
Robots d'exploration Web – Un guide complet
Publié: 2023-12-12Exploration Web
L'exploration du Web, un processus fondamental dans le domaine de l'indexation du Web et de la technologie des moteurs de recherche, fait référence à la navigation automatisée sur le World Wide Web par un logiciel appelé robot d'exploration du Web. Ces robots d'exploration, parfois appelés araignées ou robots, naviguent systématiquement sur le Web pour recueillir des informations sur les sites Web. Ce processus permet la collecte et l'indexation des données, ce qui est crucial pour que les moteurs de recherche fournissent des résultats de recherche à jour et pertinents.
Fonctions clés de l'exploration du Web :
- Indexation du contenu : les robots d'exploration Web analysent les pages Web et indexent leur contenu, le rendant ainsi consultable. Ce processus d'indexation implique l'analyse du texte, des images et d'autres contenus d'une page pour comprendre son sujet.
- Analyse des liens : les robots suivent les liens d'une page Web à une autre. Cela aide non seulement à découvrir de nouvelles pages Web, mais également à comprendre les relations et la hiérarchie entre les différentes pages Web.
- Détection des mises à jour de contenu : en revisitant régulièrement les pages Web, les robots d'exploration peuvent détecter les mises à jour et les modifications, garantissant ainsi que le contenu indexé reste à jour.
Notre guide étape par étape pour créer un robot d'exploration Web vous aidera à mieux comprendre le processus d'exploration Web.
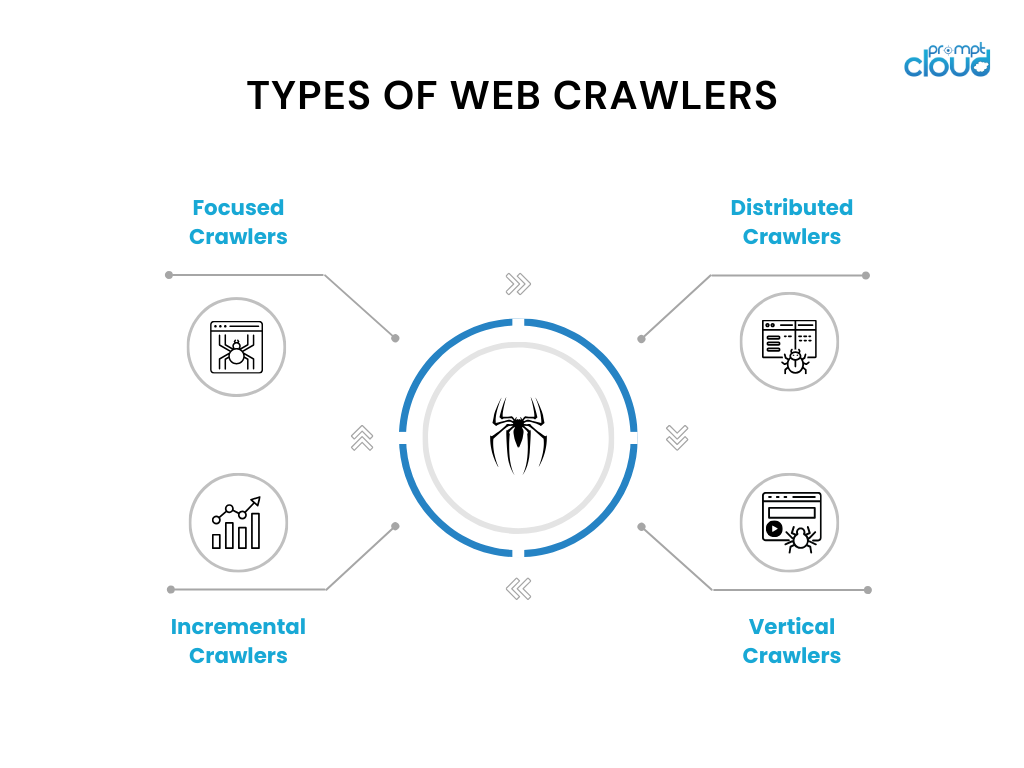
Qu'est-ce qu'un robot d'exploration Web
Un robot d'exploration Web, également connu sous le nom d'araignée ou de robot, est un logiciel automatisé qui parcourt systématiquement le World Wide Web à des fins d'indexation Web. Sa fonction principale est d'analyser et d'indexer le contenu des pages Web, qui comprend du texte, des images et d'autres médias. Les robots d'exploration Web partent d'un ensemble connu de pages Web et suivent les liens présents sur ces pages pour découvrir de nouvelles pages, agissant un peu comme une personne naviguant sur le Web. Ce processus permet aux moteurs de recherche de rassembler et de mettre à jour leurs données, garantissant ainsi que les utilisateurs reçoivent des résultats de recherche actuels et complets. Le fonctionnement efficace des robots d’exploration Web est essentiel pour maintenir accessible et consultable le vaste référentiel en constante évolution d’informations en ligne.
Comment fonctionne un robot d'exploration Web
Les robots d'exploration Web fonctionnent en parcourant systématiquement Internet pour collecter et indexer le contenu d'un site Web, un processus crucial pour les moteurs de recherche. Ils partent d'un ensemble d'URL connues et accèdent à ces pages Web pour récupérer du contenu. Lors de l'analyse des pages, ils identifient tous les hyperliens et les ajoutent à la liste des URL à visiter ensuite, cartographiant ainsi efficacement la structure du Web. Chaque page visitée est traitée pour extraire des informations pertinentes, telles que du texte, des images et des métadonnées, qui sont ensuite stockées dans une base de données. Ces données deviennent la base de l'index d'un moteur de recherche, lui permettant de fournir des résultats de recherche rapides et pertinents.
Les robots d'exploration Web doivent fonctionner dans le cadre de certaines contraintes, telles que suivre les règles définies dans les fichiers robots.txt par les propriétaires de sites Web et éviter de surcharger les serveurs, garantissant ainsi un processus d'exploration éthique et efficace. Alors qu'ils parcourent des milliards de pages Web, ces robots d'exploration sont confrontés à des défis tels que la gestion du contenu dynamique, la gestion des pages en double et la mise à jour des dernières technologies Web, ce qui rend leur rôle dans l'écosystème numérique à la fois complexe et indispensable. Voici un article détaillé sur le fonctionnement des robots d'exploration Web.
Robot d'exploration Web Python
Python, réputé pour sa simplicité et sa lisibilité, est un langage de programmation idéal pour créer des robots d'exploration Web. Son riche écosystème de bibliothèques et de frameworks simplifie le processus d'écriture de scripts qui naviguent, analysent et extraient des données du Web. Voici les aspects clés qui font de Python un choix incontournable pour l’exploration Web :
Bibliothèques Python clés pour l'exploration du Web :
- Requêtes : Cette bibliothèque est utilisée pour effectuer des requêtes HTTP vers des pages Web. Il est simple à utiliser et peut gérer différents types de requêtes, essentielles pour accéder au contenu d'une page Web.
- Beautiful Soup : Spécialisé dans l'analyse de documents HTML et XML, Beautiful Soup permet d'extraire facilement les données des pages Web, ce qui simplifie la navigation dans la structure des balises du document.
- Scrapy : Framework d'exploration Web open source, Scrapy fournit un package complet pour l'écriture de robots d'exploration Web. Il gère les requêtes, l’analyse des réponses et l’extraction des données de manière transparente.
Avantages de l'utilisation de Python pour l'exploration Web :
- Facilité d'utilisation : la syntaxe simple de Python le rend accessible même à ceux qui débutent en programmation.
- Support communautaire robuste : une grande communauté et une richesse de documentation aident au dépannage et à l'amélioration des fonctionnalités du robot d'exploration.
- Flexibilité et évolutivité : les robots d'exploration Python peuvent être aussi simples ou complexes que nécessaire, s'adaptant aux petits comme aux grands projets.
Exemple de robot d'exploration Web Python de base :
demandes d'importation

à partir de bs4 importer BeautifulSoup
# Définir l'URL à explorer
url = « http://exemple.com »
# Envoyer une requête HTTP à l'URL
réponse = requêtes.get (url)
# Analyser le contenu HTML de la page
soupe = BeautifulSoup(response.text, 'html.parser')
# Extraire et imprimer tous les hyperliens
pour le lien dans soup.find_all('a'):
print(lien.get('href'))
Ce script simple montre le fonctionnement de base d'un robot d'exploration Web Python. Il récupère le contenu HTML d'une page Web à l'aide de requêtes, l'analyse avec Beautiful Soup et extrait tous les hyperliens.
Les robots d'exploration Web Python se distinguent par leur facilité de développement et leur efficacité dans l'extraction de données.
Qu'il s'agisse d'analyse SEO, d'exploration de données ou de marketing numérique, Python fournit une base solide et flexible pour les tâches d'exploration Web, ce qui en fait un excellent choix pour les programmeurs et les data scientists.
Cas d'utilisation de l'exploration du Web
L'exploration du Web a un large éventail d'applications dans différents secteurs, reflétant sa polyvalence et son importance à l'ère numérique. Voici quelques-uns des principaux cas d’utilisation :
Indexation des moteurs de recherche
L'utilisation la plus connue des robots d'exploration Web est celle des moteurs de recherche tels que Google, Bing et Yahoo pour créer un index consultable du Web. Les robots analysent les pages Web, indexent leur contenu et les classent en fonction de divers algorithmes, les rendant ainsi consultables par les utilisateurs.
Exploration et analyse de données
Les entreprises utilisent des robots d'exploration Web pour collecter des données sur les tendances du marché, les préférences des consommateurs et la concurrence. Les chercheurs utilisent des robots d'exploration pour regrouper des données provenant de plusieurs sources à des fins d'études universitaires.
Surveillance du référencement
Les webmasters utilisent des robots d'exploration pour comprendre comment les moteurs de recherche visualisent leurs sites Web, contribuant ainsi à optimiser la structure, le contenu et les performances du site. Ils sont également utilisés pour analyser les sites Web des concurrents afin de comprendre leurs stratégies de référencement.
Agrégation de contenu
Les robots d'exploration sont utilisés par les plateformes d'actualités et d'agrégation de contenu pour rassembler des articles et des informations provenant de diverses sources. Regrouper le contenu des plateformes de médias sociaux pour suivre les tendances, les sujets populaires ou les mentions spécifiques.
Commerce électronique et comparaison de prix
Les robots aident à suivre les prix des produits sur différentes plateformes de commerce électronique, contribuant ainsi à des stratégies de tarification compétitives. Ils sont également utilisés pour cataloguer les produits de divers sites de commerce électronique sur une seule plateforme.
Annonces immobilières
Les robots rassemblent des annonces immobilières sur divers sites Web immobiliers pour offrir aux utilisateurs une vue consolidée du marché.
Offres d'emploi et recrutement
Regrouper les offres d'emploi de divers sites Web pour fournir une plateforme de recherche d'emploi complète. Certains recruteurs utilisent des robots d'exploration pour parcourir le Web à la recherche de candidats potentiels possédant des qualifications spécifiques.
Formation en apprentissage automatique et en IA
Les robots d'exploration peuvent collecter de grandes quantités de données sur le Web, qui peuvent être utilisées pour entraîner des modèles d'apprentissage automatique dans diverses applications.
Scraping Web et exploration Web
Le web scraping et l'exploration du web sont deux techniques couramment utilisées dans la collecte de données à partir de sites web, mais elles répondent à des objectifs différents et fonctionnent de manière distincte. Comprendre les différences est essentiel pour toute personne impliquée dans l’extraction de données ou l’analyse Web.
Grattage Web
- Définition : Le Web scraping est le processus d'extraction de données spécifiques à partir de pages Web. Il se concentre sur la transformation de données Web non structurées (généralement au format HTML) en données structurées pouvant être stockées et analysées.
- Extraction de données ciblée : le scraping est souvent utilisé pour collecter des informations spécifiques à partir de sites Web, telles que les prix des produits, les données boursières, les articles de presse, les coordonnées, etc.
- Outils et techniques : Cela implique l'utilisation d'outils ou de programmation (souvent Python, PHP, JavaScript) pour demander une page Web, analyser le contenu HTML et extraire les informations souhaitées.
- Cas d'utilisation : études de marché, surveillance des prix, génération de leads, données pour modèles d'apprentissage automatique, etc.
Exploration Web
- Définition : L'exploration du Web, quant à elle, est le processus de navigation systématique sur le Web pour télécharger et indexer du contenu Web. Il est principalement associé aux moteurs de recherche.
- Indexation et suivi des liens : les robots d'exploration, ou robots, sont utilisés pour visiter un large éventail de pages afin de comprendre la structure et les liens du site. Ils indexent généralement tout le contenu d’une page.
- Automatisation et échelle : l'exploration du Web est un processus plus automatisé, capable de gérer l'extraction de données à grande échelle sur de nombreuses pages Web ou des sites Web entiers.
- Considérations : Les robots doivent respecter les règles fixées par les sites Web, comme celles des fichiers robots.txt, et sont conçus pour naviguer sans surcharger les serveurs Web.
Outils d'exploration du Web
Les outils d'exploration du Web sont des instruments essentiels dans la boîte à outils numérique des entreprises, des chercheurs et des développeurs, offrant un moyen d'automatiser la collecte de données à partir de divers sites Web sur Internet. Ces outils sont conçus pour parcourir systématiquement les pages Web, extraire des informations utiles et les stocker pour une utilisation ultérieure. Voici un aperçu des outils d'exploration Web et de leur importance :
Fonctionnalité : les outils d'exploration Web sont programmés pour naviguer sur les sites Web, identifier les informations pertinentes et les récupérer. Ils imitent le comportement de navigation humain, mais le font à une échelle et à une vitesse beaucoup plus grandes.
Extraction et indexation de données : ces outils analysent les données des pages Web, qui peuvent inclure du texte, des images, des liens et d'autres médias, puis les organisent dans un format structuré. Ceci est particulièrement utile pour créer des bases de données d’informations pouvant être facilement recherchées et analysées.
Personnalisation et flexibilité : de nombreux outils d'exploration Web offrent des options de personnalisation, permettant aux utilisateurs de spécifier quels sites Web explorer, jusqu'où aller dans l'architecture du site et quel type de données extraire.
Cas d'utilisation : ils sont utilisés à diverses fins, telles que l'optimisation des moteurs de recherche (SEO), les études de marché, l'agrégation de contenu, l'analyse concurrentielle et la collecte de données pour des projets d'apprentissage automatique.
Notre récent article fournit un aperçu détaillé des meilleurs outils d'exploration du Web 2024. Consultez l'article pour en savoir plus. Contactez-nous à [email protected] pour des solutions d'exploration Web personnalisées.