. Pour ce tutoriel, nous aurons besoin des librairies suivantes :
library(googleAuthR)
library(bigQueryR)
Si vous n'avez jamais utilisé ces bibliothèques auparavant, exécutez install.packages(<PACKAGE NAME>) dans la console pour les installer.
Ensuite, nous devons nous attaquer à ce qui est souvent la partie la plus délicate et la plus frustrante du travail avec les API : l'autorisation. Heureusement, avec R, c'est relativement simple. Vous aurez besoin d'un fichier JSON contenant les identifiants d'autorisation. Cela peut être trouvé dans Google Cloud Console, au même endroit où se trouve BigQuery. Tout d'abord, accédez à Google Cloud Console et cliquez sur "API et services".
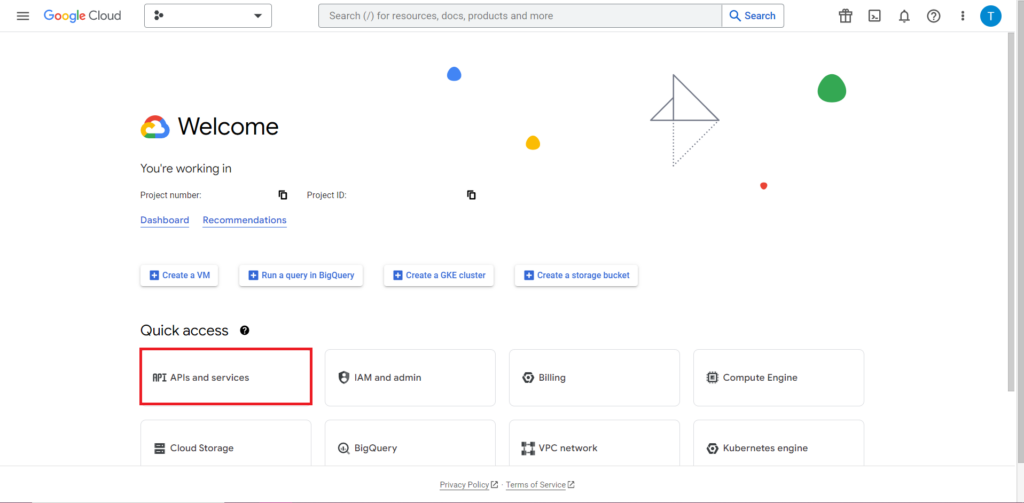
Ensuite, cliquez sur "Identifiants" dans la barre latérale.
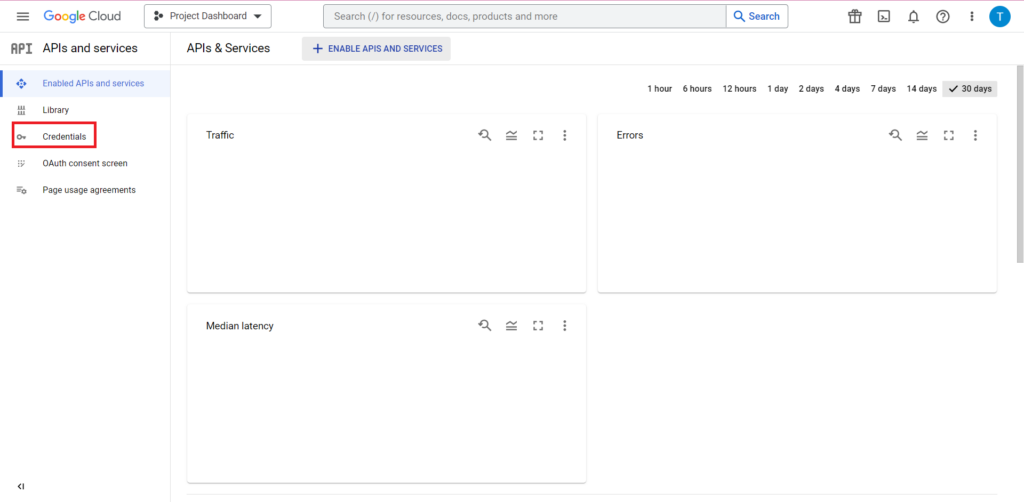
Sur la page Informations d'identification, vous pouvez afficher vos clés d'API existantes, vos identifiants client OAuth 2.0 et vos comptes de service. Vous aurez besoin d'un ID client OAuth 2.0 pour cela, alors cliquez sur le bouton de téléchargement à la toute fin de la ligne correspondante pour votre ID, ou créez un nouvel ID en cliquant sur "Créer des informations d'identification" en haut de la page. Assurez-vous que votre ID est autorisé à afficher et à modifier le projet BigQuery concerné. Pour ce faire, ouvrez la barre latérale, passez la souris sur "IAM et administrateur" et cliquez sur "IAM". Sur cette page, vous pouvez accorder à votre compte de service l'accès au projet concerné en utilisant le bouton "Accorder l'accès" en haut de la page.
Avec le fichier JSON obtenu et enregistré, vous pouvez lui transmettre le chemin avec la fonction gar_set_client() pour définir vos informations d'identification. Le code complet pour l'autorisation est ci-dessous :
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Évidemment, vous voudrez remplacer le chemin dans la fonction gar_set_client() par le chemin de votre propre fichier JSON et insérer l'adresse e-mail que vous utilisez pour accéder à BigQuery dans la fonction bqr_auth().
Une fois l'autorisation configurée, nous avons besoin de certaines données à importer dans BigQuery. Nous devrons mettre ces données dans une base de données. Pour les besoins de cet article, je vais créer des données fictives avec un certain nombre d'emplacements et de nombres de ventes, mais très probablement, vous lirez des données réelles à partir d'un fichier .csv ou d'une feuille de calcul. Pour lire les données d'un fichier .csv, il suffit d'utiliser la fonction read.csv() en passant en argument le chemin du fichier :
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Alternativement, si vos données sont stockées dans une feuille de calcul, votre méthode variera en fonction de l'emplacement de cette feuille de calcul. Si votre feuille de calcul est stockée dans Google Sheets, vous pouvez lire ses données dans R à l'aide de la bibliothèque googlesheets4 :
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Comme auparavant, si vous n'avez jamais utilisé ce package auparavant, vous devrez exécuter install.packages("googlesheets4") dans la console avant d'exécuter votre code.
Si votre feuille de calcul est dans Excel, vous devrez utiliser la bibliothèque readxl, qui fait partie de la bibliothèque tidyverse - quelque chose que je recommande d'utiliser. Il contient un grand nombre de fonctions qui facilitent grandement la manipulation des données dans R :
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
Et encore une fois, assurez-vous d'exécuter install.package ("tidyverse") si vous ne l'avez pas déjà fait !
La dernière étape consiste à importer les données dans BigQuery. Pour cela, vous aurez besoin d'un emplacement dans BigQuery pour l'importer. Votre table sera située dans un ensemble de données, qui sera situé dans un projet, et vous aurez besoin des noms de ces trois éléments au format suivant :
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
Dans mon cas, cela signifie que mon code lit:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
Si votre table n'existe pas encore, ne vous inquiétez pas, le code la créera pour vous. N'oubliez pas d'insérer les noms de votre projet, de votre jeu de données et de votre table dans le code ci-dessus (entre guillemets) et assurez-vous de télécharger la bonne trame de données ! Une fois cela fait, vous devriez voir vos données dans BigQuery, comme ci-dessous :

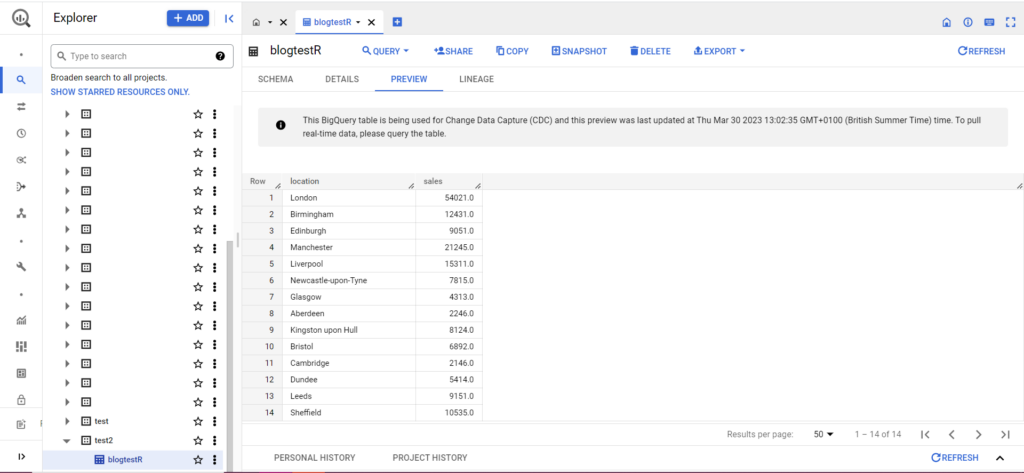
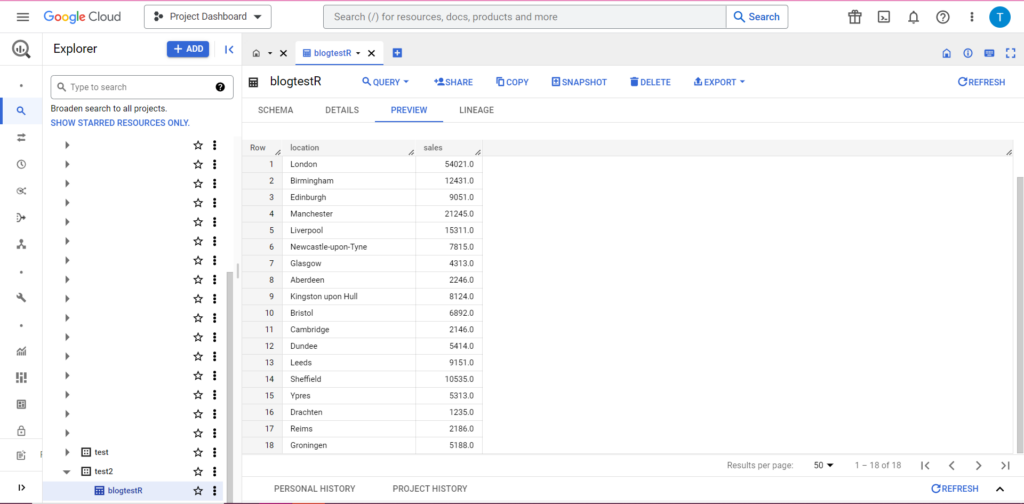
Enfin, imaginons que vous disposiez de données supplémentaires que vous souhaitez ajouter à BigQuery. Par exemple, dans mes données ci-dessus, imaginons que j'ai oublié d'inclure quelques emplacements du continent et que je souhaite les importer dans BigQuery, mais je ne souhaite pas écraser les données existantes. Pour cela, bqr_upload_data a un paramètre appelé writeDisposition. writeDisposition a deux paramètres, "WRITE_TRUNCATE" et "WRITE_APPEND". Le premier dit à bqr_upload_data() d'écraser les données existantes dans la table, tandis que le second lui dit d'ajouter les nouvelles données. Ainsi, pour uploader ces nouvelles données, j'écrirai :
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
Et bien sûr, dans BigQuery, nous pouvons voir que nos données ont de nouveaux colocataires :
Importer dans BigQuery à partir de Python
En Python, les choses sont un peu différentes. Encore une fois, nous devrons importer certains packages, commençons donc par ceux-ci :
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
L'autorisation est compliquée. Encore une fois, nous aurons besoin d'un fichier JSON contenant les informations d'identification. Comme ci-dessus, nous allons accéder à Google Cloud Console et cliquer sur "API et services", puis sur "Identifiants" dans la barre latérale. Cette fois, en bas de la page, il y aura une section intitulée "Comptes de service".
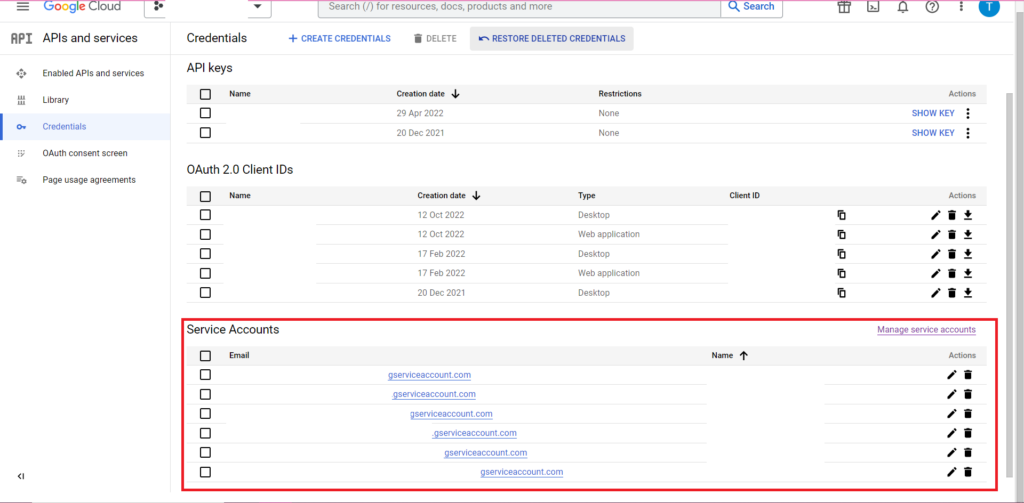
Là, vous pouvez soit télécharger la clé de votre compte de service, soit en cliquant sur "Gérer le compte de service", vous pouvez créer une nouvelle clé ou un nouveau compte de service pour lequel vous pouvez télécharger les informations d'identification.
Vous devrez ensuite vous assurer que votre compte de service est autorisé à accéder à votre projet BigQuery et à le modifier. Encore une fois, accédez à la page IAM sous "IAM & Admin" dans la barre latérale, et là, vous pouvez accorder à votre compte de service l'accès au projet concerné en utilisant le bouton "Accorder l'accès" en haut de la page.
Dès que vous avez réglé cela, vous pouvez écrire le code d'autorisation :
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Ensuite, vous devrez mettre vos données dans un dataframe. Les dataframes appartiennent au package pandas et sont très simples à créer. Pour lire à partir d'un CSV, suivez cet exemple :
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Évidemment, vous devrez remplacer le chemin ci-dessus par celui de votre propre fichier CSV. Pour lire à partir d'un fichier Excel, suivez cet exemple :
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
La lecture à partir de Google Sheets est délicate et nécessite un autre cycle d'autorisation. Nous devrons importer de nouveaux packages et utiliser le fichier d'informations d'identification JSON que nous avons récupéré lors du didacticiel R ci-dessus. Vous pouvez suivre ce code pour autoriser et lire vos données :
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Une fois que vous avez vos données dans votre dataframe, il est temps de les importer à nouveau dans BigQuery ! Vous pouvez le faire en suivant ce modèle :
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Pour un exemple, voici le code que je viens d'écrire pour télécharger les données que j'ai faites plus tôt :
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Une fois cela fait, les données devraient apparaître immédiatement dans BigQuery !
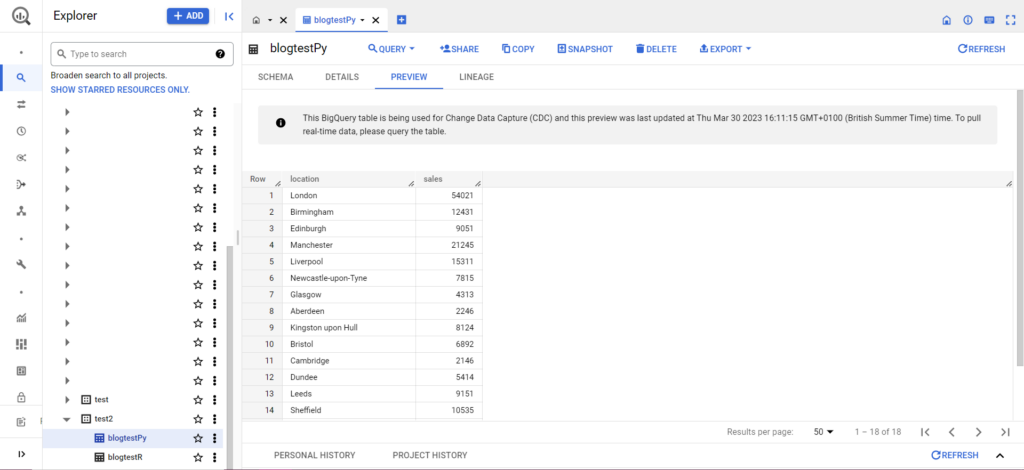
Il y a beaucoup plus que vous pouvez faire avec ces fonctions une fois que vous les maîtrisez. Si vous souhaitez mieux contrôler votre configuration analytique, Semetrical est là pour vous aider ! Consultez notre blog pour plus d'informations sur la façon de tirer le meilleur parti de vos données. Ou, pour plus d'assistance sur tout ce qui concerne l'analyse, rendez-vous sur Web Analytics pour découvrir comment nous pouvons vous aider.